| 1 |
A Curriculum-Training-Based Strategy for Distributing Collocation Points
during Physics-Informed Neural Network Training [paper] [poster]
[event]
Münzer,
Marcus*; Bard, Christopher |
| 2 |
A Neural Network Subgrid Model of the Early Stages of Planet Formation
[paper] [poster]
[event]
Pfeil,
Thomas*; Cranmer, Miles; Ho, Shirley; Armitage, Philip; Birnstiel, Tilman;
Klahr, Hubert |
| 3 |
A New Task: Deriving Semantic Class Targets for the Physical Sciences [paper] [poster]
[event]
Bowles,
Micah R* |
| 4 |
A Novel Automatic Mixed Precision Approach For Physics Informed Training
[paper] [poster]
[event]
Xue, Jinze;
Subramaniam, Akshay*; Hoemmen, Mark |
| 5 |
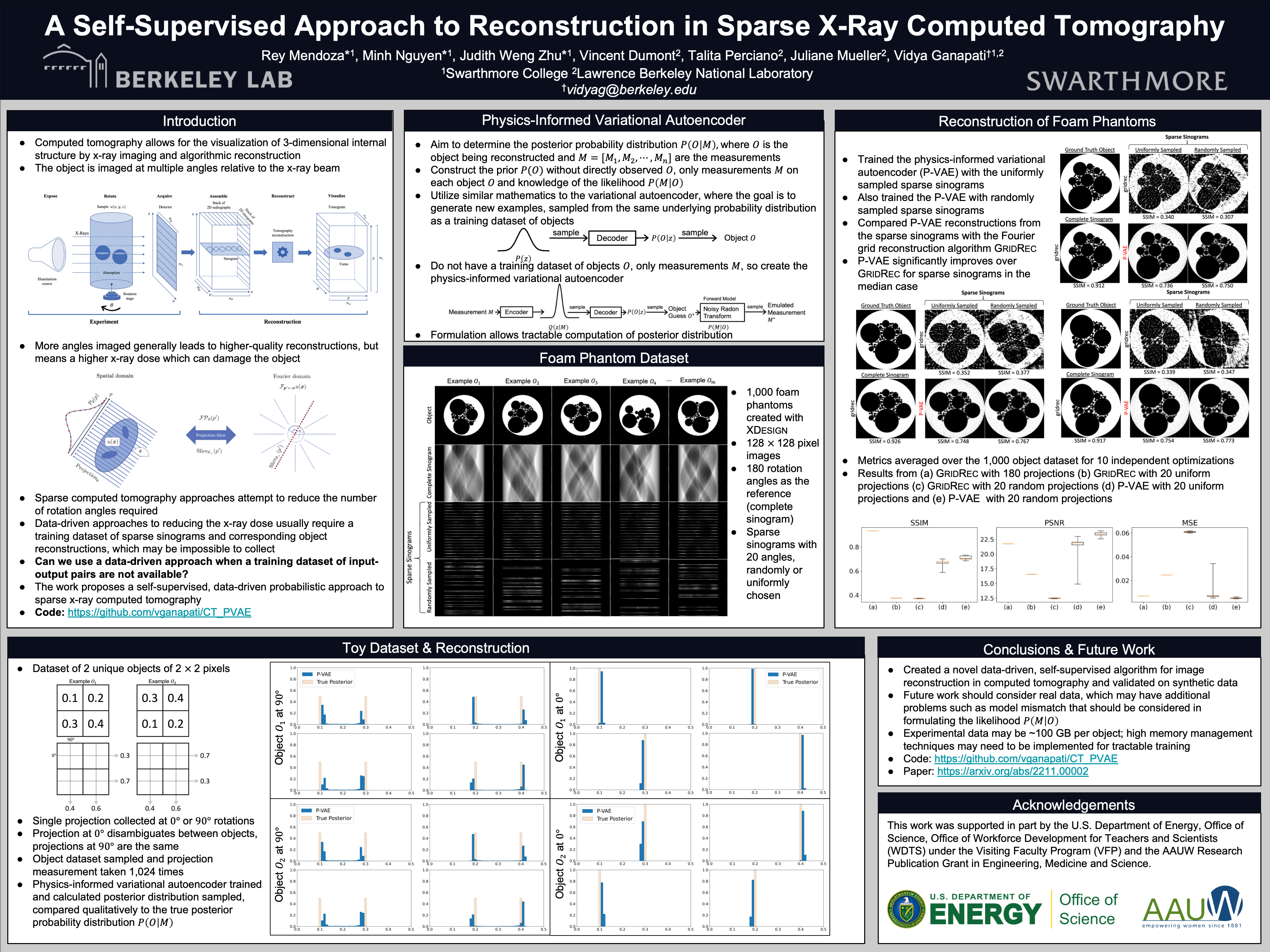
A Self-Supervised Approach to Reconstruction in Sparse X-Ray Computed
Tomography [paper] [poster]
[event]
Mendoza,
Rey; Nguyen, Minh; Weng Zhu, Judith; Perciano, Talita; Dumont, Vincent; Mueller,
Juliane; Ganapati, Vidya* |
| 6 |
A Trust Crisis In Simulation-Based Inference? Your Posterior Approximations
Can Be Unfaithful [paper]
[poster]
[video] [event]
Hermans,
Joeri; Delaunoy, Arnaud*; Rozet, François; Wehenkel, Antoine; Begy, Volodimir;
Louppe, Gilles |
| 7 |
A fast and flexible machine learning approach to data quality monitoring
[paper] [poster]
[event]
Letizia,
Marco*; Grosso, Gaia; Wulzer, Andrea; Zanetti, Marco; Pazzini, Jacopo; Rando,
Marco; Lai, Nicolò |
| 8 |
A hybrid Reduced Basis and Machine-Learning algorithm for building Surrogate
Models: a first application to electromagnetism [paper] [event]
Ribes,
Alejandro*; Persicot, Ruben; Meyer, Lucas T; Ducreux, Jean-Pierre |
| 9 |
A physics-informed search for metric solutions to Ricci flow, their
embeddings, and visualisation [paper] [poster]
[event]
Jain,
Aarjav*; Mishra, Challenger; Lió, Pietro |
| 10 |
A probabilistic deep learning model to distinguish cusps and cores in dwarf
galaxies [paper] [poster]
[event]
Expósito,
Julen*; Huertas-Company, Marc; Di Cintio, Arianna; Brook, Chris; Macciò, Andrea;
Grant, Rob; Arjona, Elena |
| 11 |
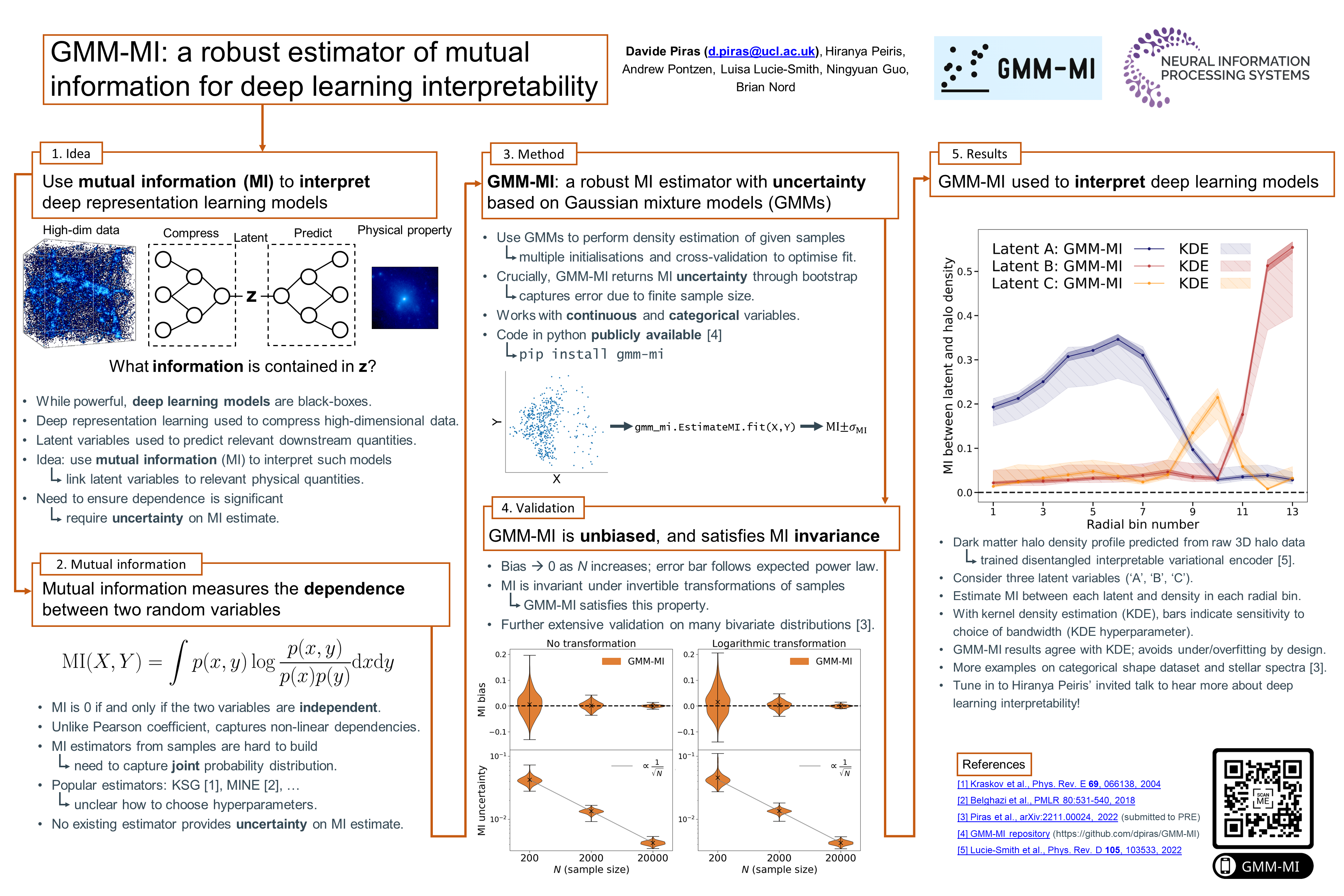
A robust estimator of mutual information for deep learning
interpretability [paper]
[poster]
[video]
[event]
Piras,
Davide*; Peris, Hiranya ; Pontzen, Andrew; Lucie-Smith, Luisa; Nord, Brian; Guo,
Ningyuan (Lillian) |
| 12 |
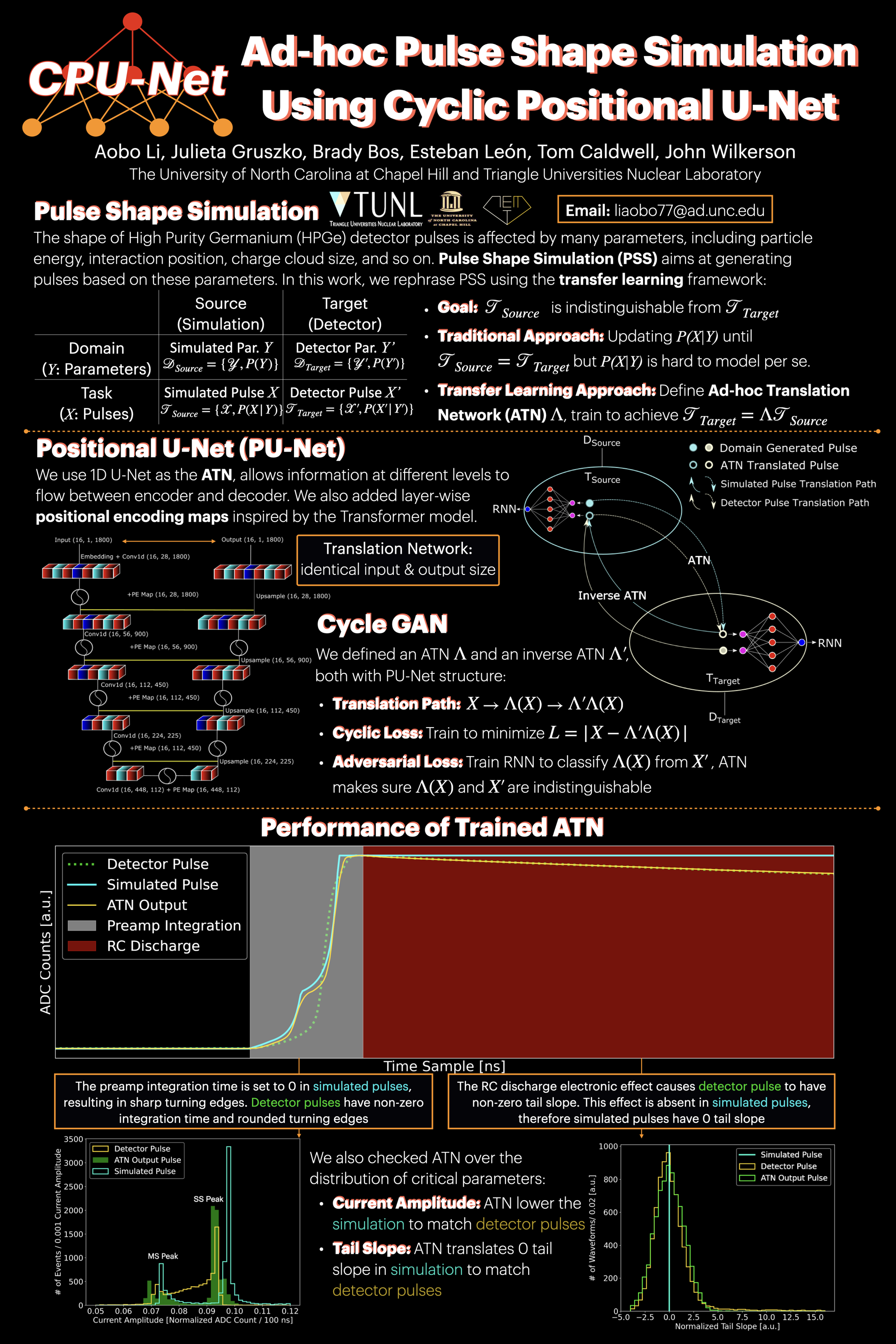
Ad-hoc Pulse Shape Simulation using Cyclic Positional U-Net [paper] [poster]
[event]
Li, Aobo*;
Gruszko, Julieta; Bos, Brady; Caldwell, Thomas; León, Esteban; Wilkerson, John
|
| 13 |
Adaptive Selection of Atomic Fingerprints for High-Dimensional Neural Network
Potentials [paper] [poster]
[event]
Sandberg,
Johannes E*; Devijver, Emilie; Jakse, Noel; Voigtmann, Thomas |
| 14 |
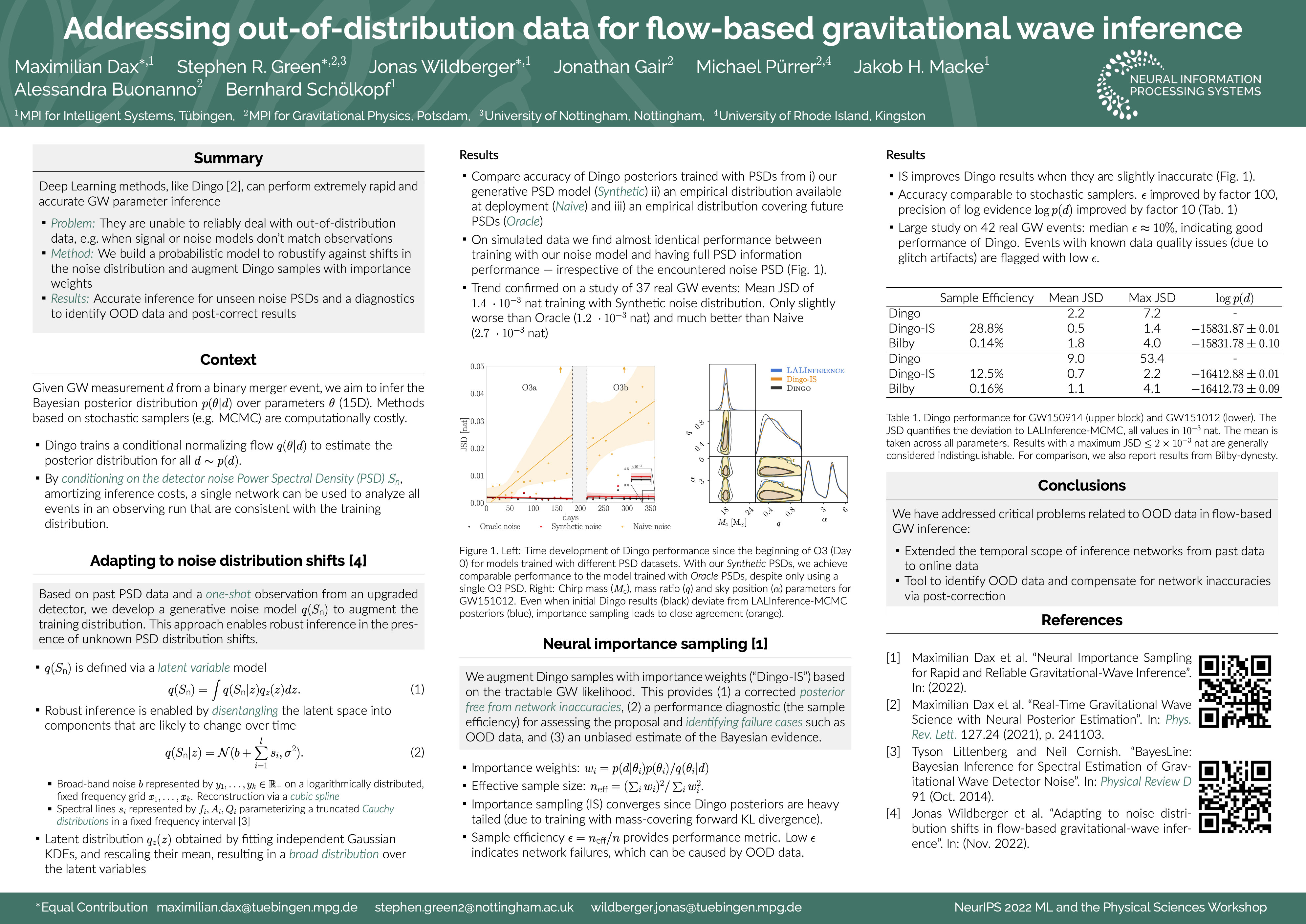
Addressing out-of-distribution data for flow-based gravitational wave
inference [paper] [poster]
[event]
Maximillian,
Dax*; Green, Stephen R; Wildberger, Jonas Bernhard; Gair, Jonathan; Puerrer,
Michael; Macke, Jakob; Buonanno, Alessandra; Schölkopf, Bernhard |
| 15 |
Adversarial Noise Injection for Learned Turbulence Simulations [paper] [poster]
[event]
Su,
Jingtong*; Kempe, Julia; Fielding, Drummond; Tsilivis, Nikolaos; Cranmer, Miles;
Ho, Shirley |
| 16 |
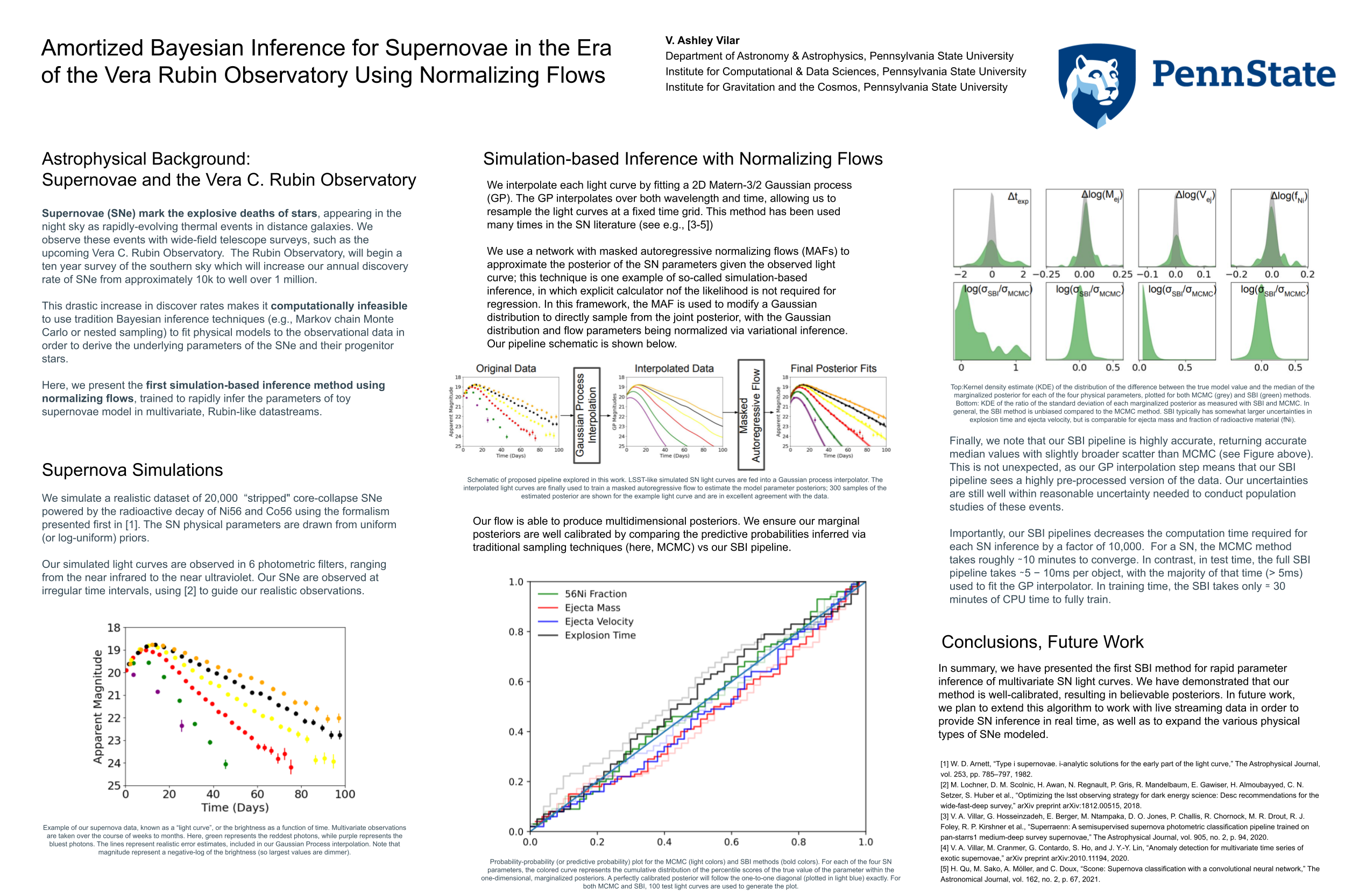
Amortized Bayesian Inference for Supernovae in the Era of the Vera Rubin
Observatory Using Normalizing Flows [paper] [poster]
[event]
Villar,
Victoria A* |
| 17 |
Amortized Bayesian Inference of GISAXS Data with Normalizing Flows [paper] [poster]
[event]
Zhdanov,
Maksim*; Randolph, Lisa; Kluge, Thomas; Nakatsutsumi, Motoaki; Gutt, Christian;
Ganeva, Marina; Hoffmann, Nico |
| 18 |
Anomaly Detection with Multiple Reference Datasets in High Energy Physics
[paper] [poster]
[event]
Chen,
Mayee*; Nachman, Benjamin; Sala, Frederic |
| 19 |
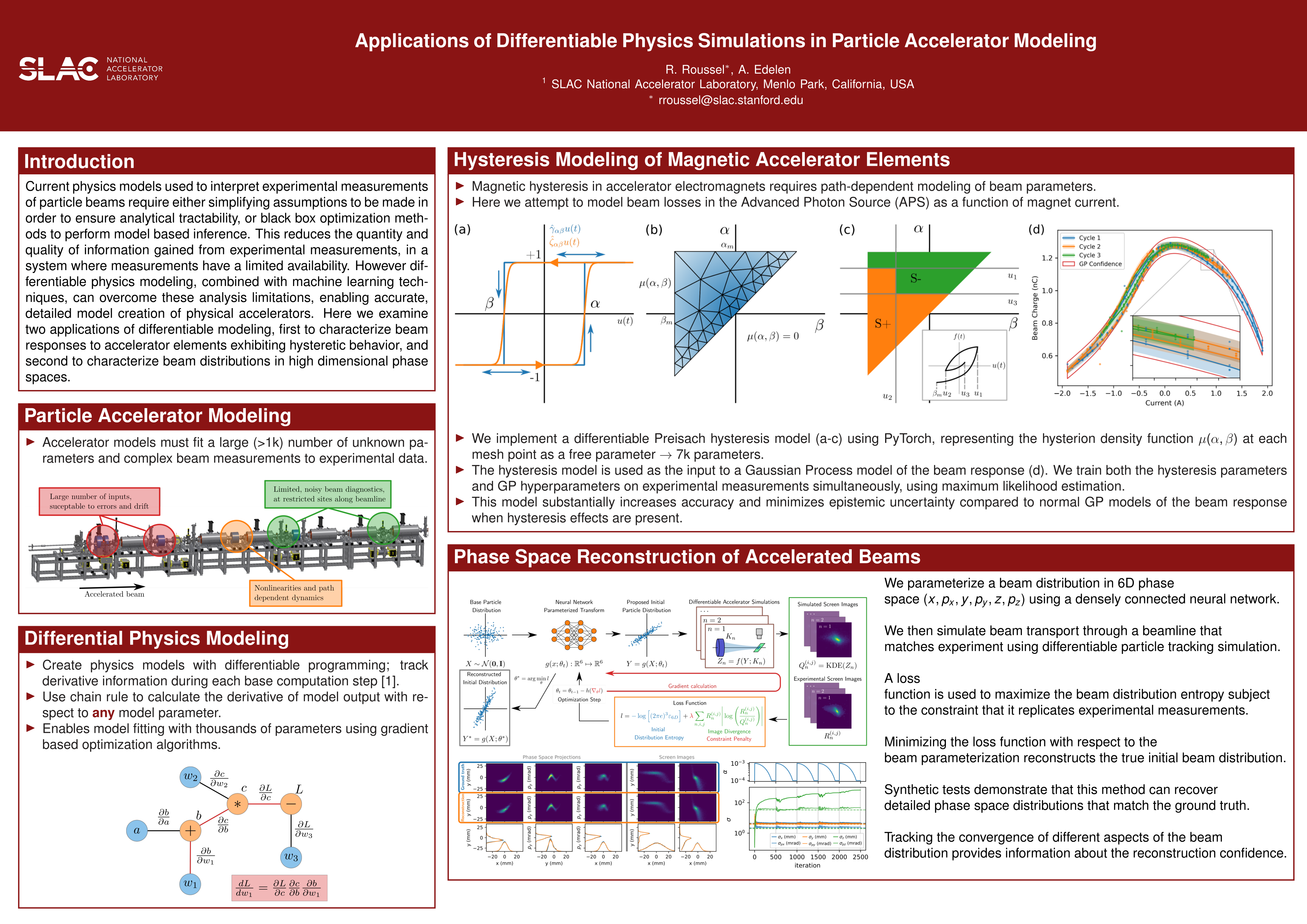
Applications of Differentiable Physics Simulations in Particle Accelerator
Modeling [paper] [poster]
[event]
Roussel,
Ryan*; Edelen, Auralee |
| 20 |
Applying Deep Reinforcement Learning to the HP Model for Protein Structure
Prediction [paper] [poster]
[event]
Yang,
Kaiyuan*; Huang, Houjing; Vandans, Olafs; Murali, Adithyavairavan; Tian, Fujia;
Yap, Roland H.C.; Dai, Liang |
| 21 |
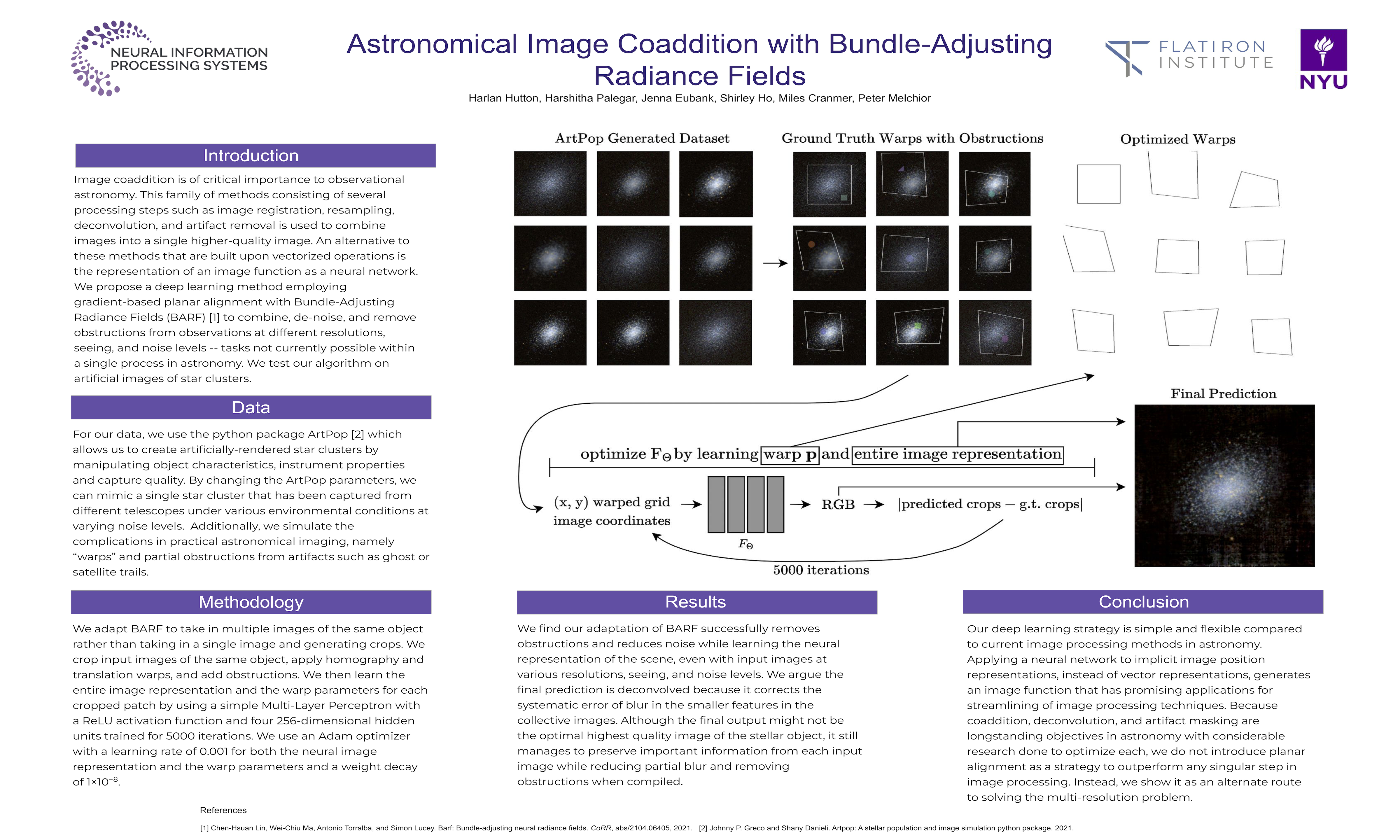
Astronomical Image Coaddition with Bundle-Adjusting Radiance Fields [paper] [poster]
[event]
Hutton,
Harlan*; Palegar, Harshitha; Ho, Shirley; Cranmer, Miles; Melchior, Peter M;
Eubank, Jenna |
| 22 |
Atmospheric retrievals of exoplanets using learned parameterizations of
pressure-temperature profiles [paper] [poster]
[event]
Gebhard,
Timothy D*; Angerhausen, Daniel; Konrad, Björn; Alei, Eleonora; Quanz, Sascha;
Schölkopf, Bernhard |
| 23 |
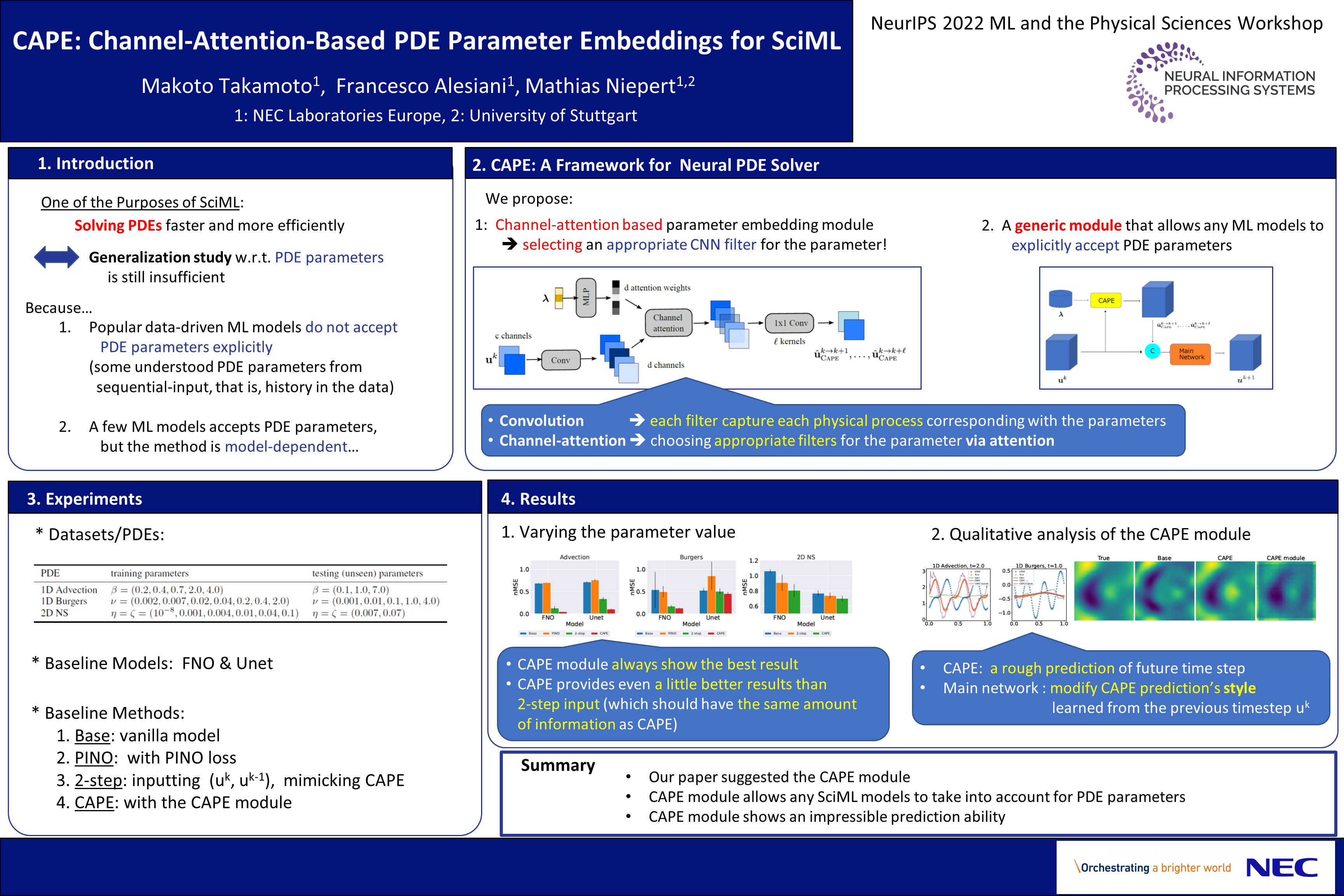
CAPE: Channel-Attention-Based PDE Parameter Embeddings for SciML [paper] [poster]
[event]
Takamoto,
Makoto*; Alesiani, Francesco; Niepert, Mathias |
| 24 |
CaloMan: Fast generation of calorimeter showers with density estimation on
learned manifolds [paper]
[poster]
[video] [event]
Cresswell,
Jesse*; Ross, Brendan L; Loaiza-Ganem, Gabriel; Reyes-Gonzalez, Humberto;
Letizia, Marco; Caterini, Anthony |
| 25 |
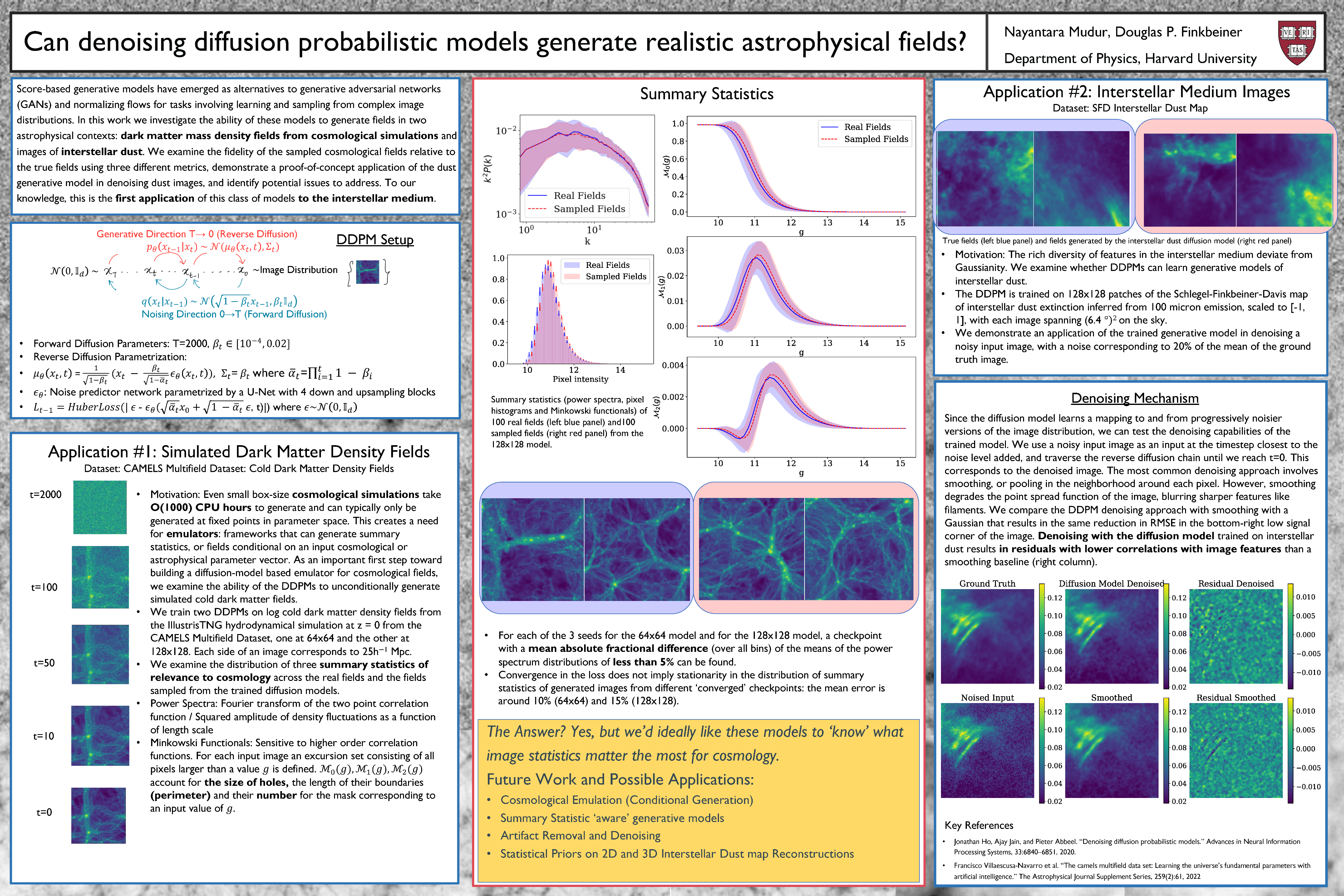
Can denoising diffusion probabilistic models generate realistic astrophysical
fields? [paper] [poster]
[event]
Mudur,
Nayantara*; Finkbeiner, Douglas |
| 26 |
Certified data-driven physics-informed greedy auto-encoder simulator [paper] [poster]
[video] [event]
He,
Xiaolong*; Choi, Youngsoo; Fries, William; Belof, Jonathan; Chen, Jiun-Shyan
|
| 27 |
Characterizing information loss in a chaotic double pendulum with the
Information Bottleneck [paper] [poster]
[event]
Murphy,
Kieran A*; Bassett, Danielle S |
| 28 |
ClimFormer - a Spherical Transformer model for long-term climate
projections [paper] [poster]
[event]
Ruhling
Cachay, Salva; Mitra, Peetak P*; Kim, Sookyung; Hazarika, Subhashis; Hirasawa,
Haruki; Hingmire, Dipti S; Singh, Hansi; Ramea, Kalai |
| 29 |
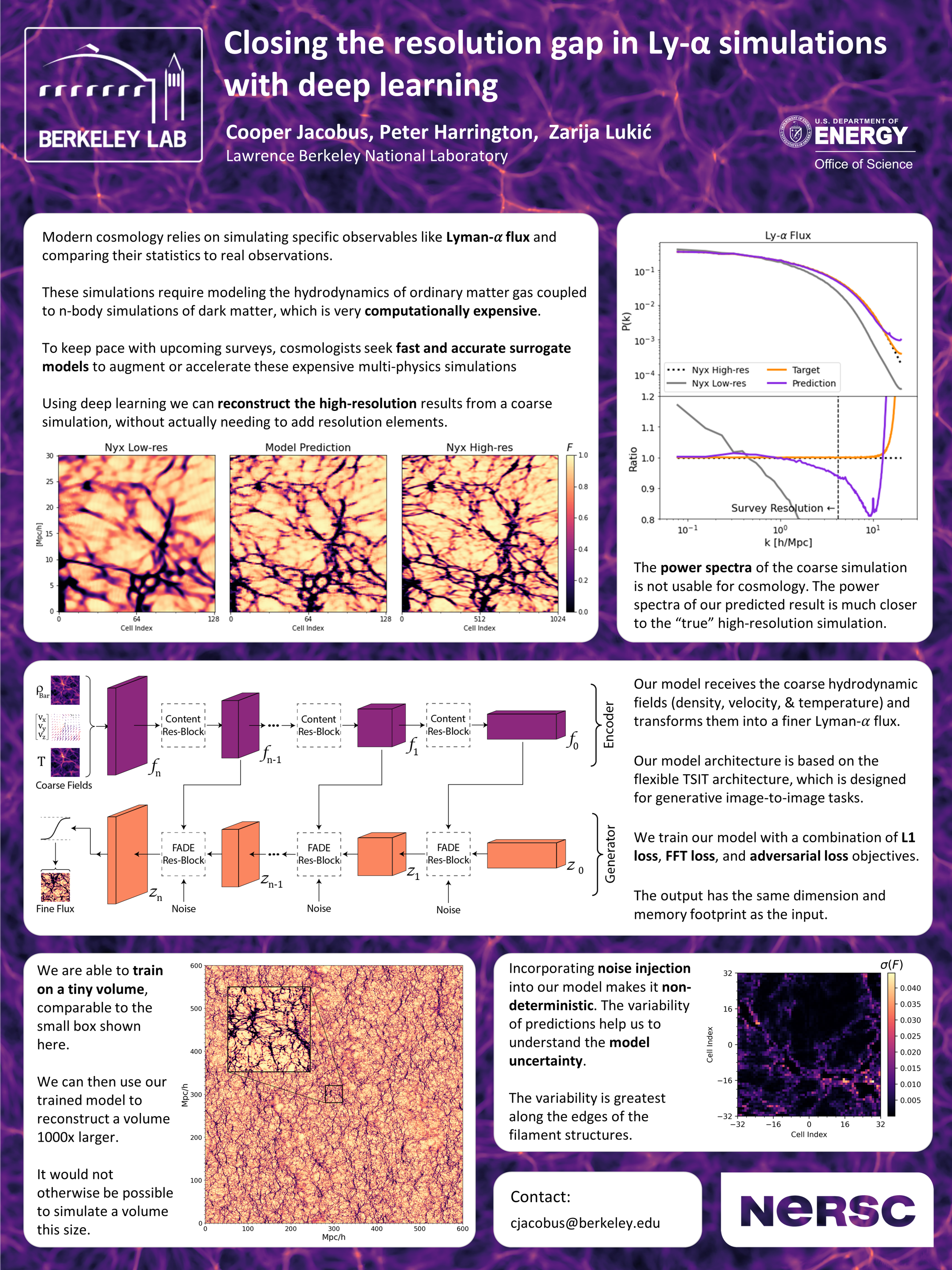
Closing the resolution gap in Lyman alpha simulations with deep learning
[paper] [poster]
[event]
Jacobus,
Cooper H*; Harrington, Peter ; Lukić, Zarija |
| 30 |
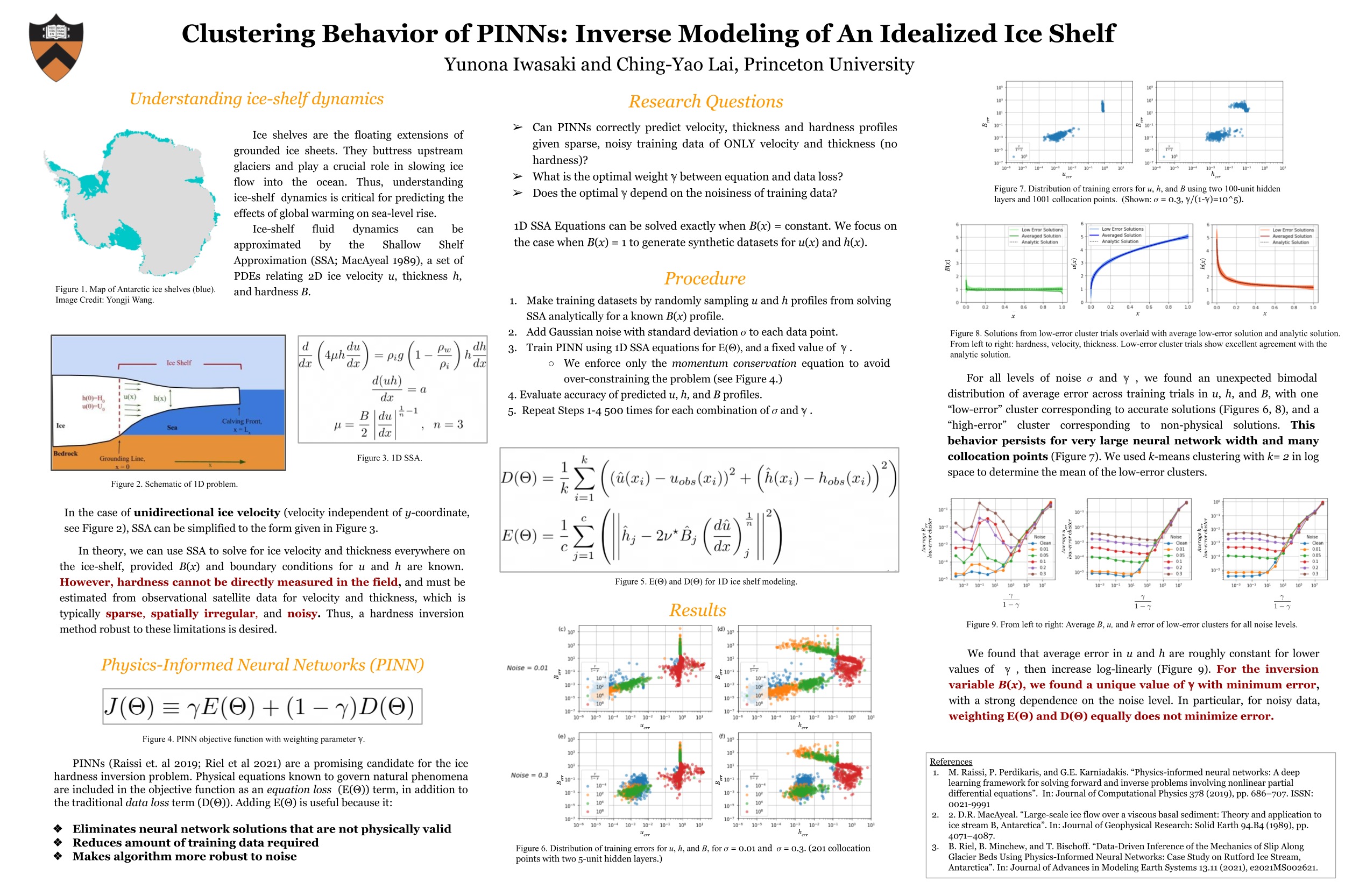
Clustering Behaviour of Physics-Informed Neural Networks: Inverse Modeling of
An Idealized Ice Shelf [paper] [poster]
[event]
Iwasaki,
Yunona*; Lai, Ching-Yao |
| 31 |
Combinational-convolution for flow-based sampling algorithm [paper] [poster]
[event]
Tomiya,
Akio* |
| 32 |
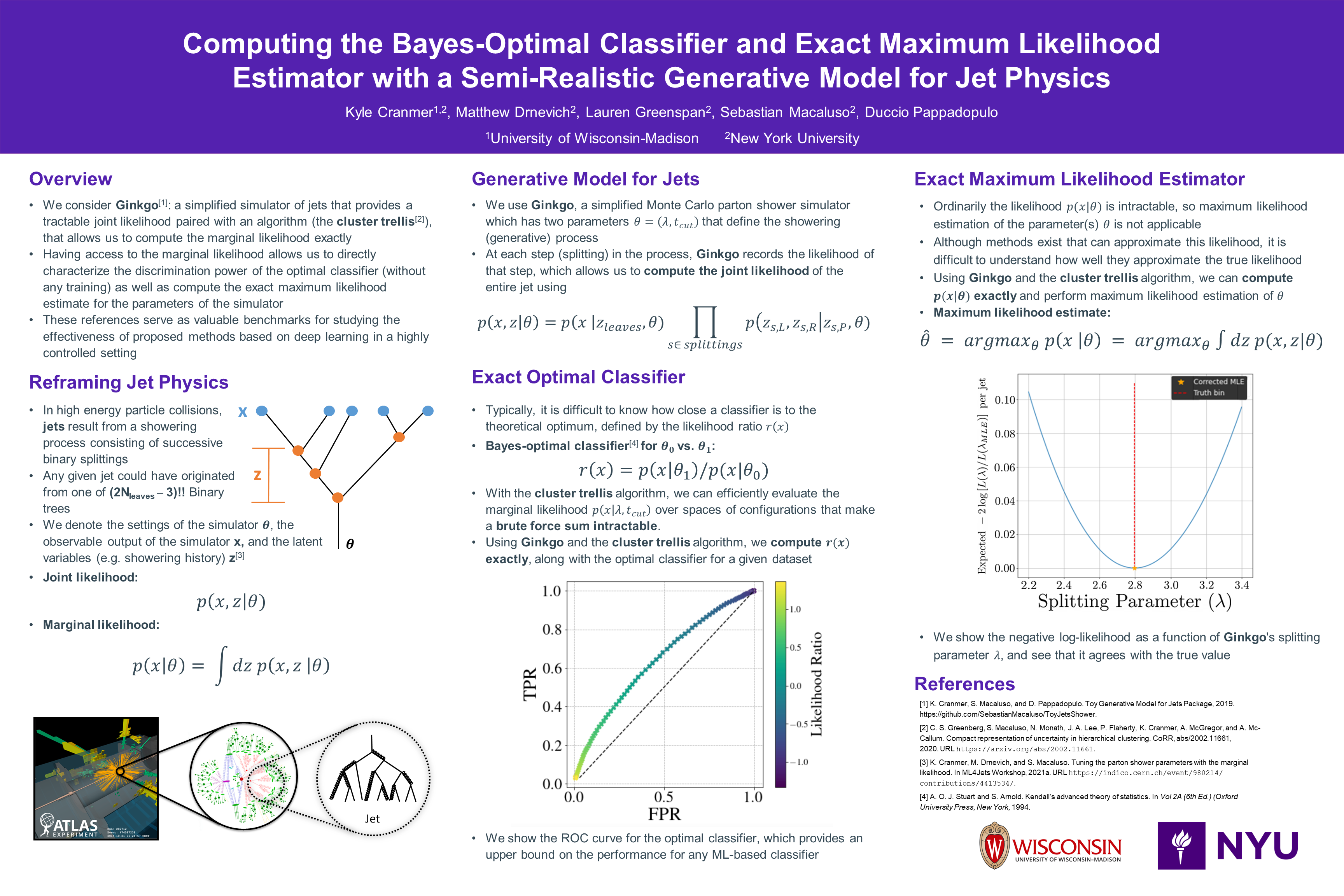
Computing the Bayes-optimal classifier and exact maximum likelihood estimator
with a semi-realistic generative model for jet physics [paper] [poster]
[event]
Cranmer,
Kyle; Drnevich, Matthew*; Greenspan, Lauren; Macaluso, Sebastian; Pappadopulo,
Duccio |
| 33 |
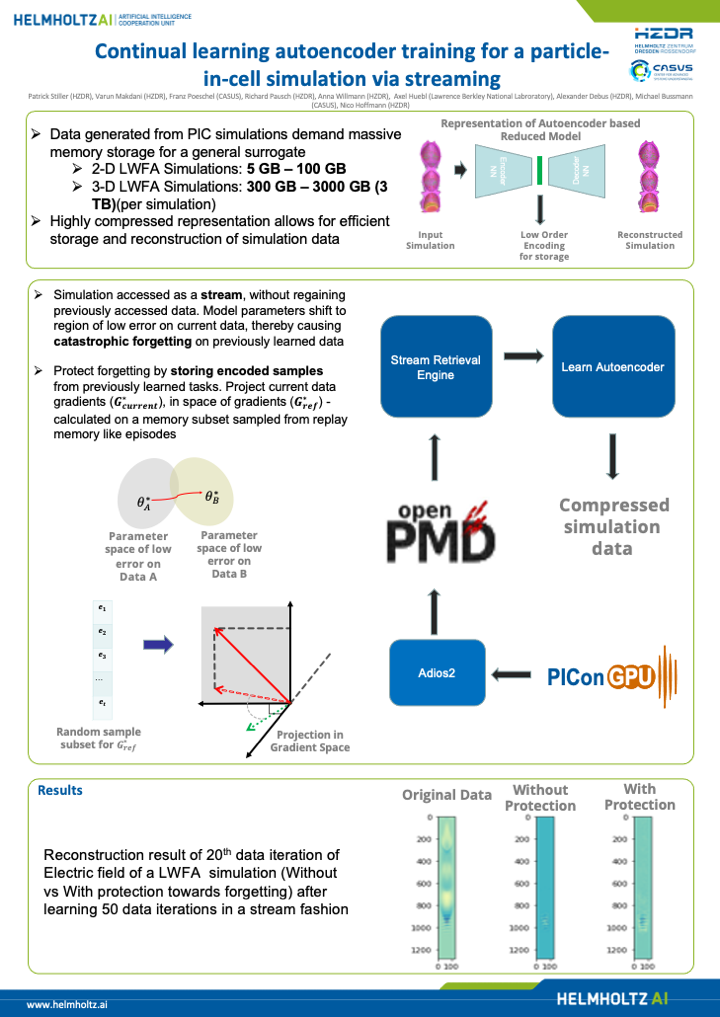
Continual learning autoencoder training for a particle-in-cell simulation via
streaming [paper] [poster]
[event]
Stiller,
Patrick*; Makdani, Varun; Pöschel, Franz; Pausch, Richard; Debus, Alexander;
Bussmann, Michael; Hoffmann, Nico |
| 34 |
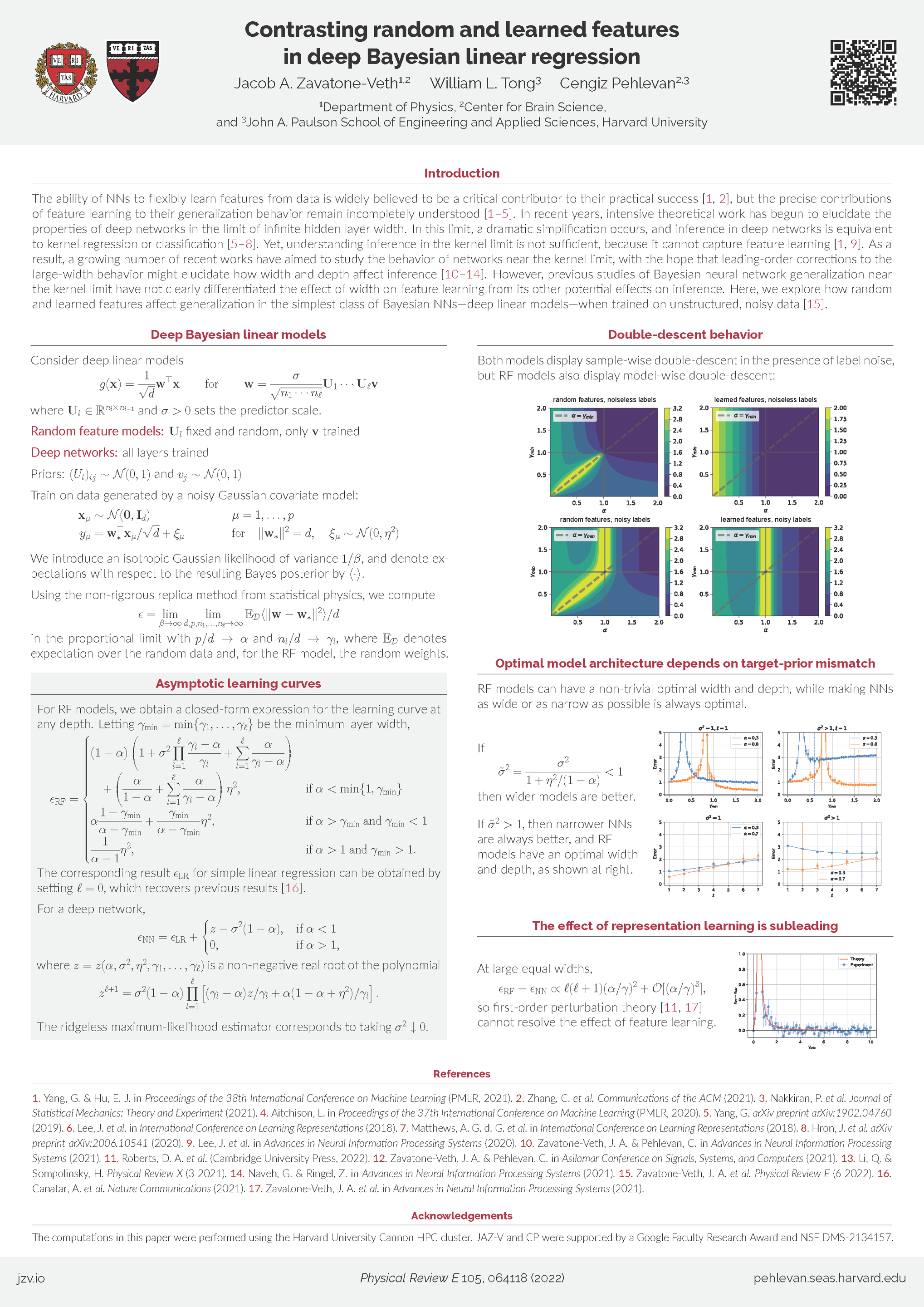
Contrasting random and learned features in deep Bayesian linear
regression [paper] [poster]
[event]
Zavatone-Veth,
Jacob A*; Tong, William; Pehlevan, Cengiz |
| 35 |
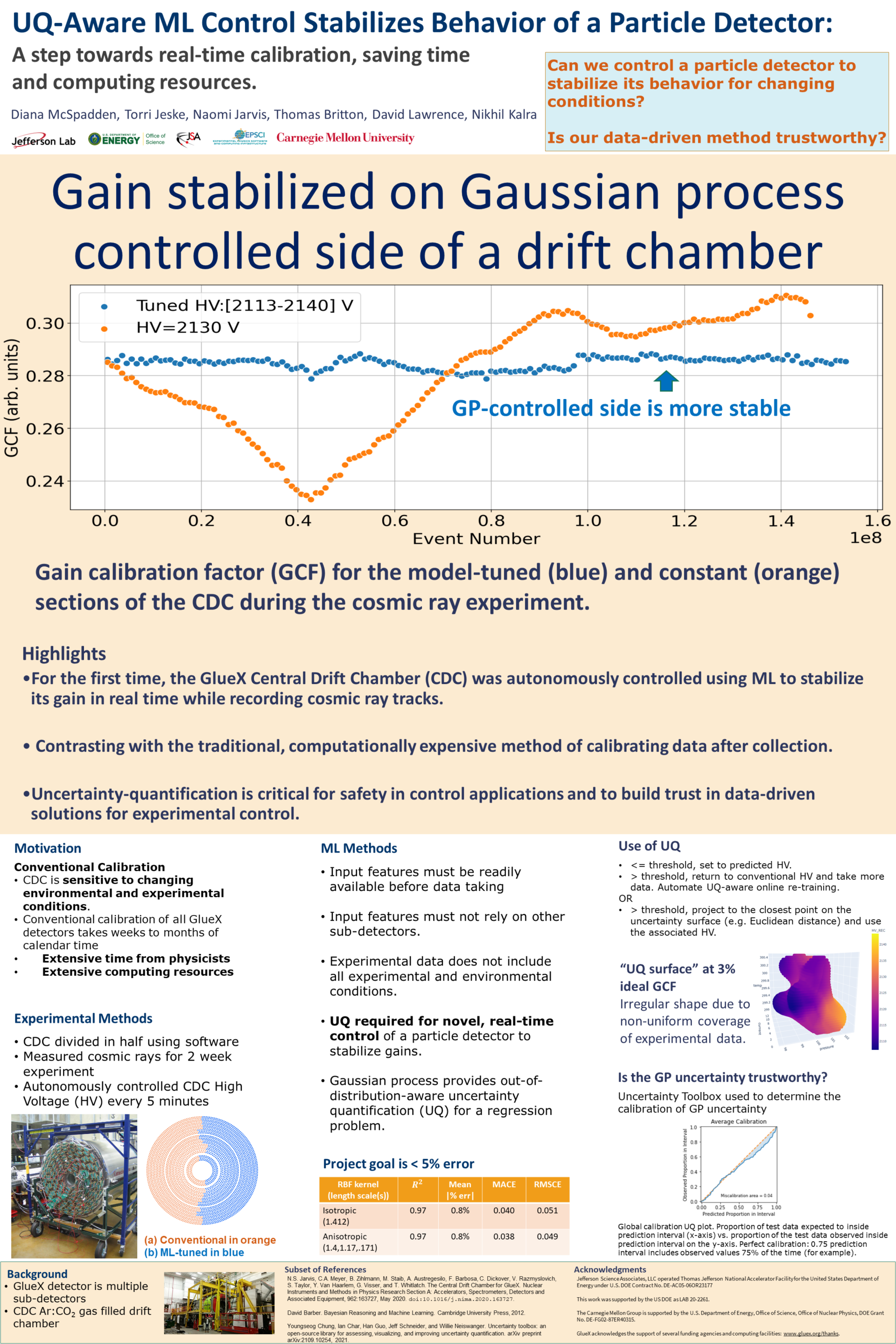
Control and Calibration of GlueX Central Drift Chamber Using Gaussian Process
Regression [paper] [poster]
[event]
McSpadden,
Diana*; Jeske, Torri; Jarvis, Naomi; Lawrence, David; Britton, Thomas; Kalra,
Nikhil |
| 36 |
Cosmology from Galaxy Redshift Surveys with PointNet [paper] [poster]
[video] [event]
Anagnostidis,
Sotirios-Konstantinos*; Thomsen, Arne; Refregier, Alexandre; Kacprzak, Tomasz;
Biggio, Luca; Hofmann, Thomas; Troester, Tilman |
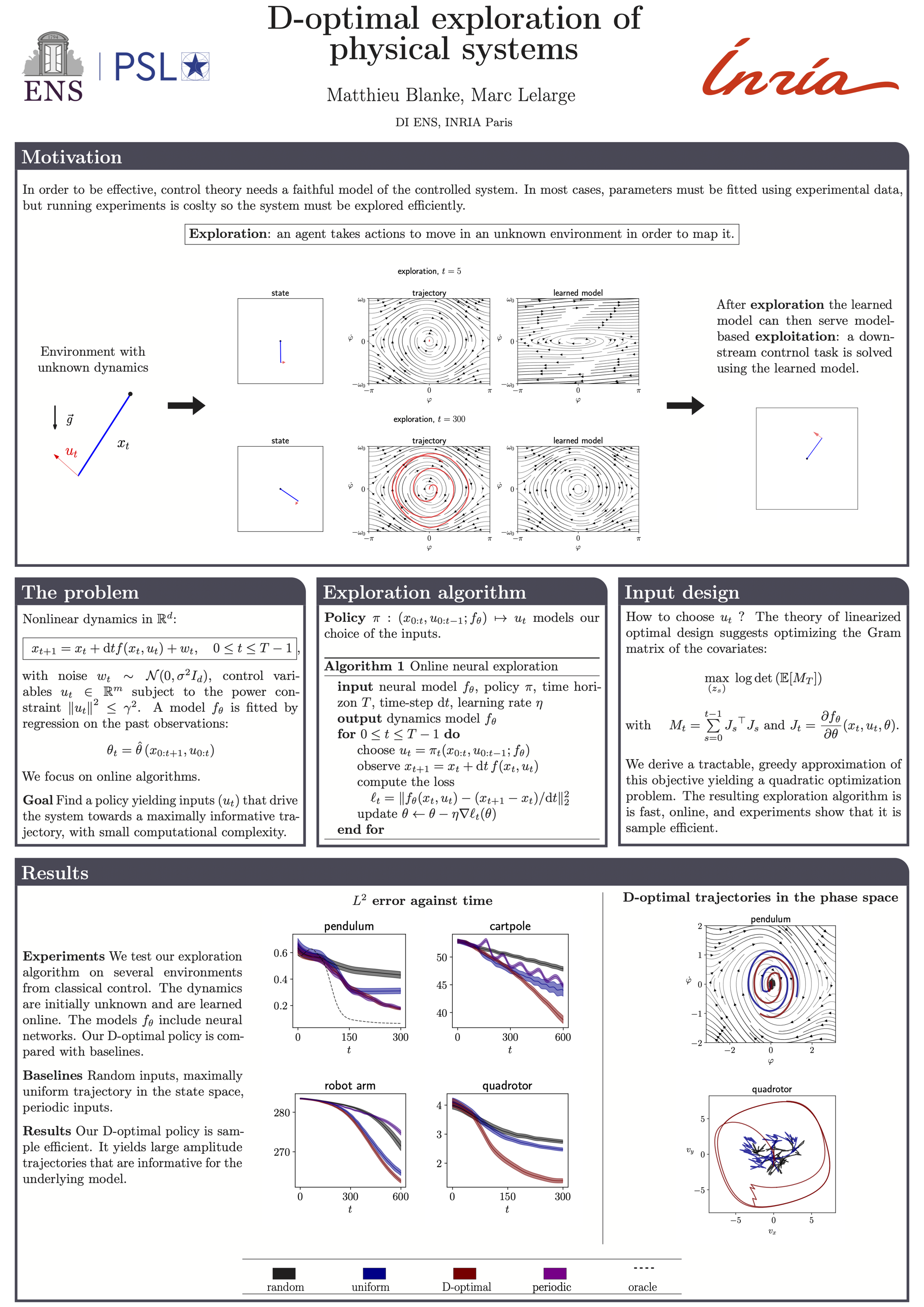
| 37 |
D-optimal neural exploration of nonlinear physical systems [paper] [poster]
[event]
Blanke,
Matthieu*; Lelarge, Marc |
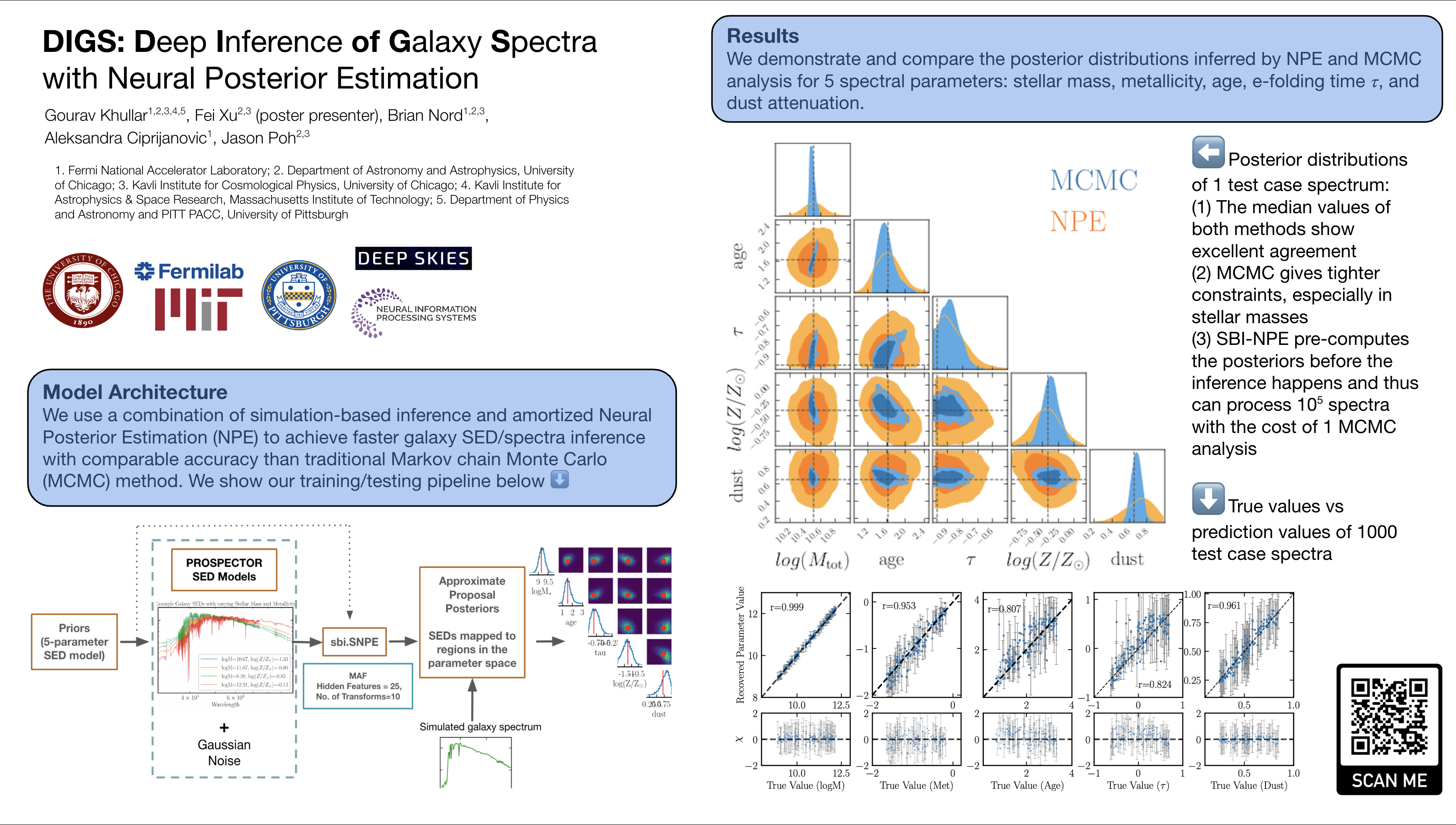
| 38 |
DIGS: Deep Inference of Galaxy Spectra with Neural Posterior Estimation
[paper] [poster]
[event]
Khullar,
Gourav*; Nord, Brian; Ciprijanovic, Aleksandra; Poh, Jason; Xu, Fei; Samudre,
Ashwin |
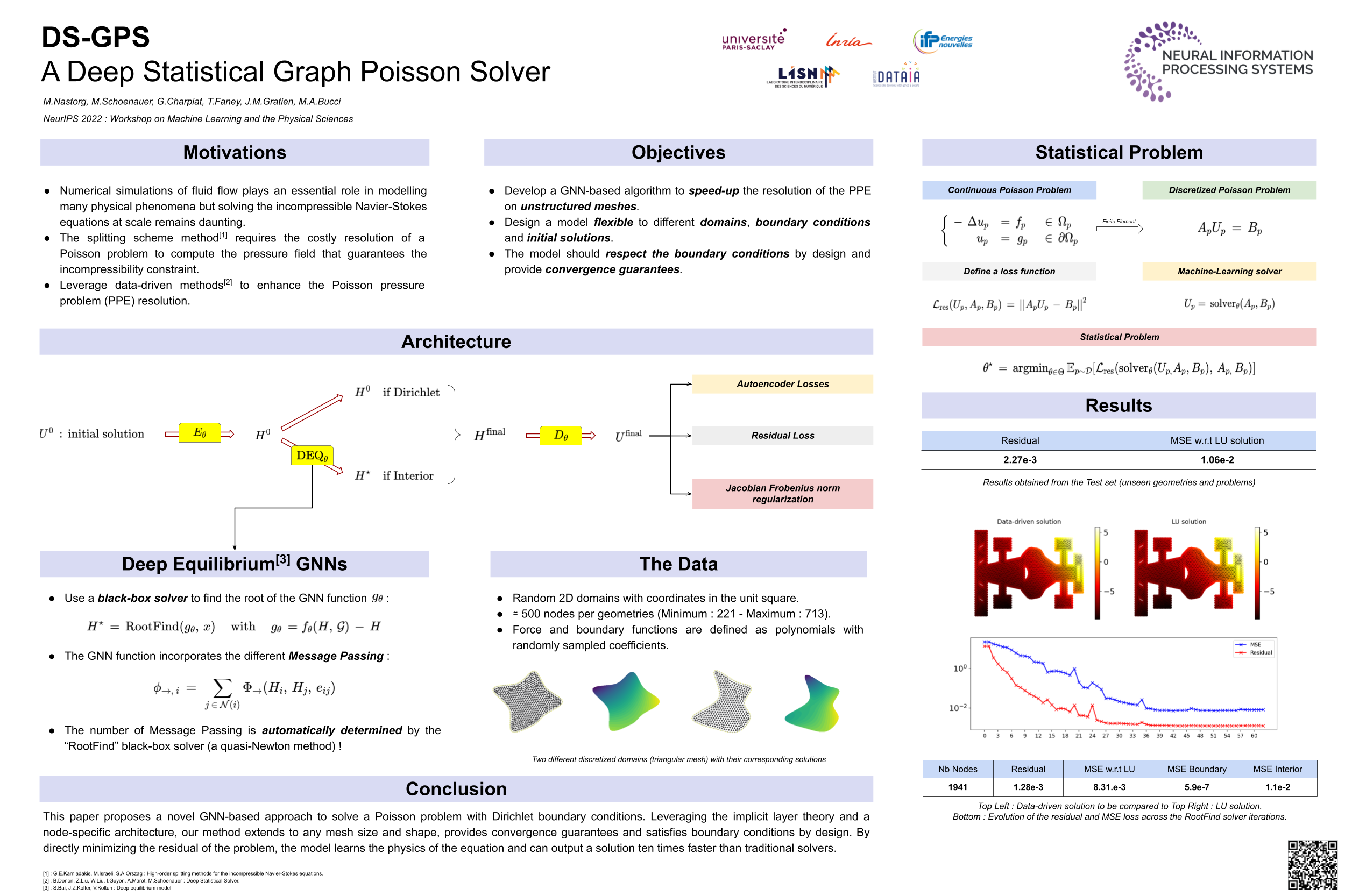
| 39 |
DS-GPS : A Deep Statistical Graph Poisson Solver (for faster CFD
simulations) [paper] [poster]
[event]
Nastorg,
Matthieu* |
| 40 |
Data-driven discovery of non-Newtonian astronomy via learning non-Euclidean
Hamiltonian [paper] [poster]
[event]
So, Oswin*;
Li, Gongjie; Theodorou, Evangelos; Tao, Molei |
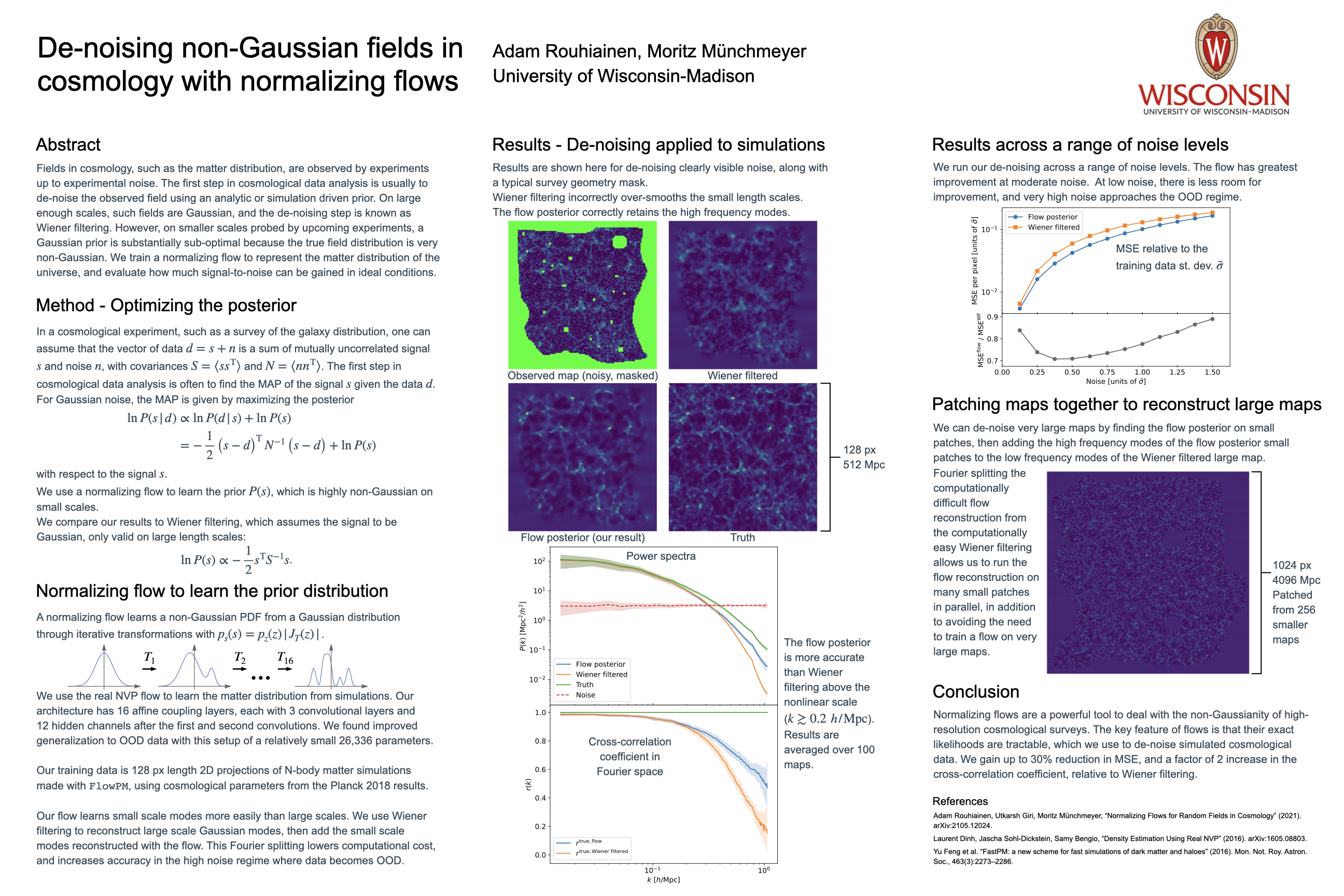
| 41 |
De-noising non-Gaussian fields in cosmology with normalizing flows [paper] [poster]
[event]
Rouhiainen,
Adam*; Münchmeyer, Mortiz |
| 42 |
Decay-aware neural network for event classification in collider physics
[paper] [poster]
[event]
Kishimoto,
Tomoe*; Morinaga, Masahiro; Saito, Masahiko; Tanaka, Junichi |
| 43 |
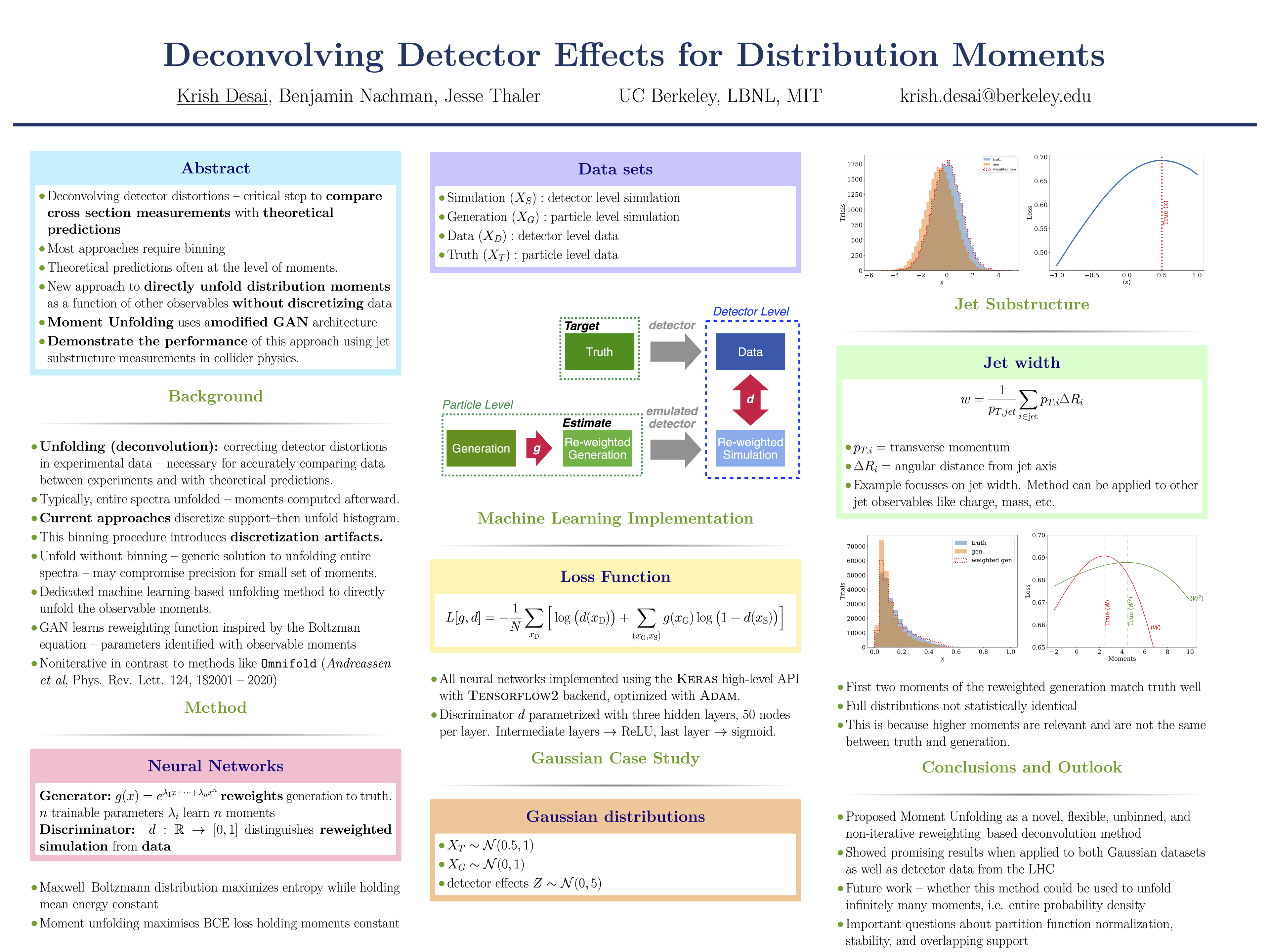
Deconvolving Detector Effects for Distribution Moments [paper] [poster]
[event]
Desai,
Krish*; Nachman, Benjamin; Thaler, Jesse |
| 44 |
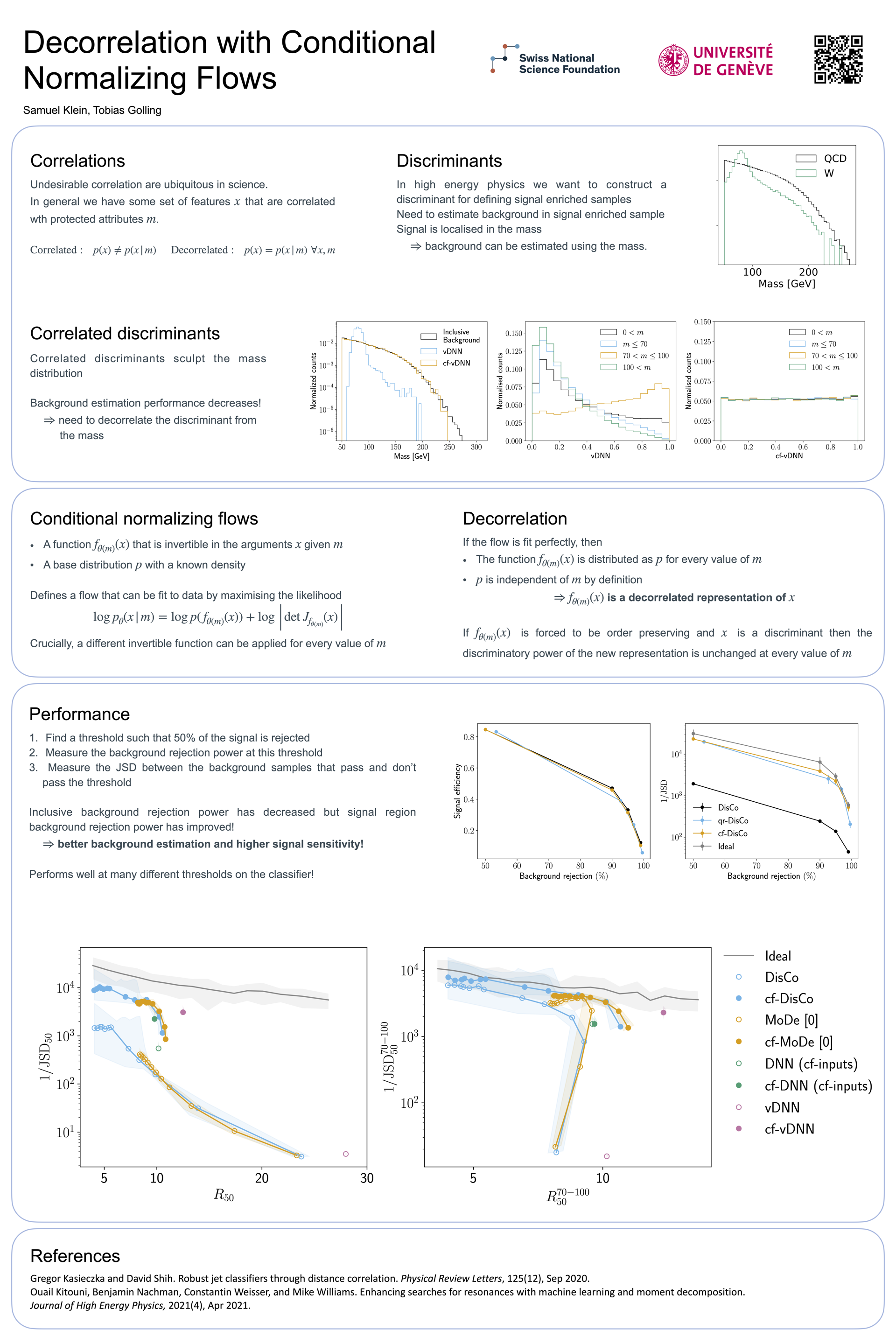
Decorrelation with Conditional Normalizing Flows [paper] [poster]
[event]
Klein,
Samuel*; Golling, Tobias |
| 45 |
Deep Learning Modeling of Subgrid Physics in Cosmological N-body
Simulations [paper] [poster]
[event]
Chatziloizos,
George-Mark; Lanusse, François; Cazenave, Tristan* |
| 46 |
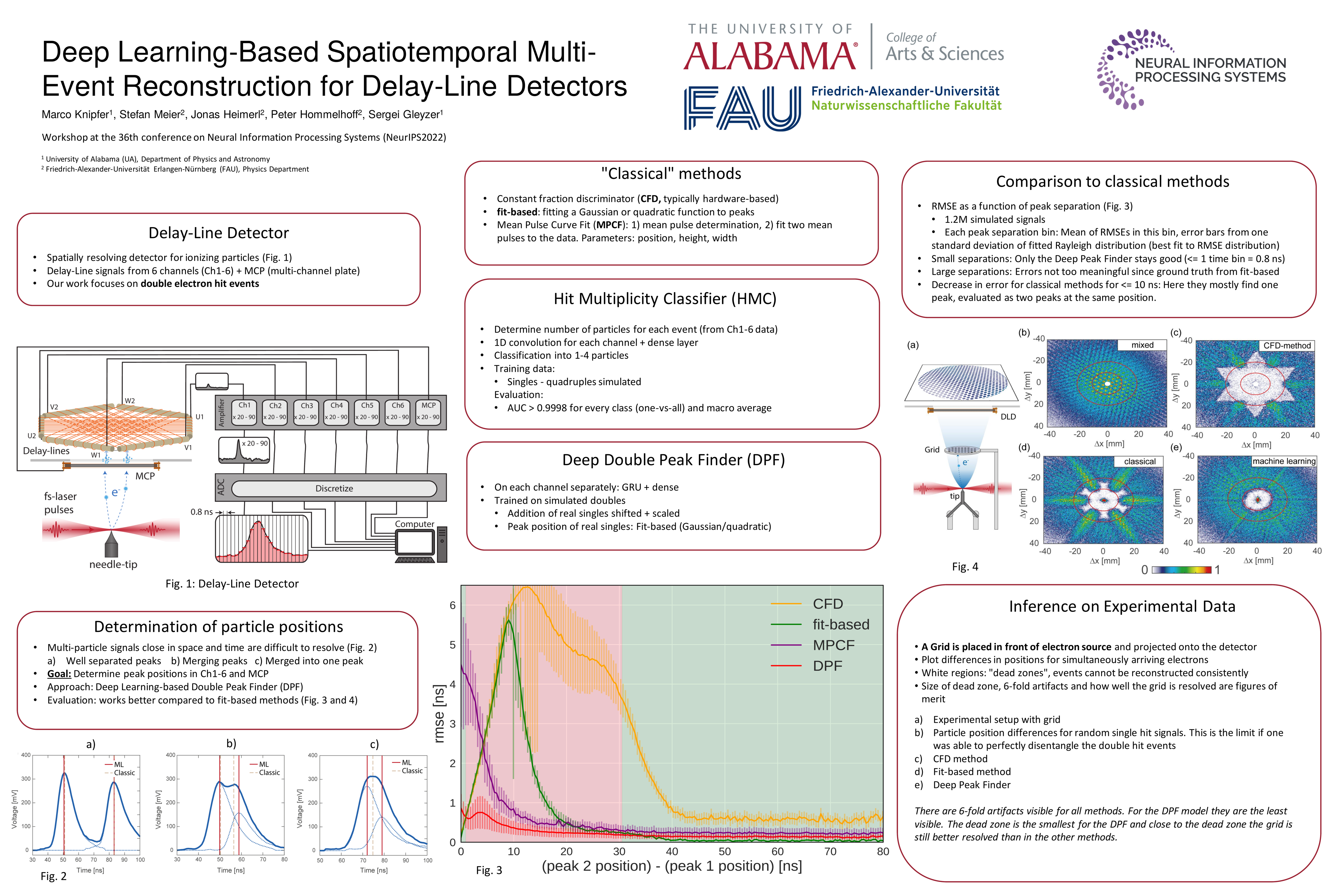
Deep Learning-Based Spatiotemporal Multi-Event Reconstruction for Delay-Line
Detectors [paper] [poster]
[event]
Knipfer,
Marco*; Gleyzer, Sergei; Meier, Stefan; Heimerl, Jonas; Hommelhoff, Peter |
| 47 |
Deep-pretrained-FWI: combining supervised learning with physics-informed
neural network [paper] [poster]
[video] [event]
MULLER, ANA
PAULA OLIVEIRA*; Bom , Clecio Roque; Costa, Jessé Carvalho; Faria, Elisângela
Lopes ; de Albuquerque, Marcelo Portes ; de Albuquerque, Marcio Portes |
| 48 |
Deformations of Boltzmann Distributions [paper] [poster]
[event]
Mate,
Balint A*; Fleuret, François |
| 49 |
Detecting structured signals in radio telescope data using RKHS [paper] [poster]
[event]
Tsuchida,
Russell*; Yong, Suk Yee |
| 50 |
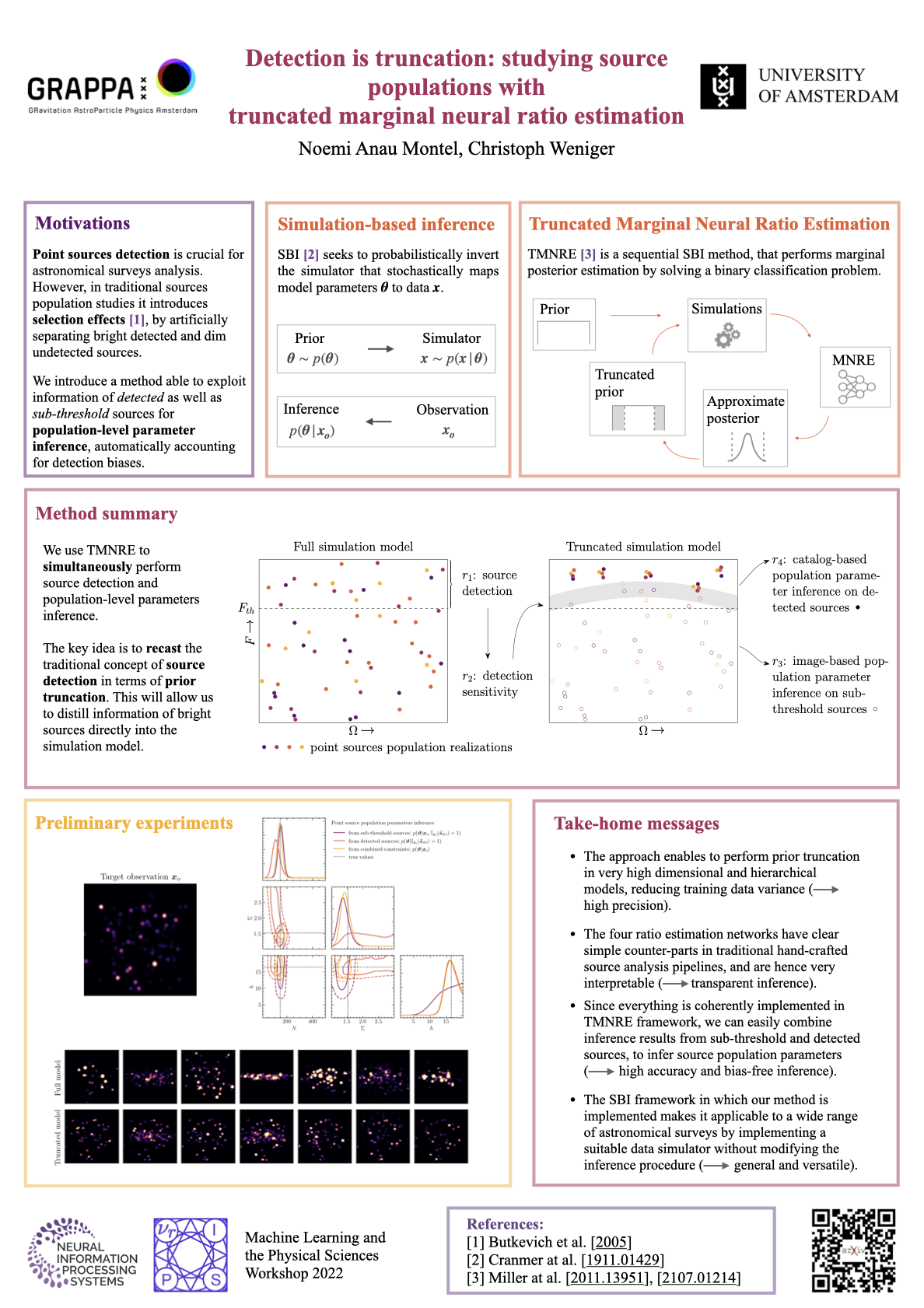
Detection is truncation: studying source populations with truncated marginal
neural ratio estimation [paper] [poster]
[event]
Anau
Montel, Noemi*; Weniger, Christoph |
| 51 |
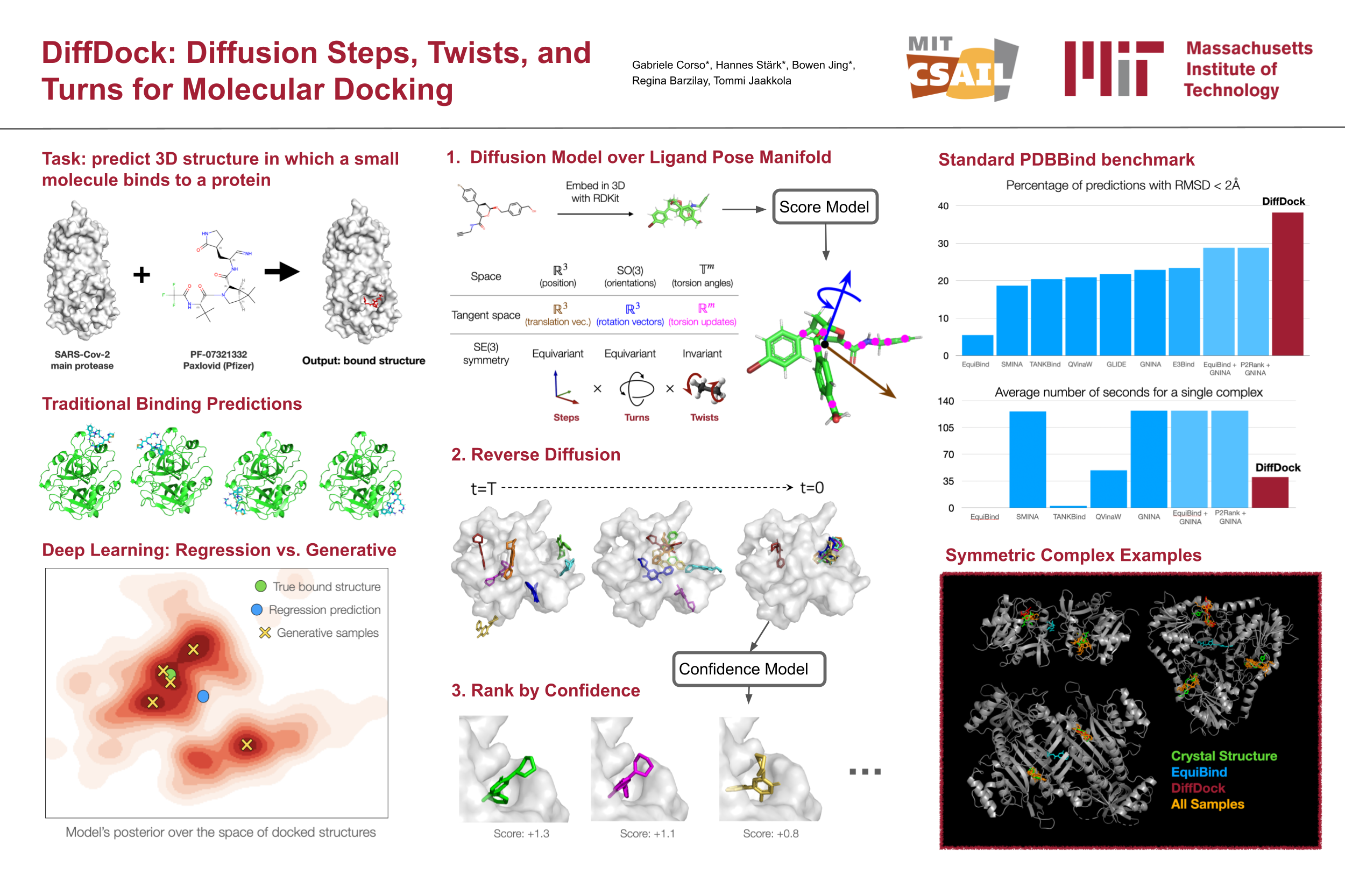
DiffDock: Diffusion Steps, Twists, and Turns for Molecular Docking [paper] [poster]
[event]
Corso,
Gabriele*; Stärk, Hannes; Jing, Bowen; Barzilay, Dr.Regina; Jaakkola, Tommi |
| 52 |
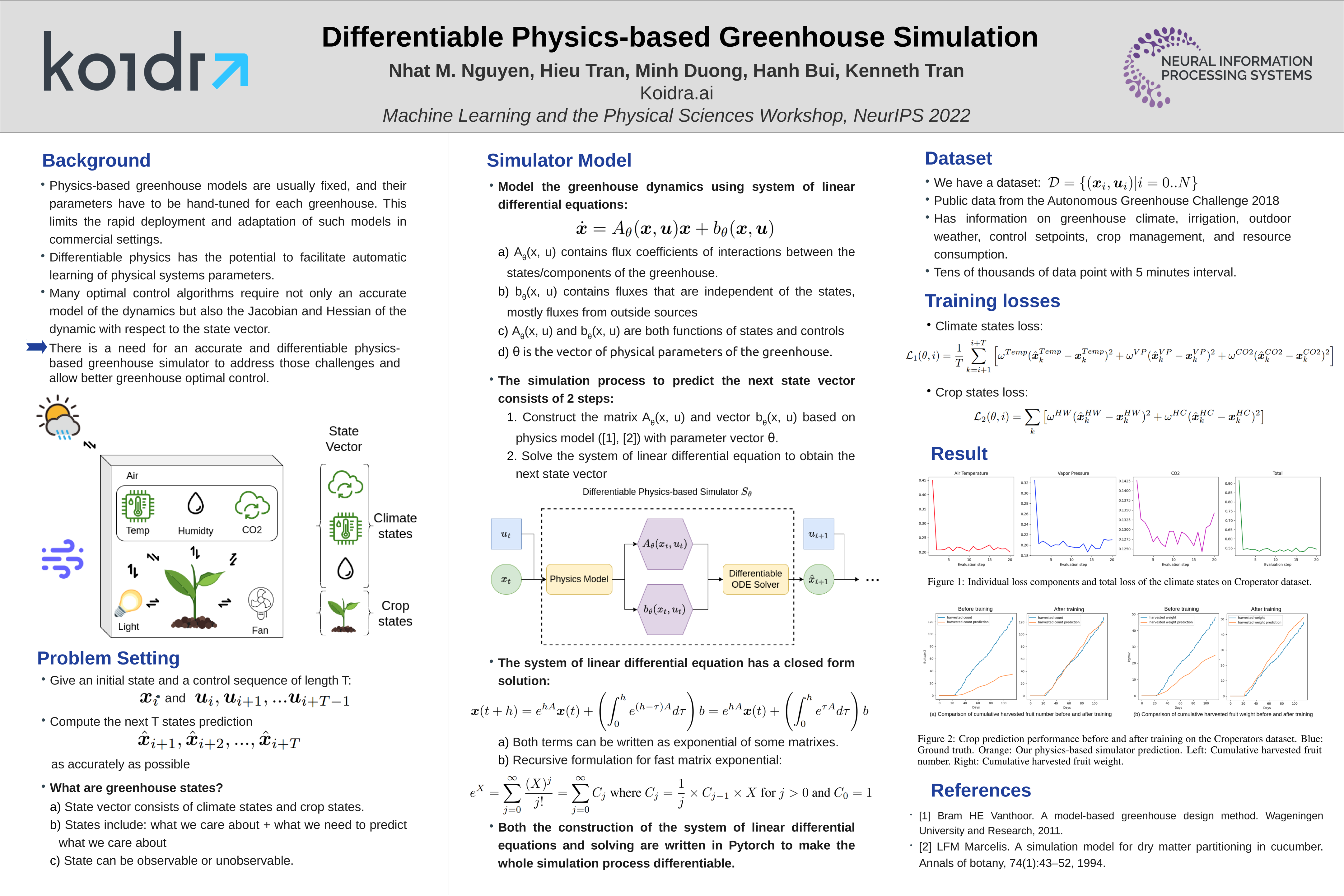
Differentiable Physics-based Greenhouse Simulation [paper] [poster]
[video] [event]
Nguyen,
Nhat M.*; Tran, Hieu; Duong, Minh; Bui, Hanh; Tran, Kenneth |
| 53 |
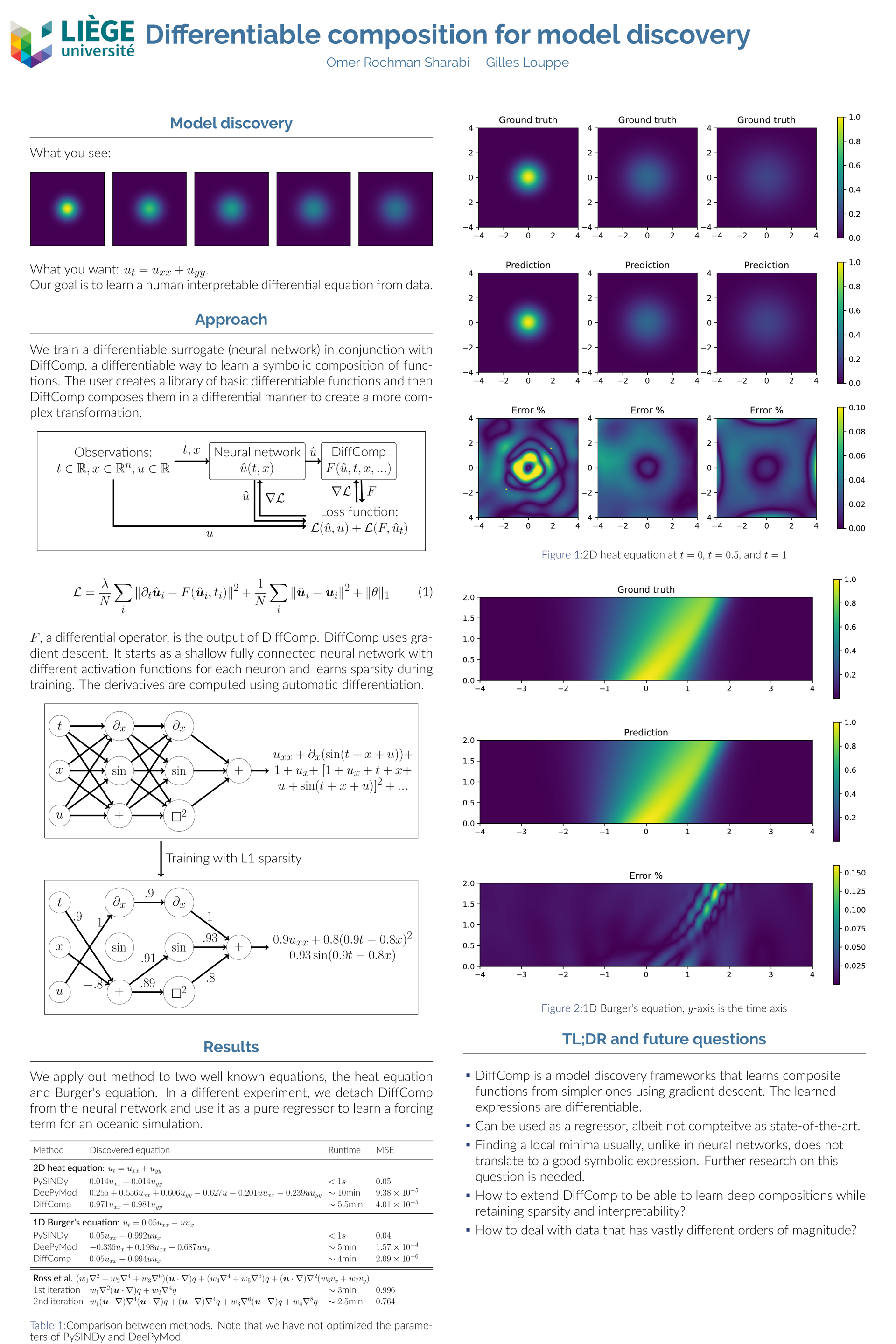
Differentiable composition for model discovery [paper] [poster]
[event]
Rochman
Sharabi, Omer*; Louppe, Gilles |
| 54 |
Discovering Long-period Exoplanets using Deep Learning with Citizen Science
Labels [paper] [poster]
[event]
Malik,
Shreshth A*; Eisner, Nora; Lintott, Chris; Gal, Yarin |
| 55 |
Diversity Balancing Generative Adversarial Networks for fast simulation of
the Zero Degree Calorimeter in the ALICE experiment at CERN [paper] [poster]
[video] [event]
Dubiński,
Jan Michał *; Deja, Kamil; Wenzel, Sandro; Rokita, Przemysław; Trzcinski, Tomasz
|
| 56 |
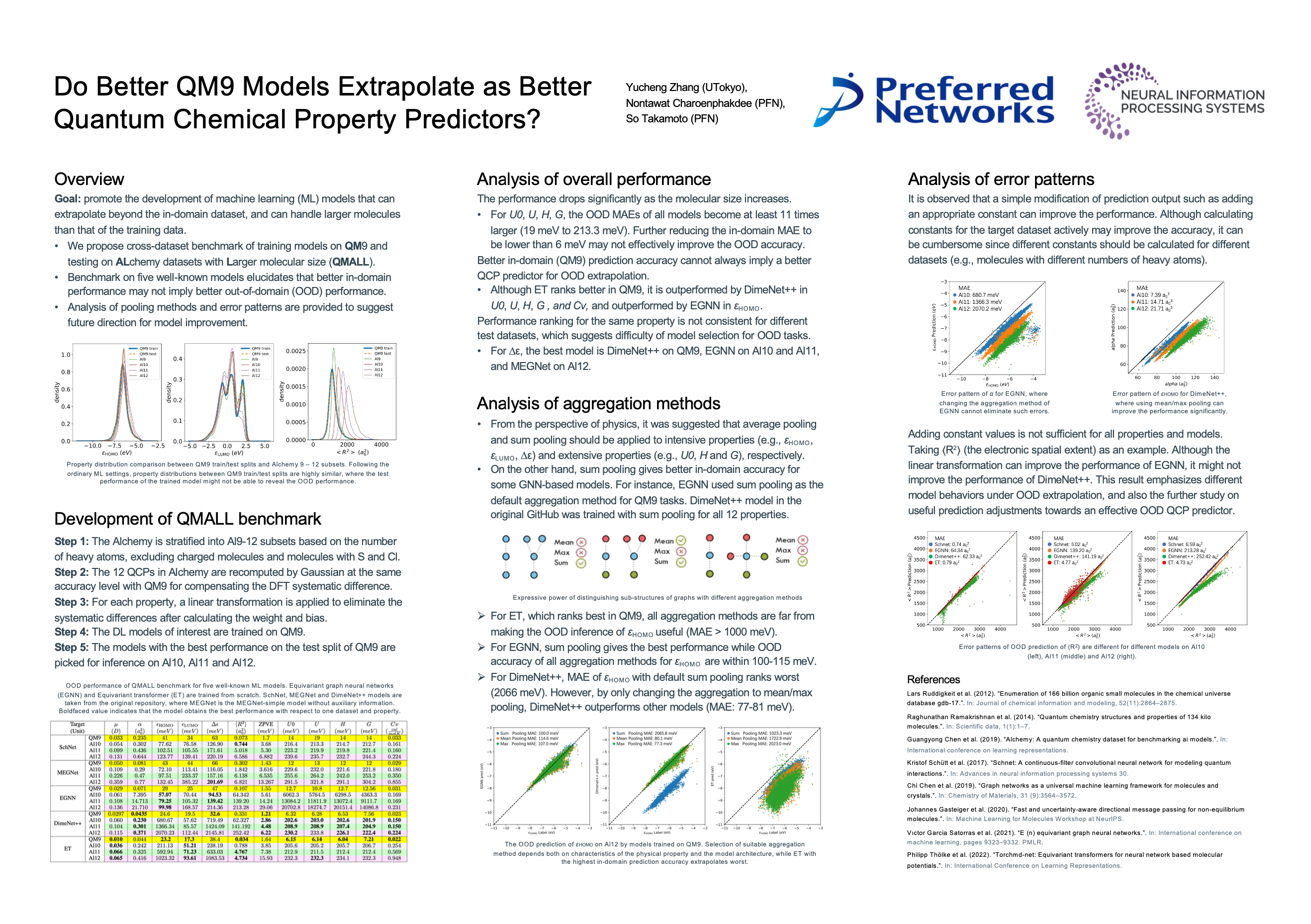
Do Better QM9 Models Extrapolate as Better Quantum Chemical Property
Predictors? [paper] [poster]
[event]
ZHANG,
YUCHENG*; Charoenphakdee, Nontawat; Takamoto, So |
| 57 |
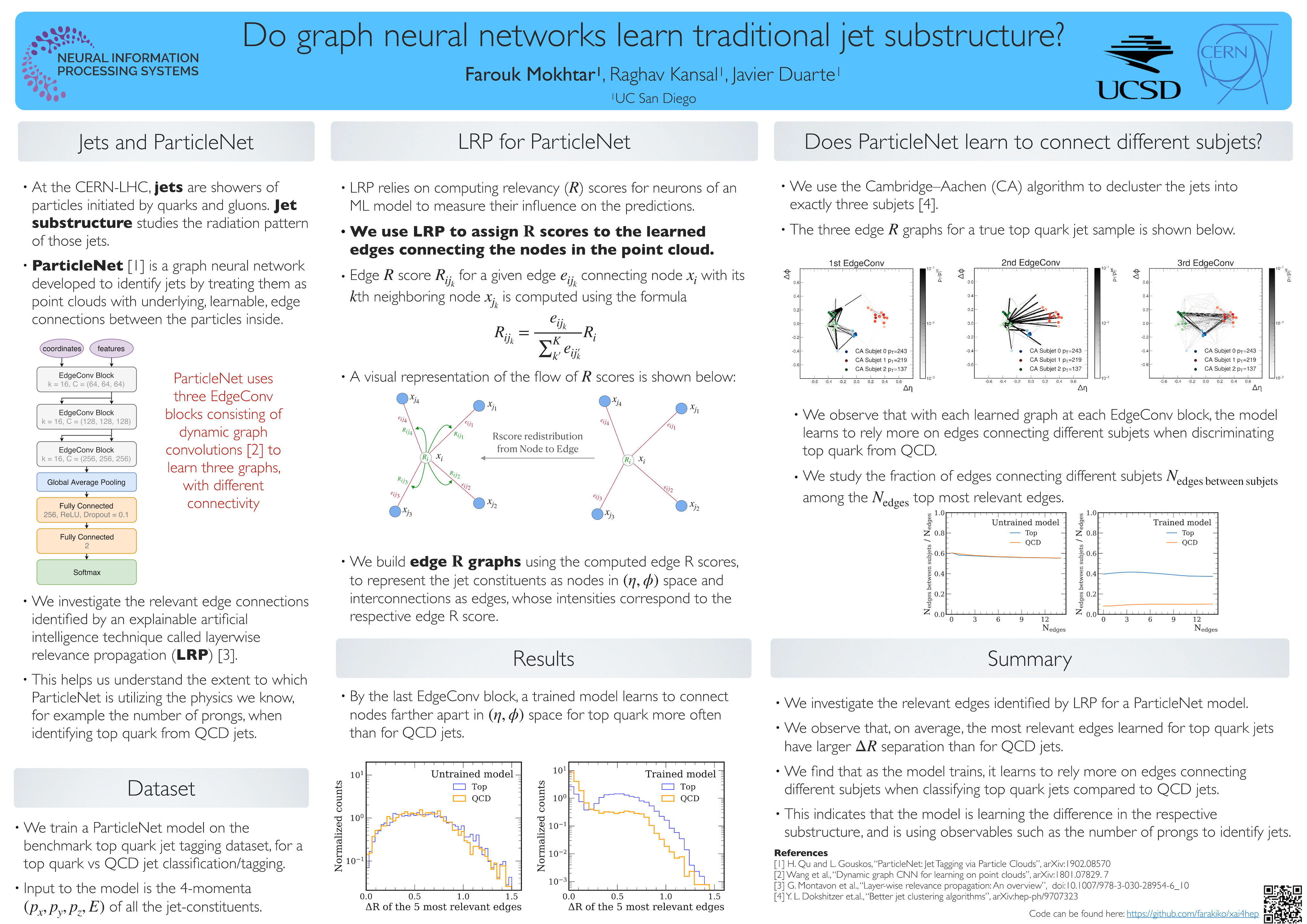
Do graph neural networks learn jet substructure? [paper] [poster]
[event]
Mokhtar,
Farouk*; Kansal, Raghav; Duarte, Javier |
| 58 |
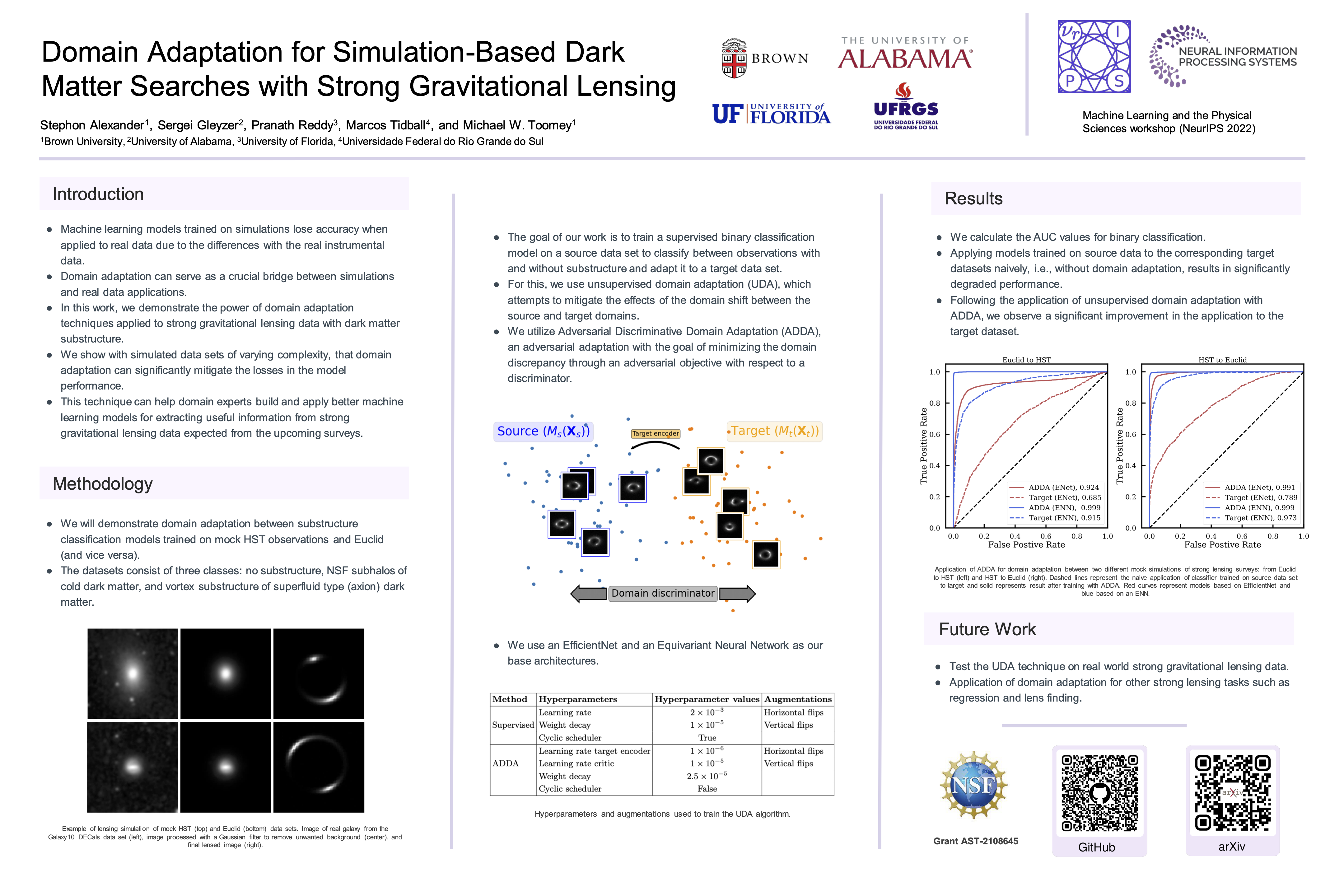
Domain Adaptation for Simulation-Based Dark Matter Searches with Strong
Gravitational Lensing [paper] [poster]
[event]
Kumbam,
Pranath Reddy; Gleyzer, Sergei; Toomey, Michael W*; Tidball, Marcos |
| 59 |
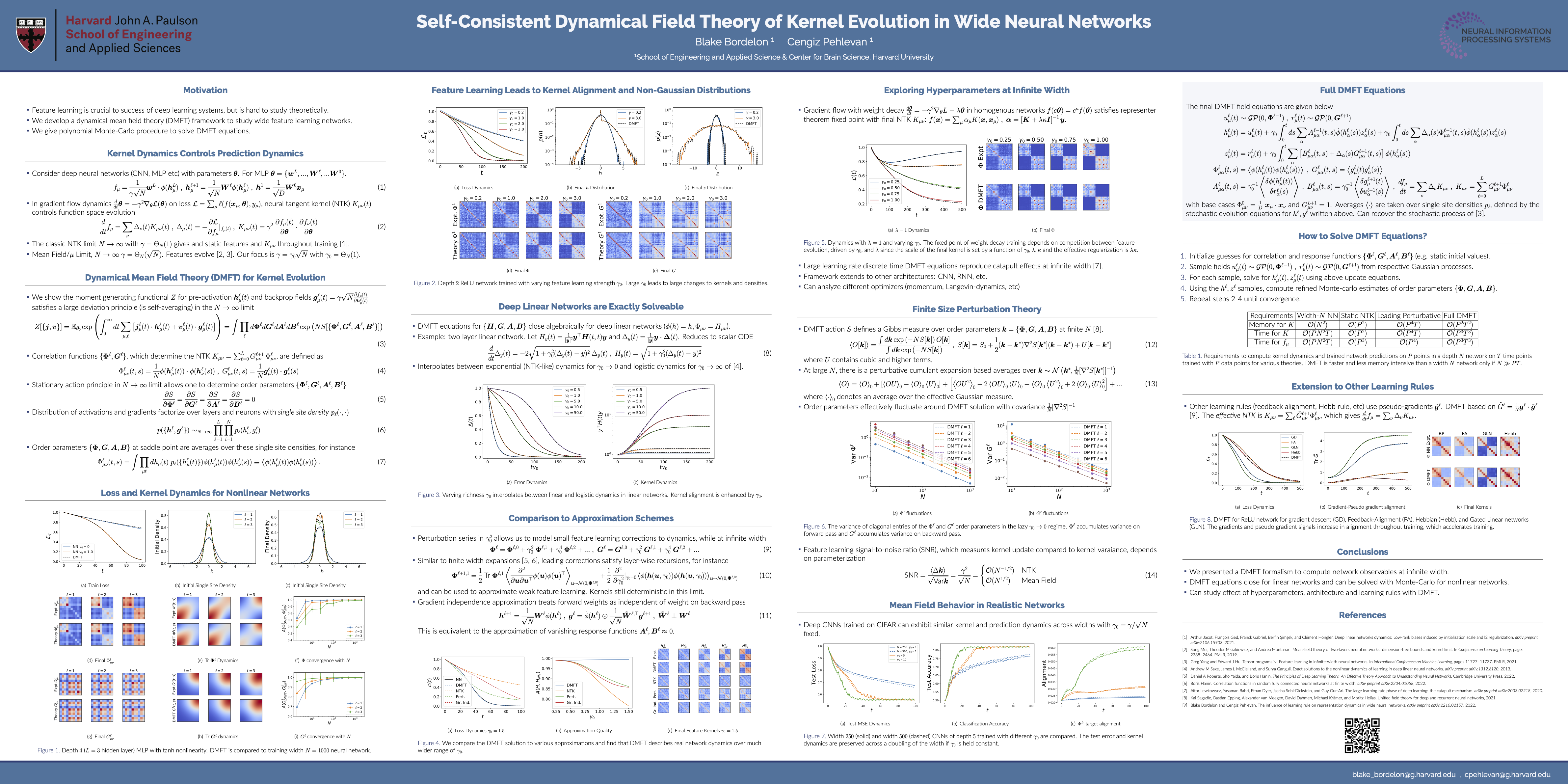
Dynamical Mean Field Theory of Kernel Evolution in Wide Neural Networks
[paper] [poster]
[event]
Bordelon,
Blake A; Pehlevan, Cengiz* |
| 60 |
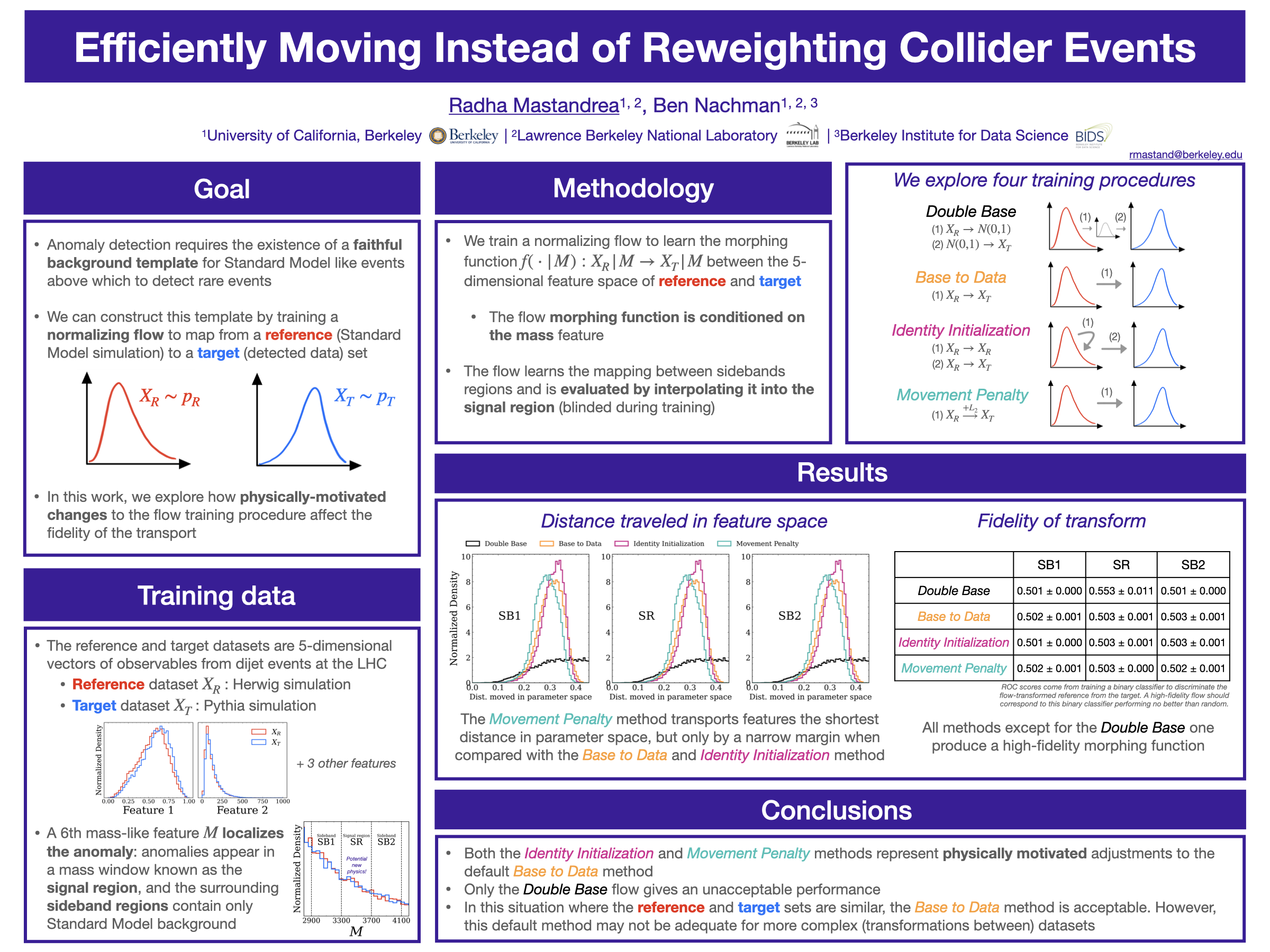
Efficiently Moving Instead of Reweighting Collider Events with Machine
Learning [paper] [poster]
[event]
Mastandrea,
Radha*; Nachman, Benjamin |
| 61 |
Elements of effective machine learning datasets in astronomy [paper] [poster]
[event]
Boscoe,
Bernadette*; Do , Tuan |
| 62 |
Employing CycleGANs to Generate Realistic STEM Images for Machine
Learning [paper] [poster]
[event]
Khan, Abid
A*; Lee, Chia-Hao; Pinshane, Huang; Clark, Bryan |
| 63 |
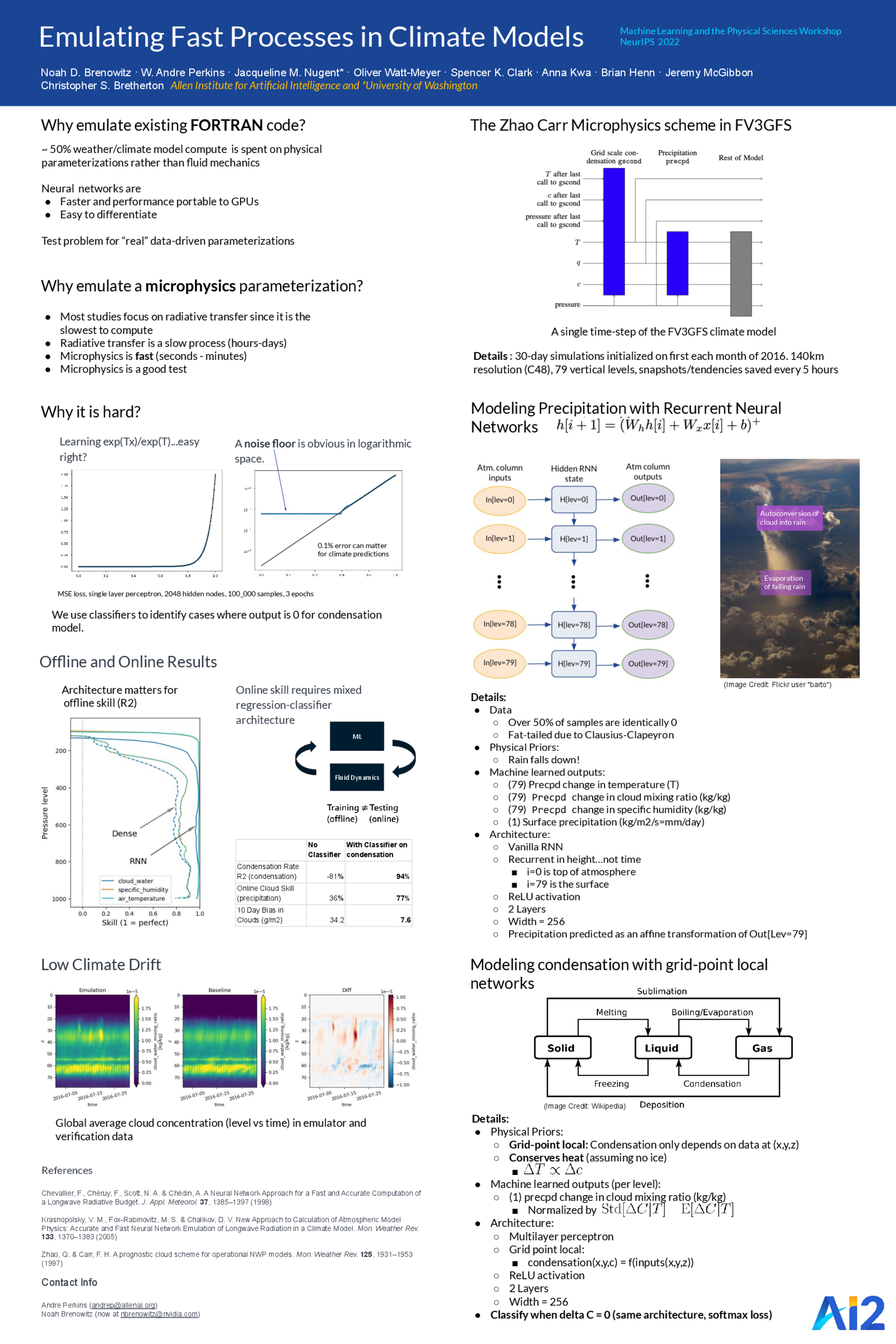
Emulating Fast Processes in Climate Models [paper] [poster]
[event]
Brenowitz,
Noah D*; Perkins, W. Andre; Nugent, Jacqueline M.; Watt-Meyer, Oliver; Clark,
Spencer K.; Kwa, Anna; Henn, Brian; McGibbon, Jeremy; Bretherton, Christopher S.
|
| 64 |
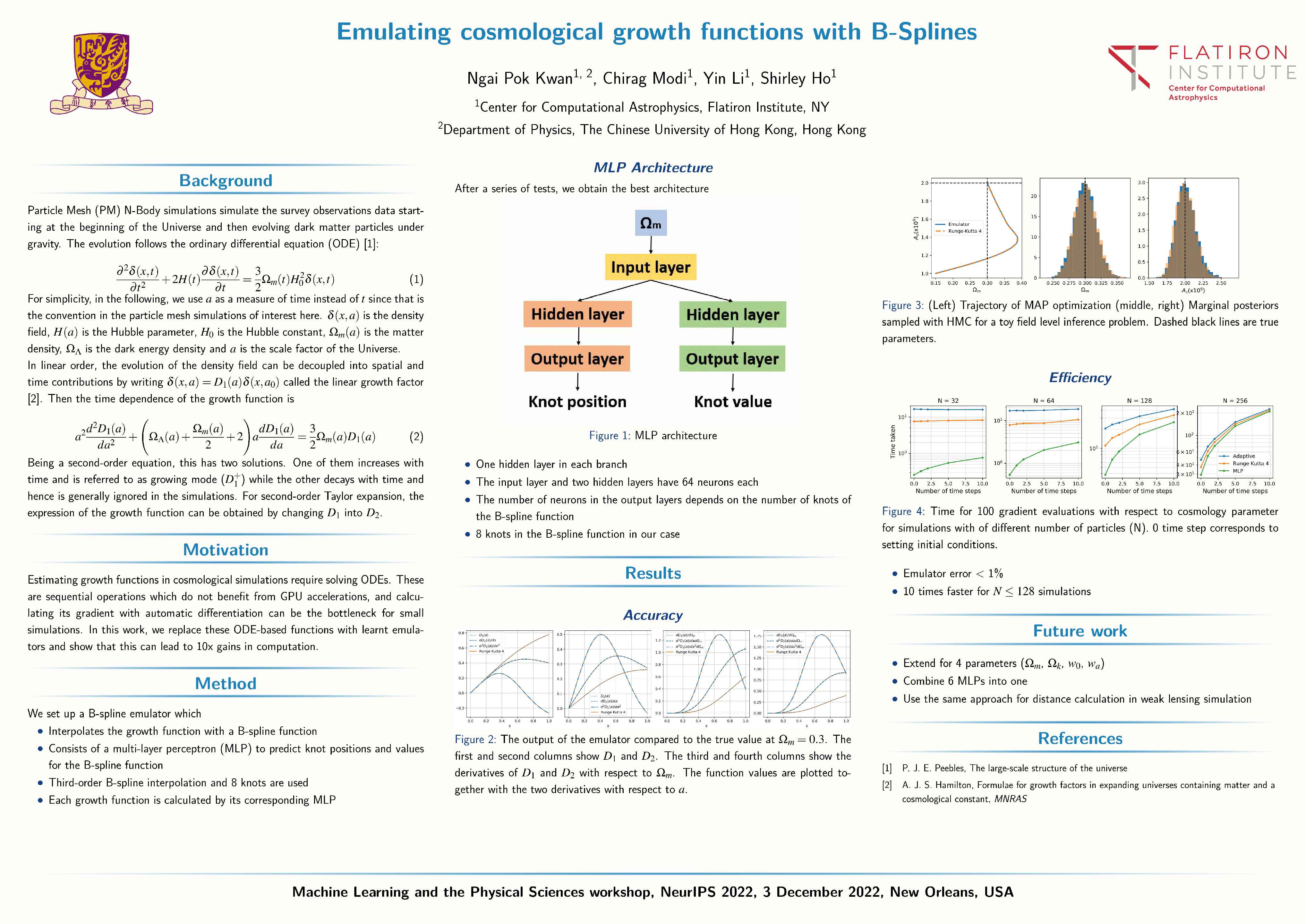
Emulating cosmological growth functions with B-Splines [paper] [poster]
[event]
Kwan, Ngai
Pok*; Modi, Chirag; Li, Yin; Ho, Shirley |
| 65 |
Emulating cosmological multifields with generative adversarial networks
[paper] [poster]
[event]
Andrianomena,
Sambatra HS*; Hassan, Sultan; Villaescusa-Navarro, Francisco |
| 66 |
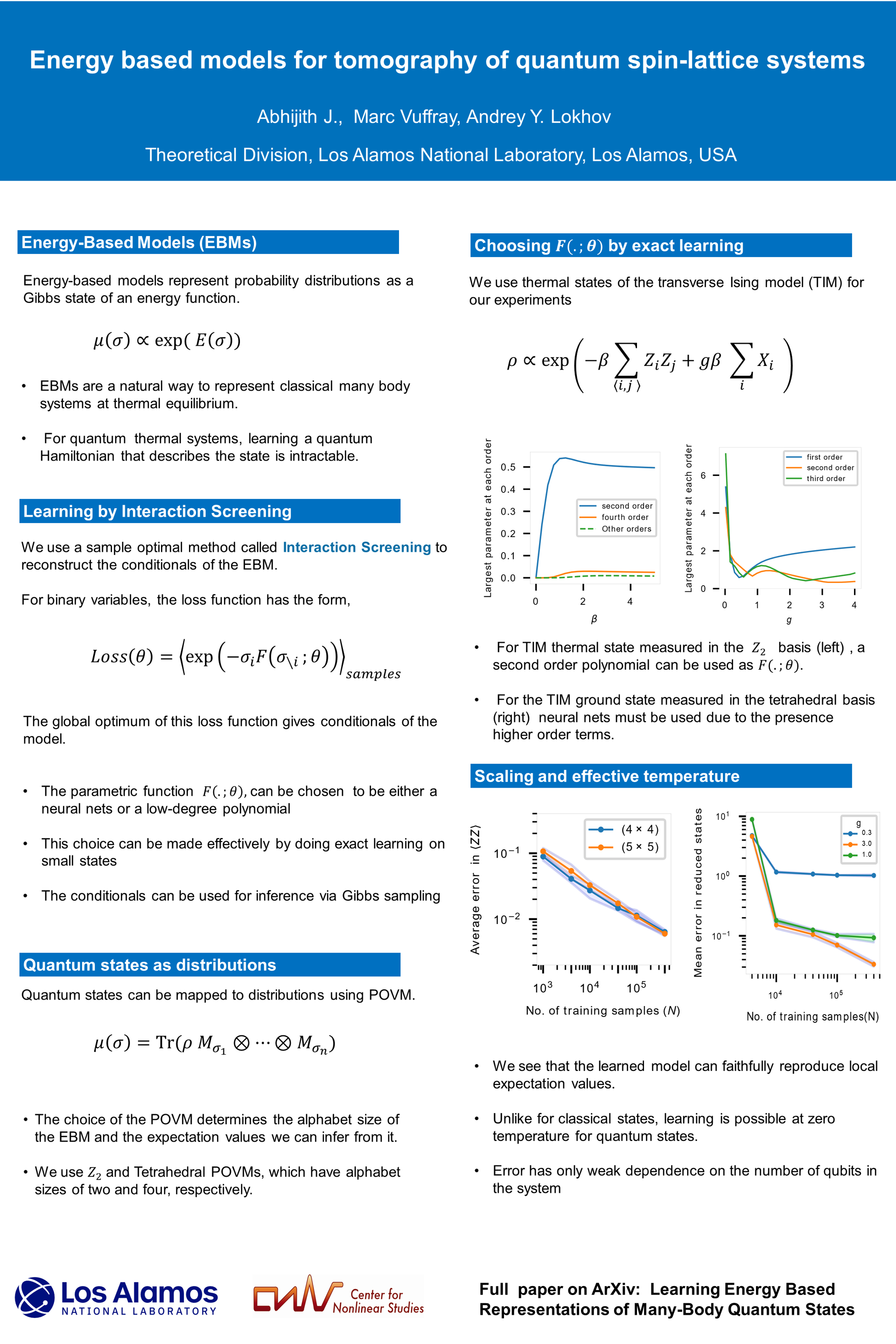
Energy based models for tomography of quantum spin-lattice systems [paper] [poster]
[event]
J.,
Abhijith*; Vuffray, Marc D; Lokhov, Andrey |
| 67 |
FO-PINNs: A First-Order formulation for Physics~Informed Neural Networks
[paper] [poster]
[event]
Gladstone,
Rini Jasmine*; Nabian, Mohammad Amin; Meidani, Hadi |
| 68 |
Fast kinematics modeling for conjunction with lens image modeling [paper] [poster]
[event]
Gomer,
Matthew R*; Biggio, Luca; Ertl, Sebastian; Wang, Han; Galan, Aymeric; Van de
Vyvere, Lyne; Sluse, Dominique; Vernardos, Georgios; Suyu, Sherry |
| 69 |
Finding NEEMo: Geometric Fitting using Neural Estimation of the Energy
Mover’s Distance [paper]
[poster]
[event]
Kitouni,
Ouail*; Williams, Mike; Nolte, Niklas |
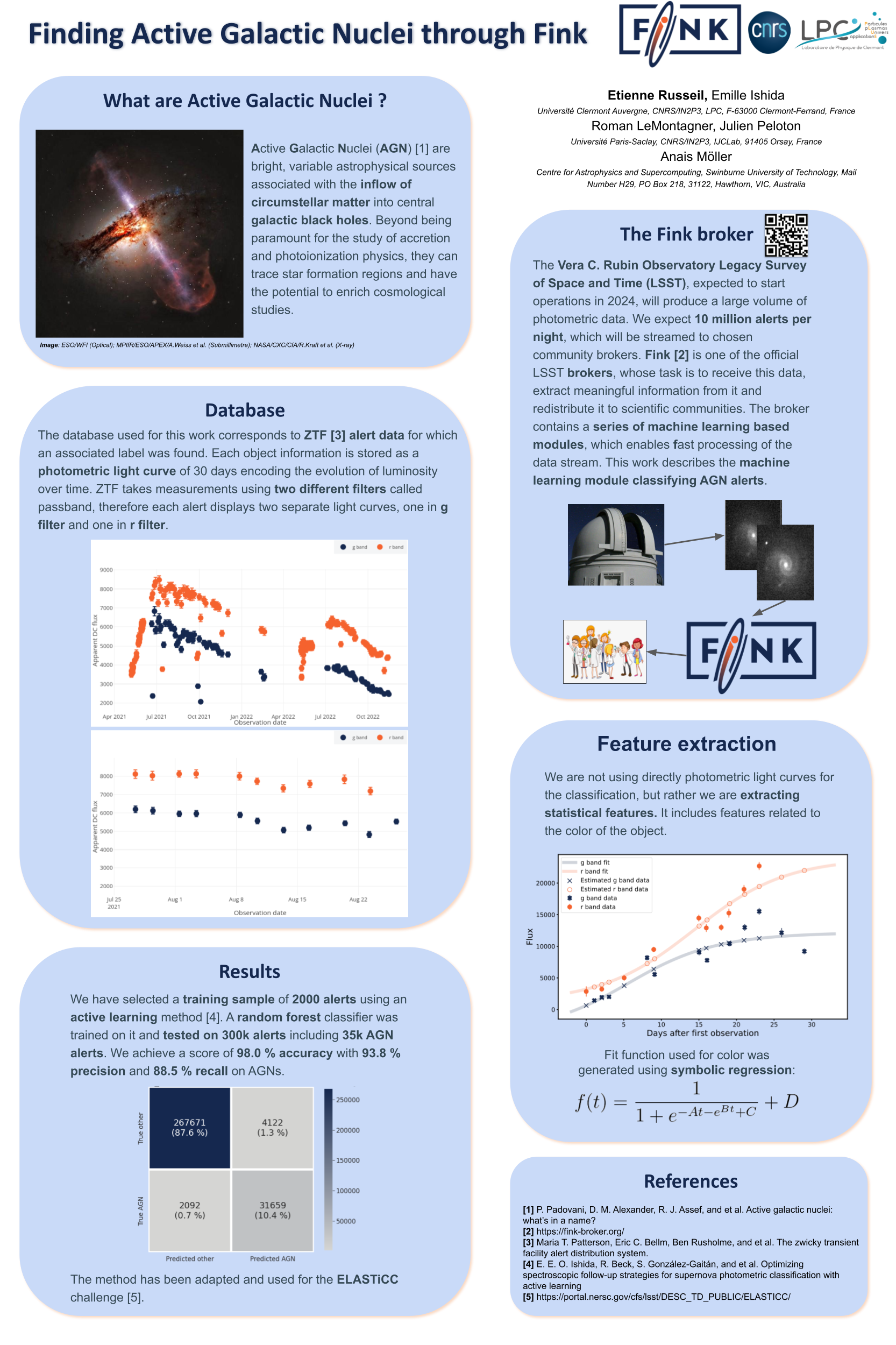
| 70 |
Finding active galactic nuclei through Fink [paper] [poster]
[event]
Russeil,
Etienne Sédick*; Ishida, Emille; Peloton, Julien; Moller, Anais; Le Montagner,
Roman |
| 71 |
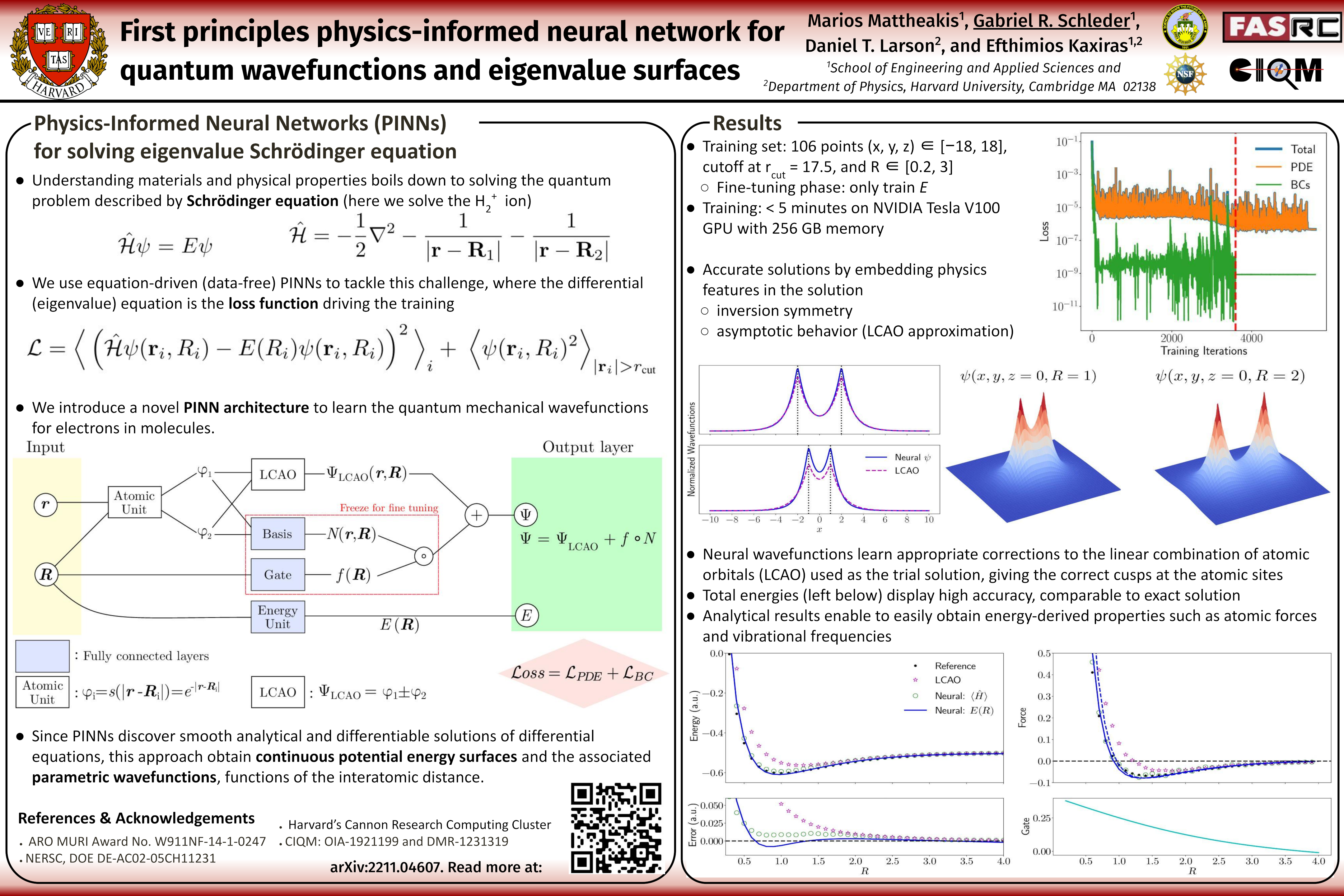
First principles physics-informed neural network for quantum wavefunctions
and eigenvalue surfaces [paper] [poster]
[event]
Mattheakis,
Marios*; Schleder, Gabriel R; Larson, Daniel; Kaxiras, Efthimios |
| 72 |
Flexible learning of quantum states with generative query neural networks
[event]
Zhu, Yan;
Wu, Ya-Dong*; Bai, Ge; Wang, Dong-Sheng; Wang, Yuexuan; Chiribella, Giulio |
| 73 |
From Particles to Fluids: Dimensionality Reduction for Non-Maxwellian Plasma
Velocity Distributions Validated in the Fluid Context [paper] [poster]
[event]
da Silva,
Daniel E* |
| 74 |
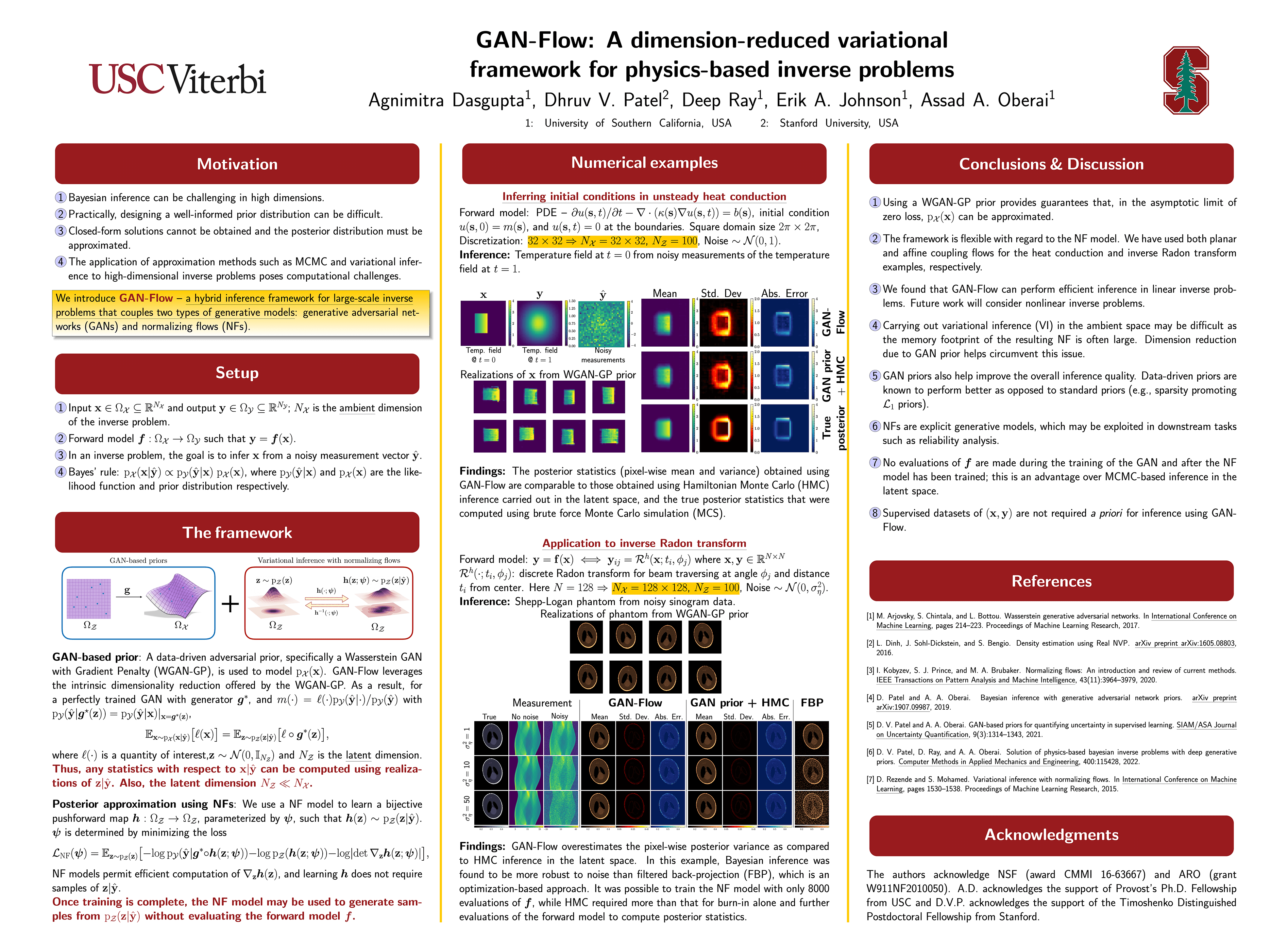
GAN-Flow: A dimension-reduced variational framework for physics-based inverse
problems [paper] [poster]
[event]
Dasgupta,
Agnimitra*; Patel, Dhruv; Ray, Deep; Johnson, Erik; Oberai, Assad |
| 75 |
GAUCHE: A Library for Gaussian Processes in Chemistry [paper] [poster]
[video]
[event]
Griffiths,
Ryan-Rhys*; Klarner, Leo; Moss, Henry B; Ravuri, Aditya; Truong, Sang; Rankovic,
Bojana; Du, Yuanqi; Jamasb, Arian R.; Schwartz, Julius; Tripp, Austin J; Kell,
Gregory; Bourached, Anthony; Chan, Alex J; Moss, Jacob; Guo, Chengzhi; Lee,
Alpha; Schwaller, Philippe; Tang, Jian |
| 76 |
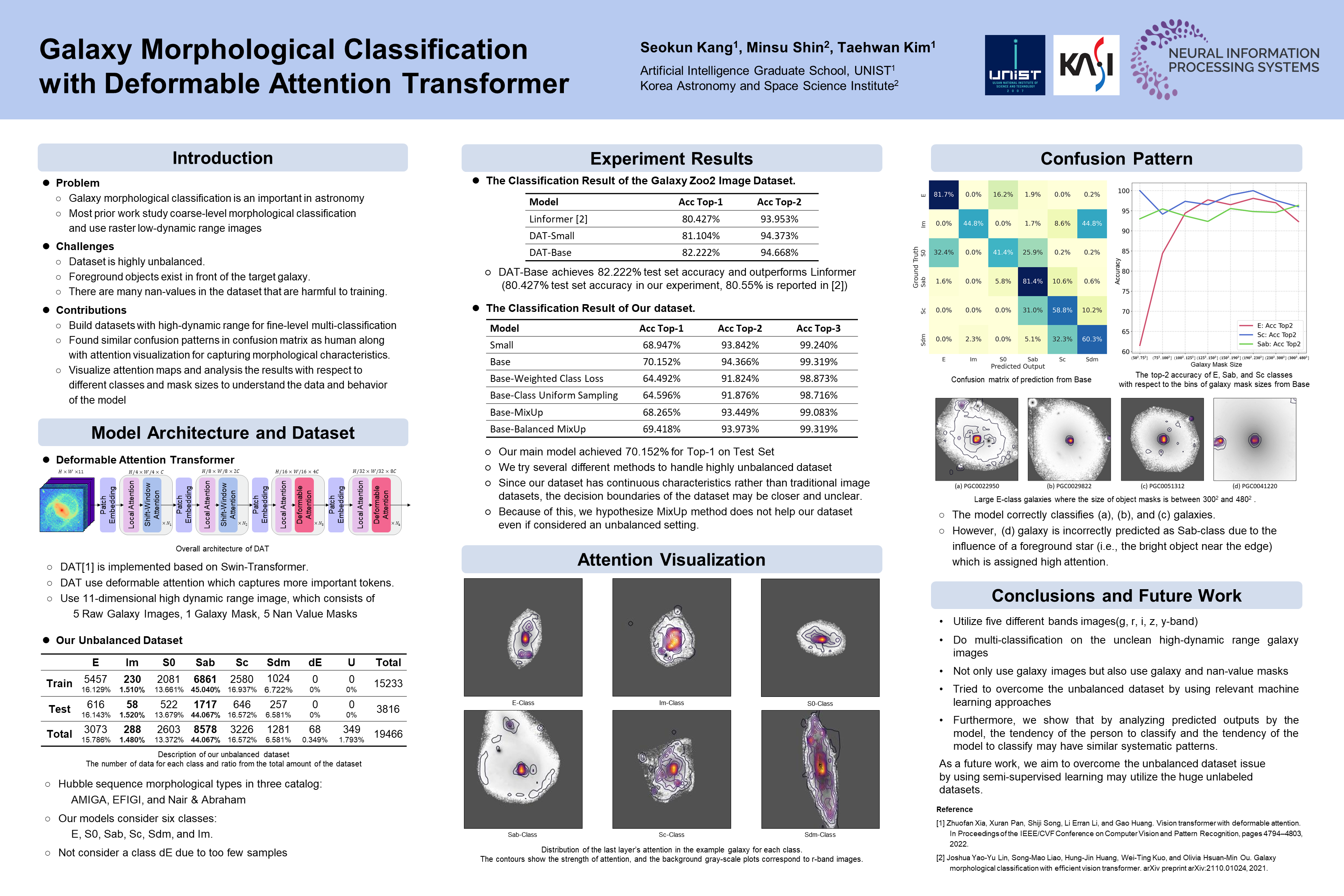
Galaxy Morphological Classification with Deformable Attention Transformer
[paper] [poster]
[event]
KANG,
SEOKUN; Shin, Min-su; Kim, Taehwan* |
| 77 |
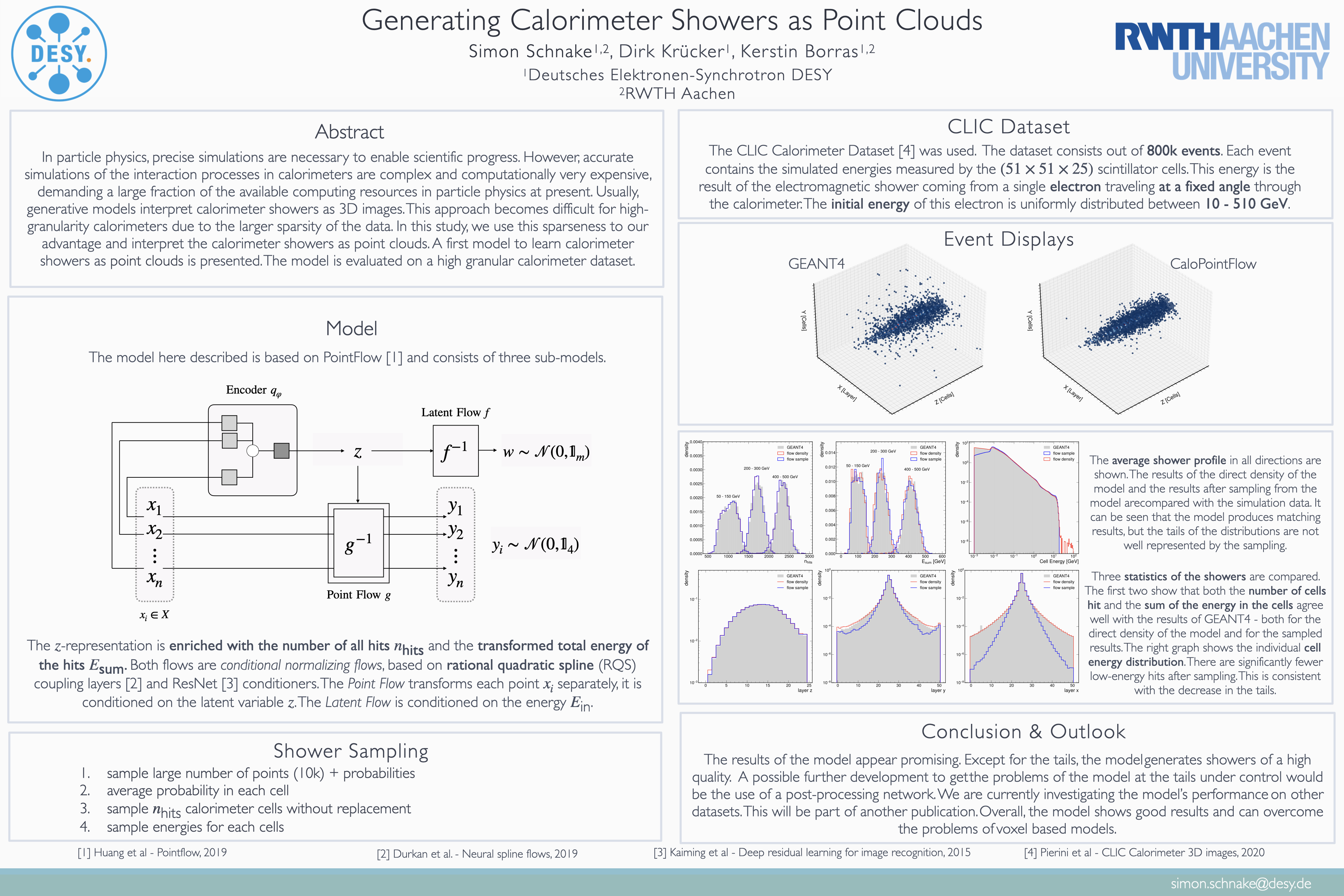
Generating Calorimeter Showers as Point Clouds [paper] [poster]
[event]
Schnake,
Simon Patrik*; Krücker, Dirk; Borras, Kerstin |
| 78 |
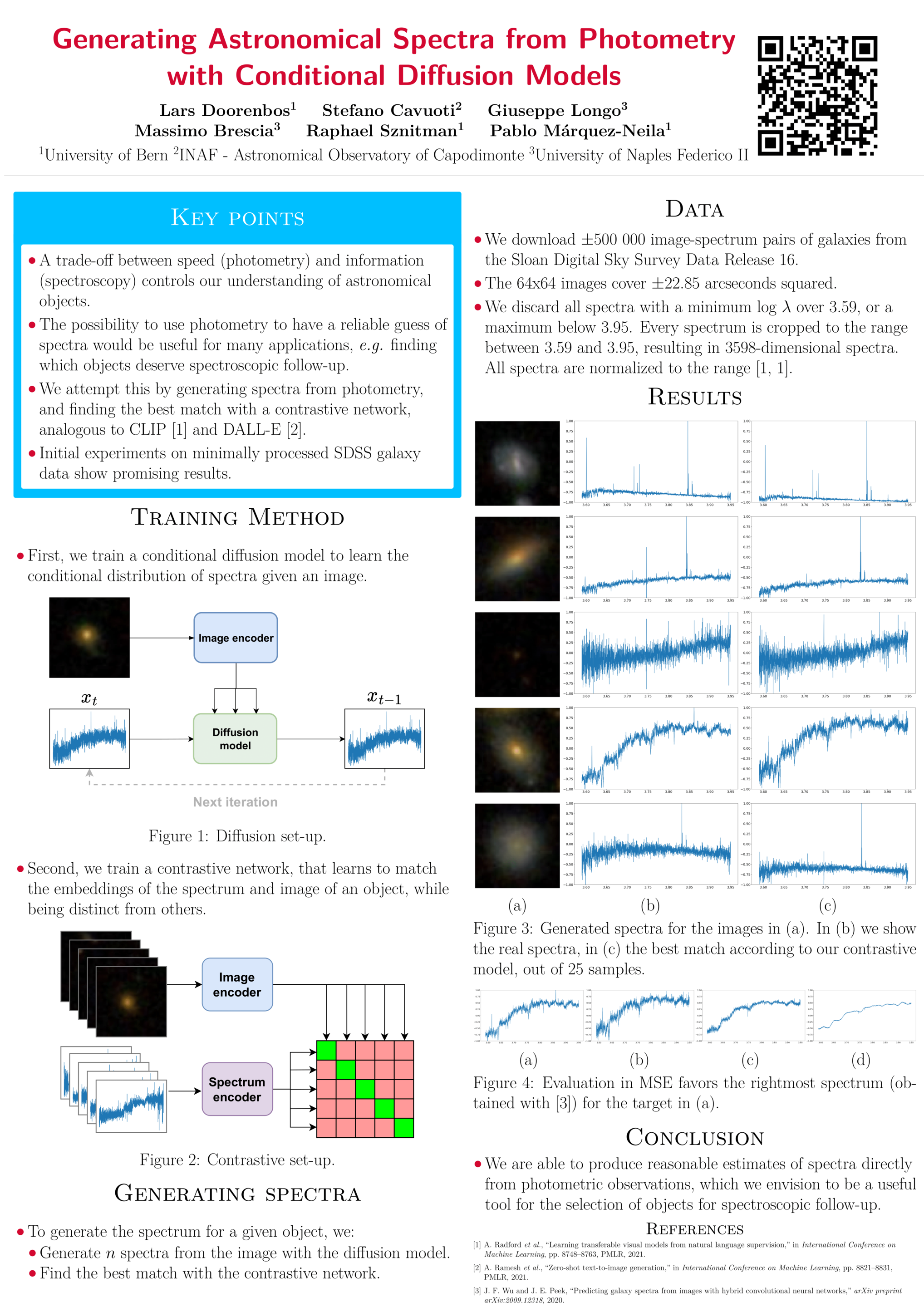
Generating astronomical spectra from photometry with conditional diffusion
models [paper] [poster]
[event]
Doorenbos,
Lars*; Cavuoti, Stefano; Longo, Giuseppe; Brescia, Massimo; Sznitman, Raphael;
Márquez Neila, Pablo |
| 79 |
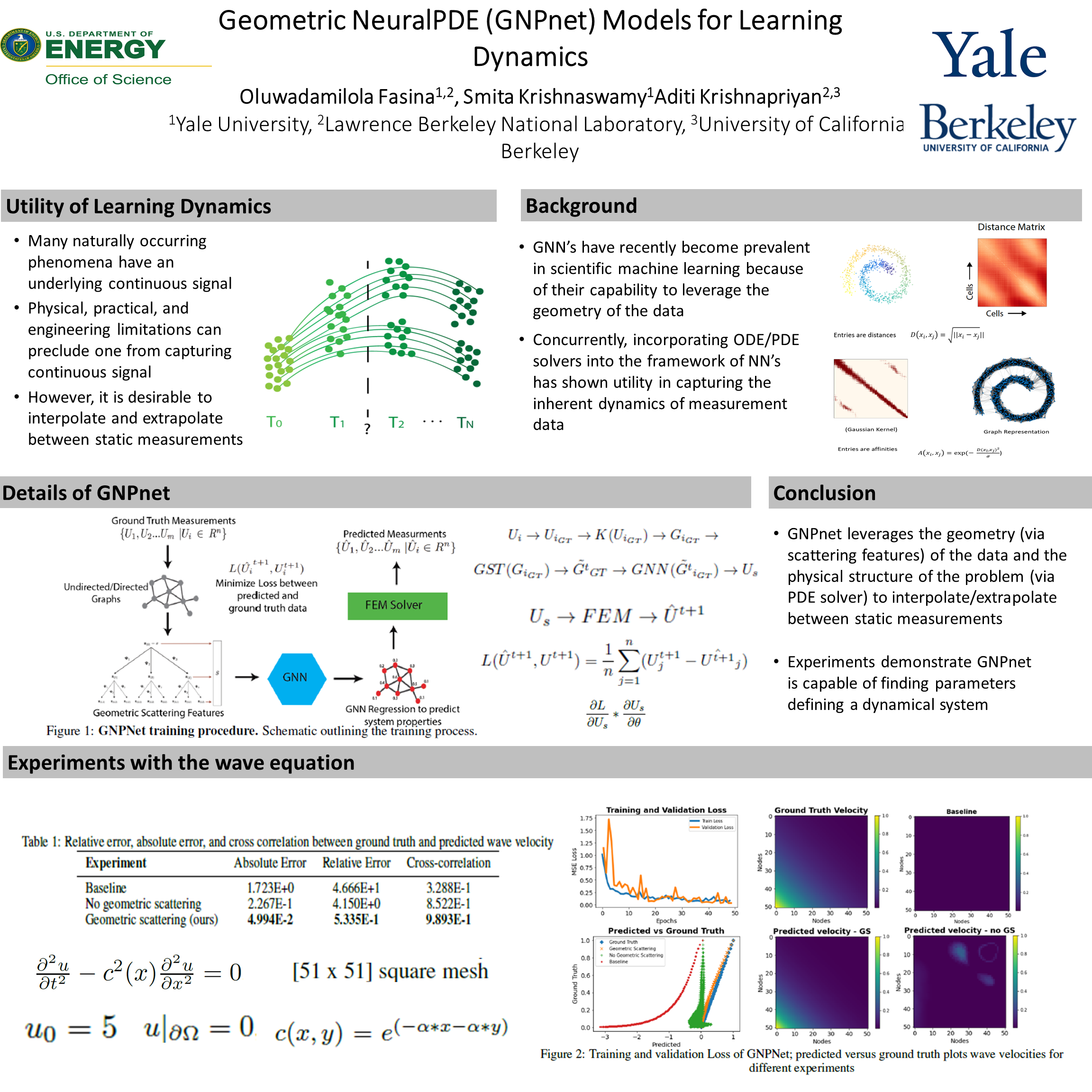
Geometric NeuralPDE (GNPnet) Models for Learning Dynamics [paper] [poster]
[event]
Fasina,
Oluwadamilola Fasina*; Krishnaswamy, Smita; Krishnapriyan, Aditi |
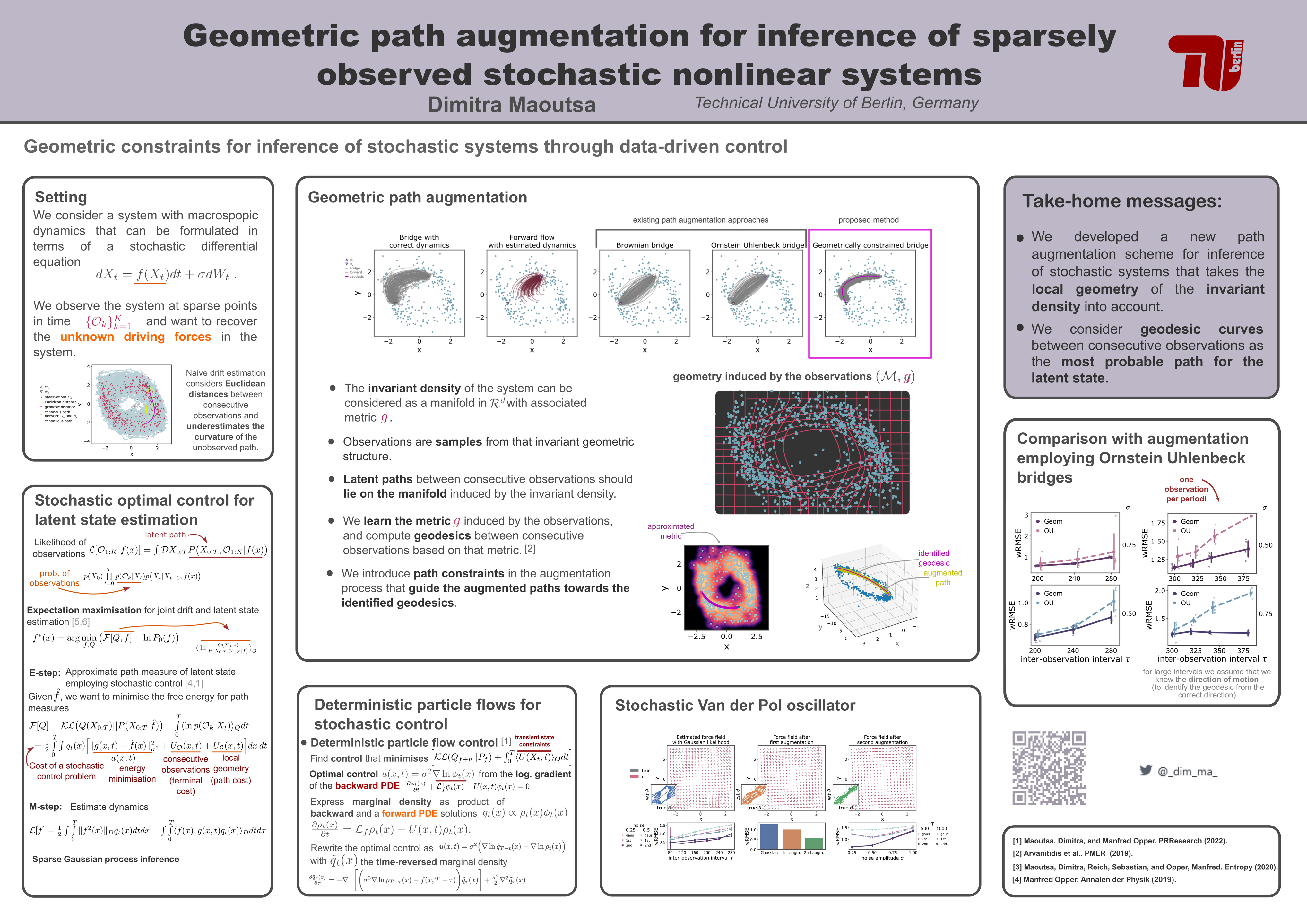
| 80 |
Geometric path augmentation for inference of sparsely observed stochastic
nonlinear systems [paper]
[poster]
[event]
Maoutsa,
Dimitra* |
| 81 |
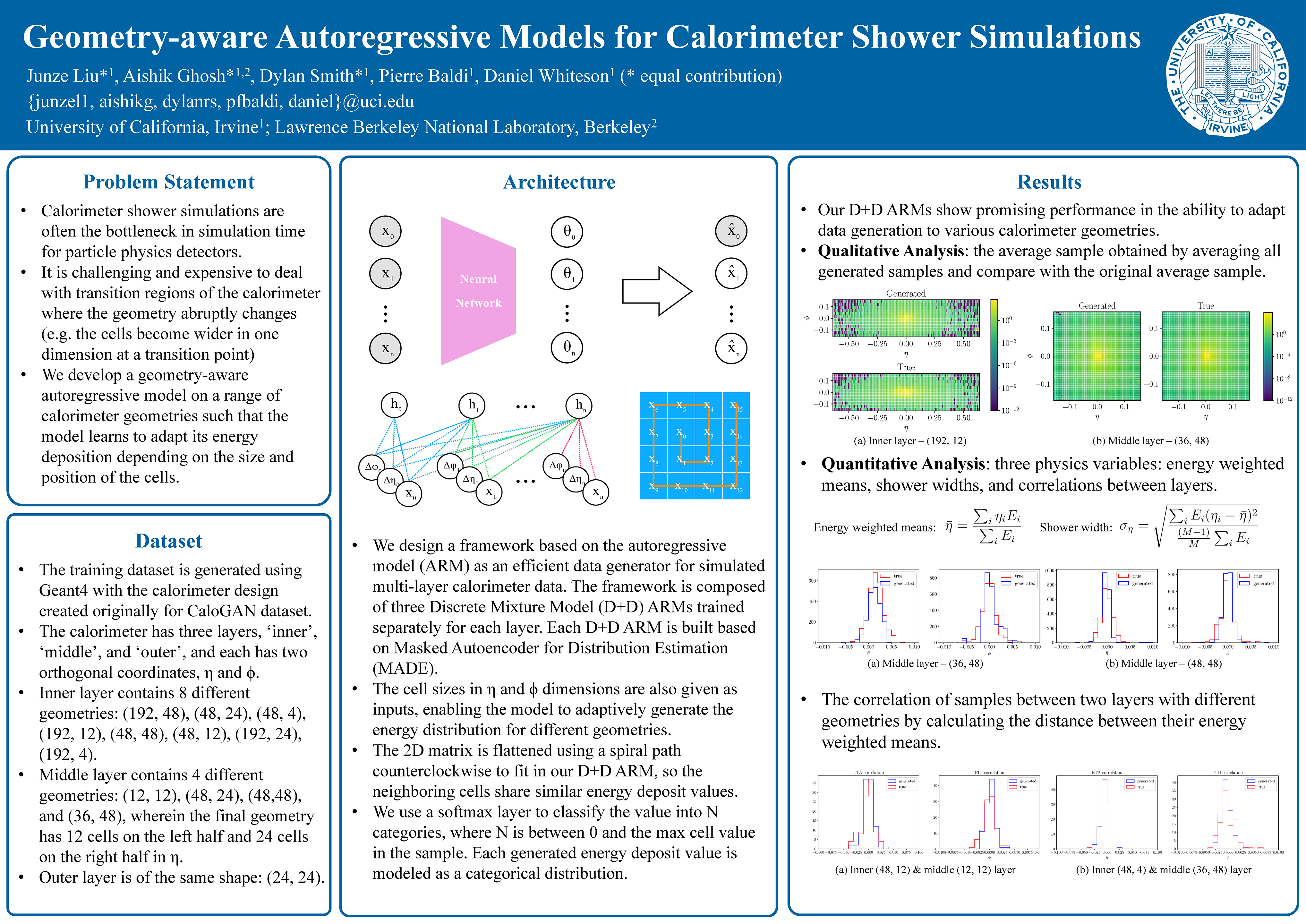
Geometry-aware Autoregressive Models for Calorimeter Shower Simulations
[paper] [poster]
[event]
Liu,
Junze*; Ghosh, Aishik; Smith, Dylan; Baldi, Pierre; Whiteson, Daniel |
| 82 |
Graph Structure from Point Clouds: Geometric Attention is All You Need
[paper] [poster]
[event]
Murnane,
Daniel* |
| 83 |
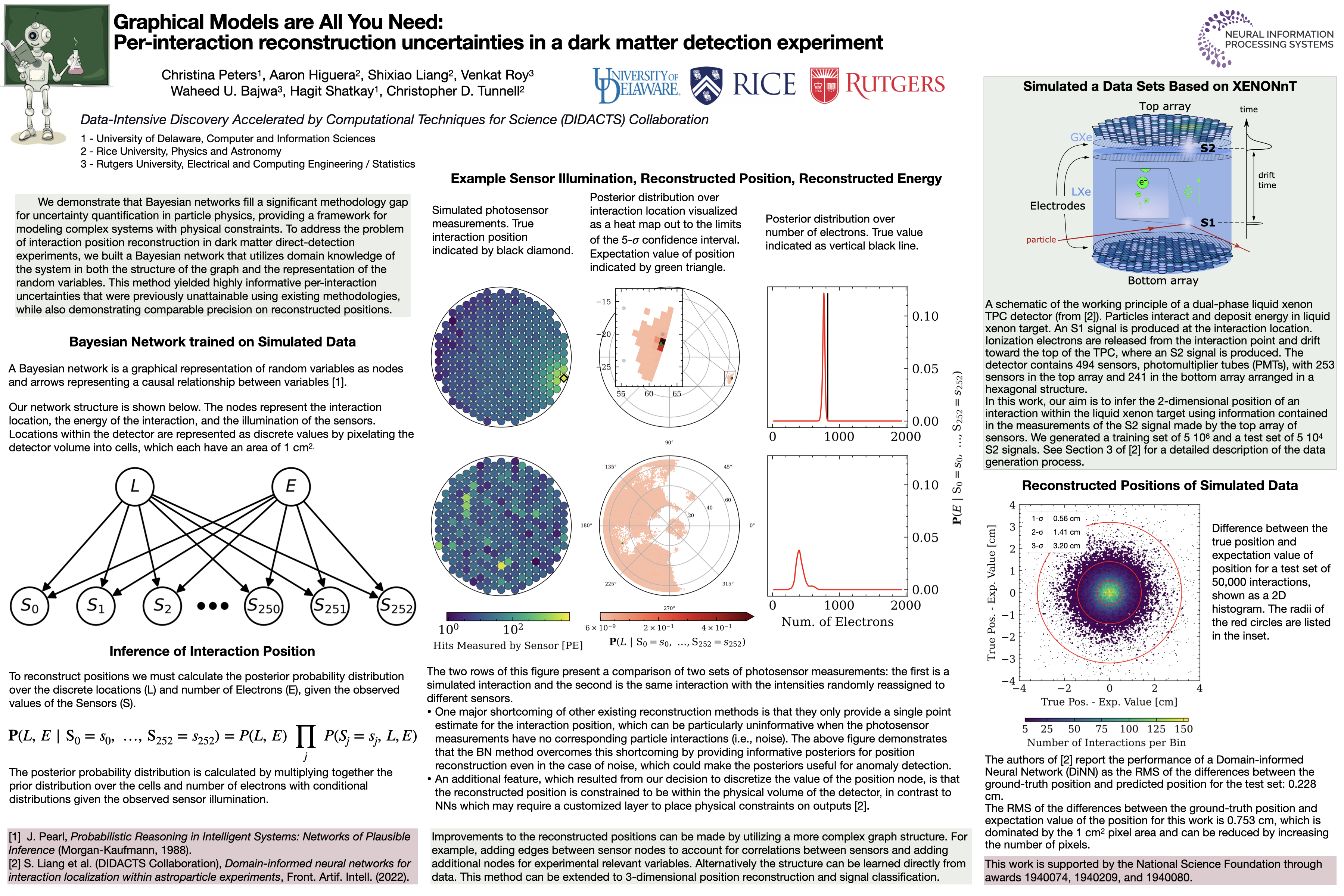
Graphical Models are All You Need: Per-interaction reconstruction
uncertainties in a dark matter detection experiment [paper] [poster]
[event]
Peters,
Christina*; Higuera, Aaron; Liang, Shixiao; Bajwa, Waheed; Tunnell, Christopher
|
| 84 |
HGPflow: Particle reconstruction as hyperedge prediction [paper] [poster]
[event]
Dreyer,
Etienne*; Kakati, Nilotpal; Armando Di Bello, Francesco |
| 85 |
HIGlow: Conditional Normalizing Flows for High-Fidelity HI Map Modeling
[paper] [poster]
[event]
Friedman,
Roy*; Hassan, Sultan SH |
| 86 |
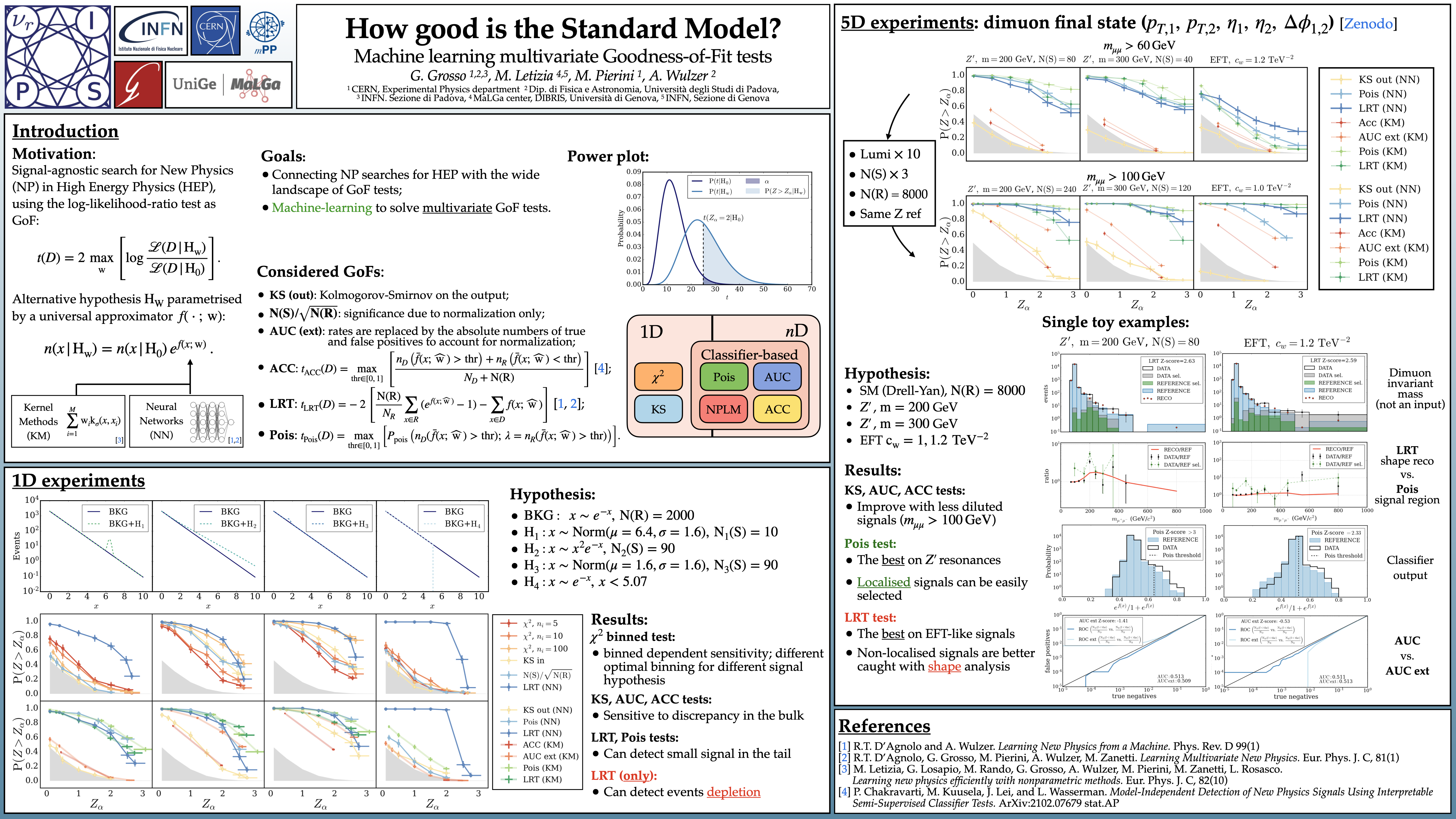
How good is the Standard Model? Machine learning multivariate Goodness of Fit
tests [paper] [poster]
[event]
Grosso,
Gaia*; Letizia, Marco; Wulzer, Andrea; Pierini, Maurizio |
| 87 |
HubbardNet: Efficient Predictions of the Bose-Hubbard Model Spectrum with
Deep Neural Networks [paper] [poster]
[event]
Zhu ,
Ziyan*; Mattheakis, Marios; Pan, Weiwei; Kaxiras, Efthimios |
| 88 |
Hybrid integration of the gravitational N-body problem with Artificial Neural
Networks [paper] [poster]
[event]
Saz
Ulibarrena, Veronica*; Portegies Zwart, Simon F; Sellentin, Elena; Koren, Barry;
Horn, Philipp; Cai, Maxwell |
| 89 |
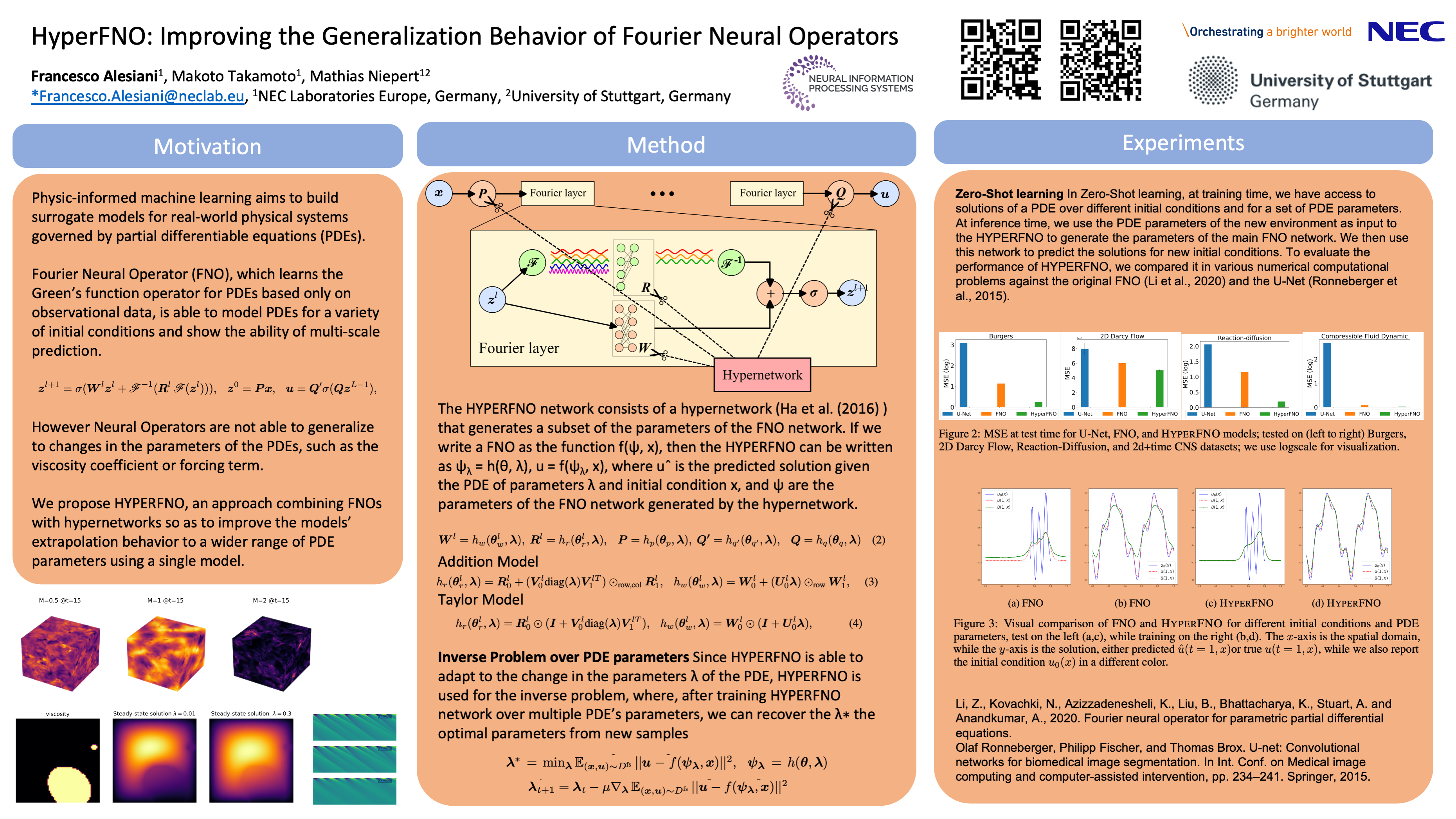
HyperFNO: Improving the Generalization Behavior of Fourier Neural
Operators [paper] [poster]
[event]
Alesiani,
Francesco*; Takamoto, Makoto; Niepert, Mathias |
| 90 |
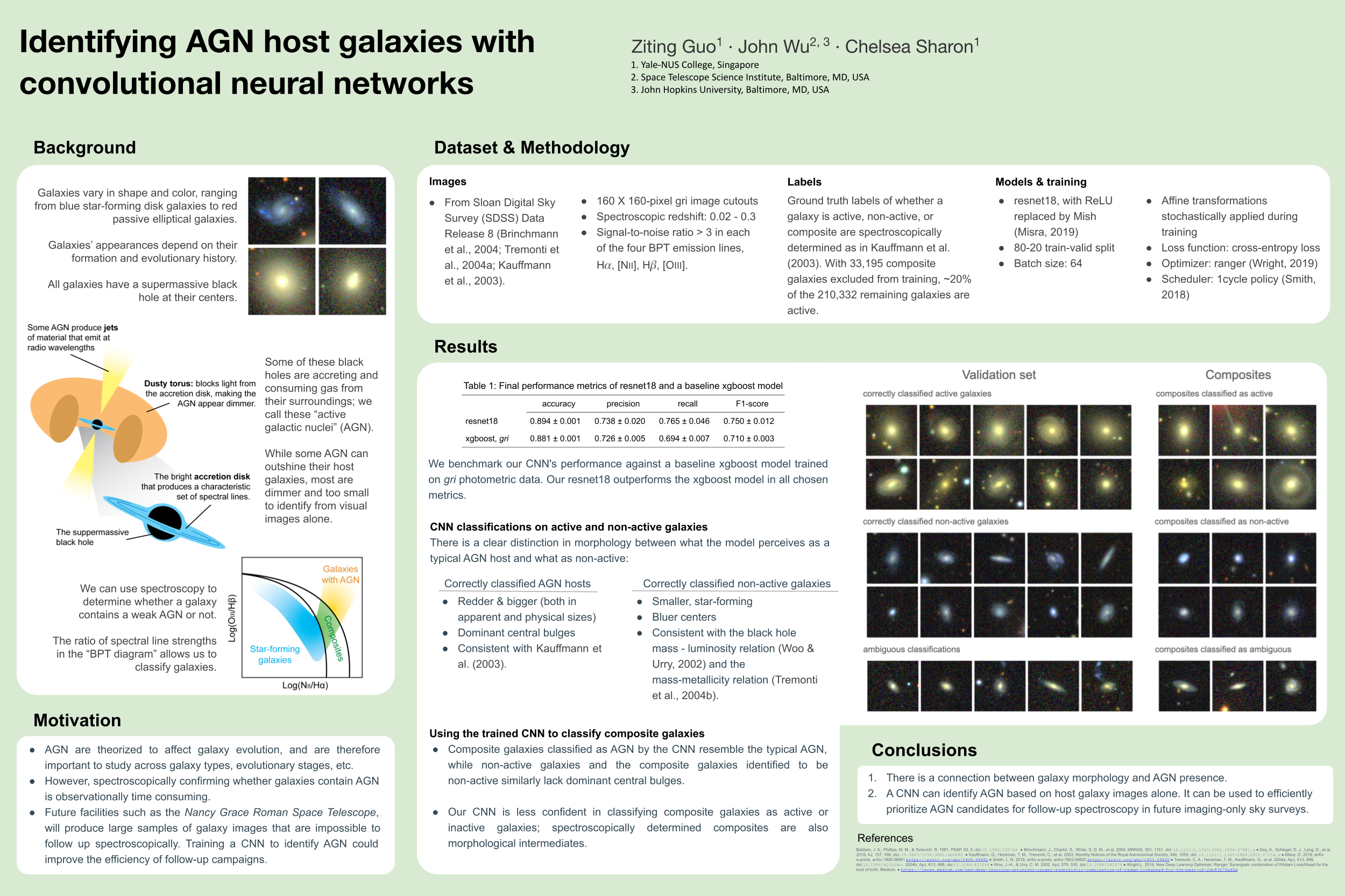
Identifying AGN host galaxies with convolutional neural networks [paper] [poster]
[event]
Guo,
Ziting*; Wu, John; Sharon, Chelsea |
| 91 |
Identifying Hamiltonian Manifold in Neural Networks [paper] [poster]
[event]
Song,
Yeongwoo; Jeong, Hawoong* |
| 92 |
Improved Training of Physics-informed Neural Networks using Energy-Based
priors: A Study on Electrical Impedance Tomography [paper] [poster]
[event]
Pokkunuru,
Akarsh*; Rooshenas, Pedram; Strauss, Thilo; Abhishek, Anuj; Khan, Taufiquar R
|
| 93 |
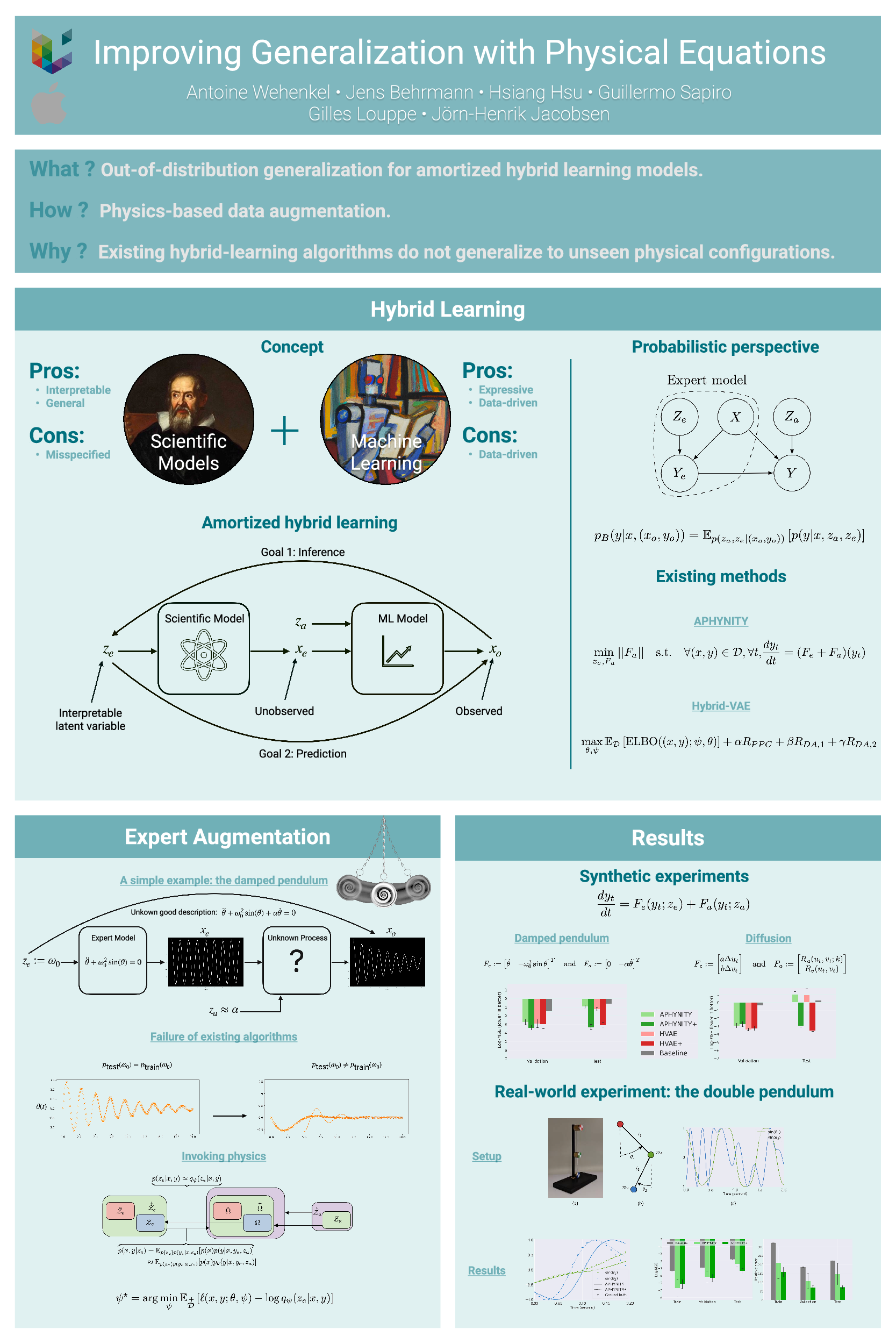
Improving Generalization with Physical Equations [paper] [poster]
[event]
Wehenkel,
Antoine*; Behrmann, Jens; Hsu, Hsiang; Sapiro, Guillermo; Louppe, Gilles;
Jacobsen, Joern-Henrik |
| 94 |
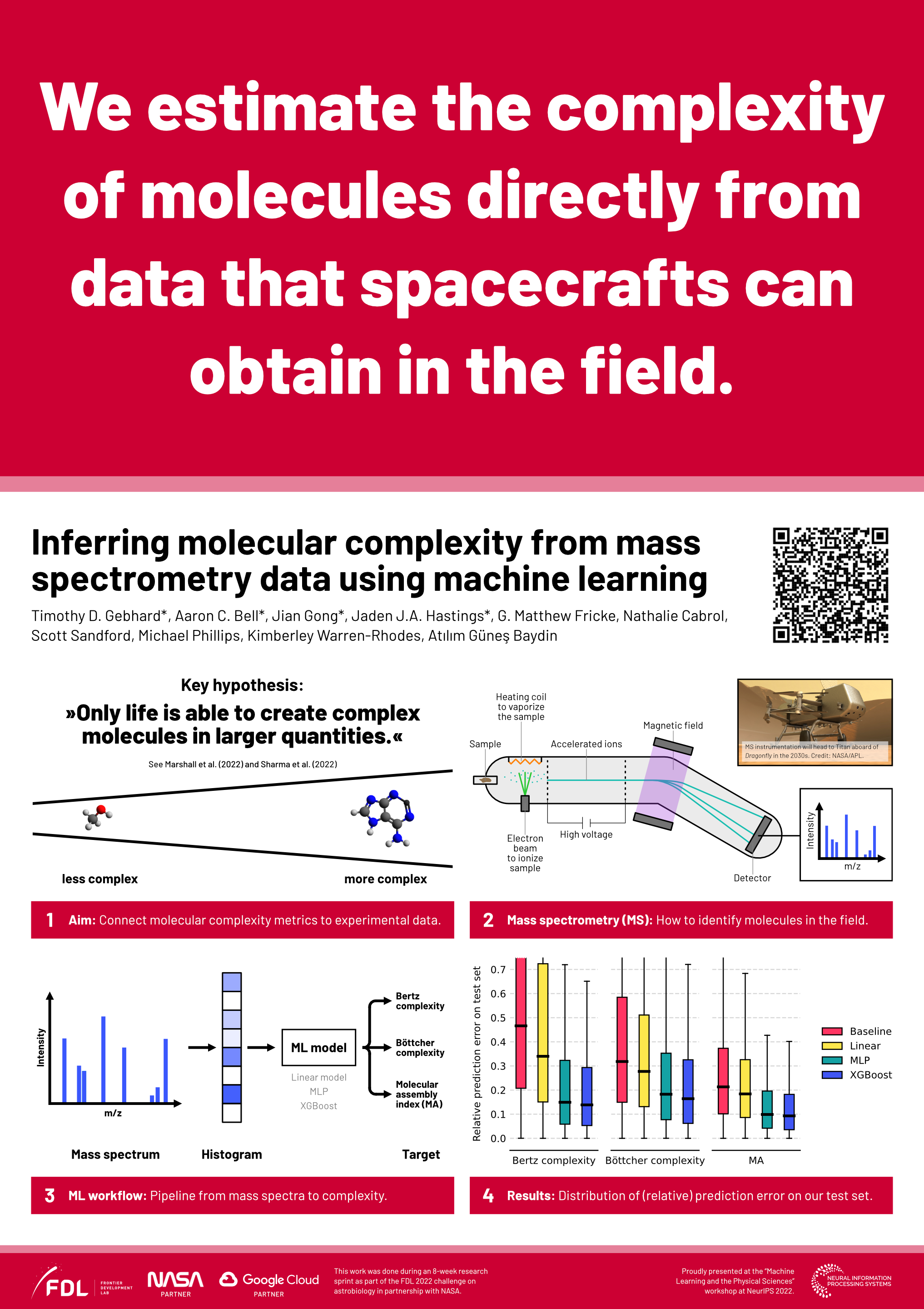
Inferring molecular complexity from mass spectrometry data using machine
learning [paper] [poster]
[event]
Gebhard,
Timothy D*; Bell, Aaron; Gong, Jian; Hastings, Jaden J. A.; Fricke, George M;
Cabrol, Nathalie; Sandford, Scott; Phillips, Michael; Warren-Rhodes, Kimberley;
Baydin, Atilim Gunes |
| 95 |
Insight into cloud processes from unsupervised classification with a
rotation-invariant autoencoder [paper] [poster]
[event]
Kurihana,
Takuya*; Franke, James A; Foster, Ian; Wang, Ziwei; Moyer, Elisabeth |
| 96 |
Interpretable Encoding of Galaxy Spectra [paper] [poster]
[event]
Liang,
Yan*; Melchior, Peter M; Lu, Sicong |
| 97 |
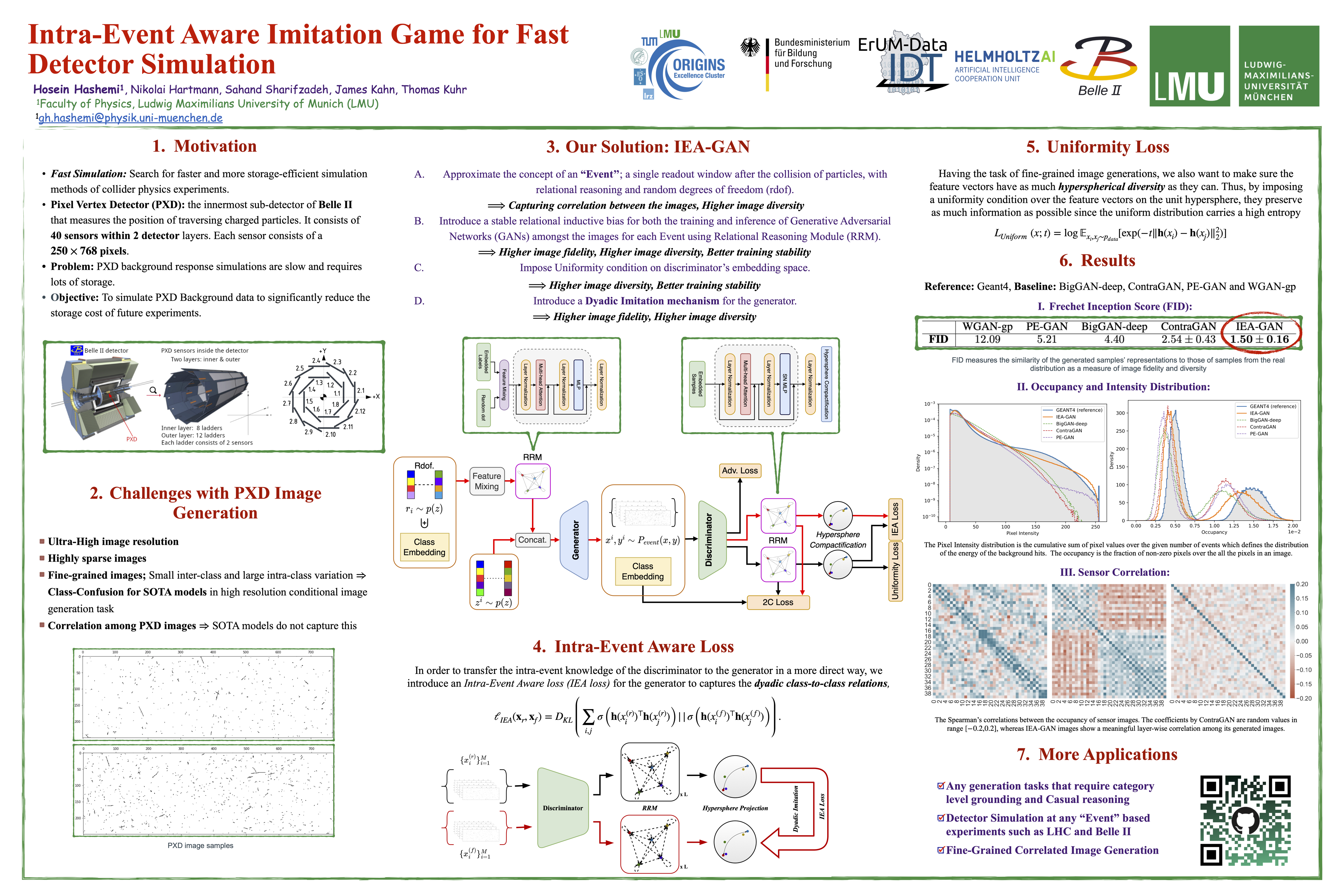
Intra-Event Aware Imitation Game for Fast Detector Simulation [paper] [poster]
[event]
Hashemi,
Hosein*; Hartmann, Nikolai; Sharifzadeh, Sahand; Kahn, James; Kuhr, Thomas |
| 98 |
Learning Electron Bunch Distribution along a FEL Beamline by Normalising
Flows [paper] [poster]
[event]
Willmann,
Anna*; Couperus Cabadağ, Jurjen Pieter; Chang, Yen-Yu; Pausch, Richard; Ghaith,
Amin; Debus, Alexander; Irman, Arie; Bussmann, Michael; Schramm, Ulrich;
Hoffmann, Nico |
| 99 |
Learning Feynman Diagrams using Graph Neural Networks [paper] [poster]
[event]
Norcliffe,
Alexander LI*; Mitchell, Harrison; Lió, Pietro |
| 100 |
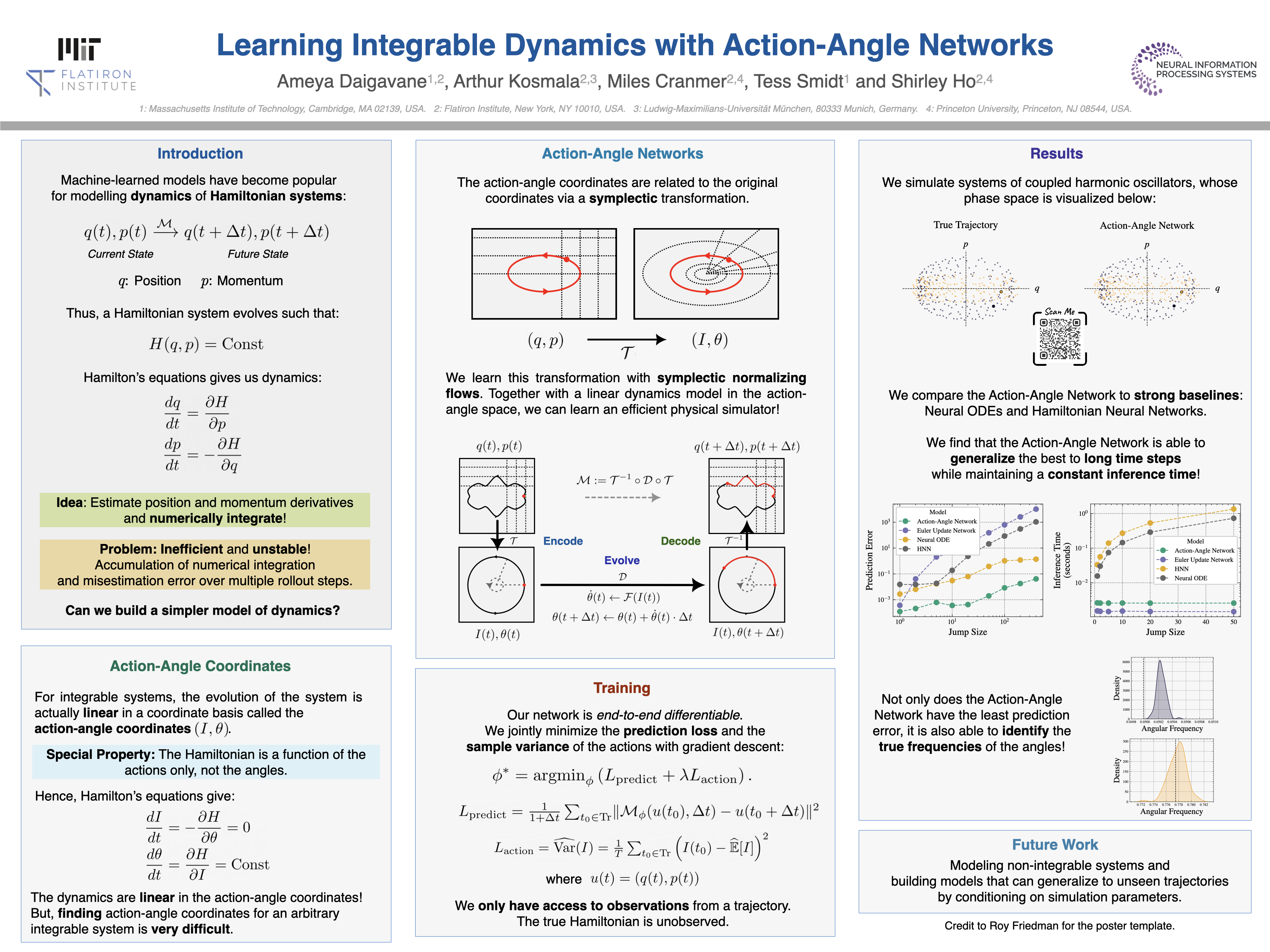
Learning Integrable Dynamics with Action-Angle Networks [paper] [poster]
[event]
Daigavane,
Ameya*; Kosmala, Arthur; Cranmer, Miles; Smidt, Tess; Ho, Shirley |
| 101 |
Learning Similarity Metrics for Volumetric Simulations with Multiscale
CNNs [paper] [poster]
[event]
Kohl,
Georg*; Chen, Liwei; Thuerey, Nils |
| 102 |
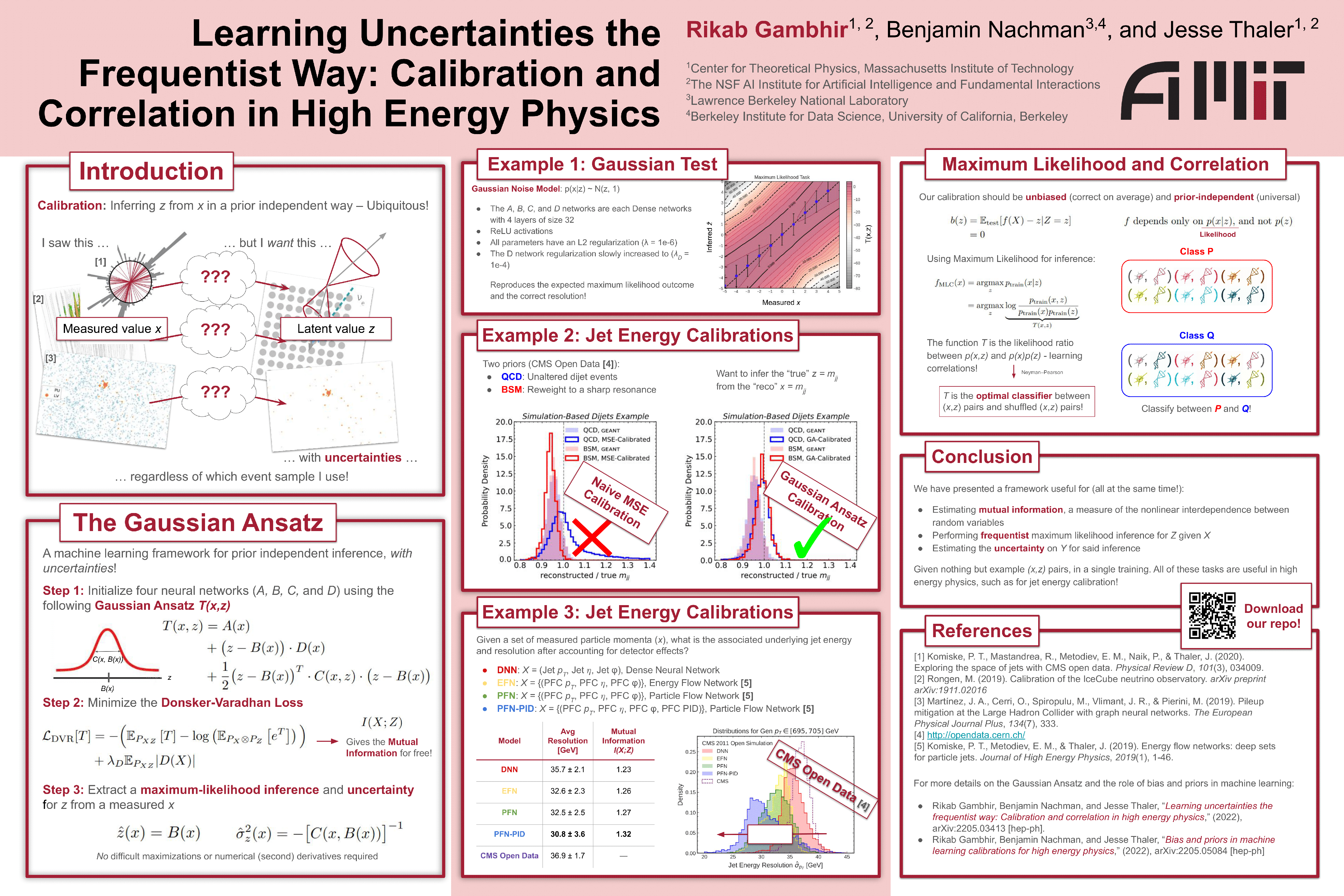
Learning Uncertainties the Frequentist Way: Calibration and Correlation in
High Energy Physics [paper] [poster]
[event]
Gambhir,
Rikab*; Thaler, Jesse; Nachman, Benjamin |
| 103 |
Learning dynamical systems: an example from open quantum system dynamics.
[paper] [event]
Novelli,
Pietro* |
| 104 |
Learning latent variable evolution for the functional renormalization
group [paper] [poster]
[event]
Medvidović,
Matija*; Toschi, Alessandro; Sangiovanni, Giorgio; Franchini, Cesare; Millis,
Andy; Sengupta, Anirvan; Di Sante, Domenico |
| 105 |
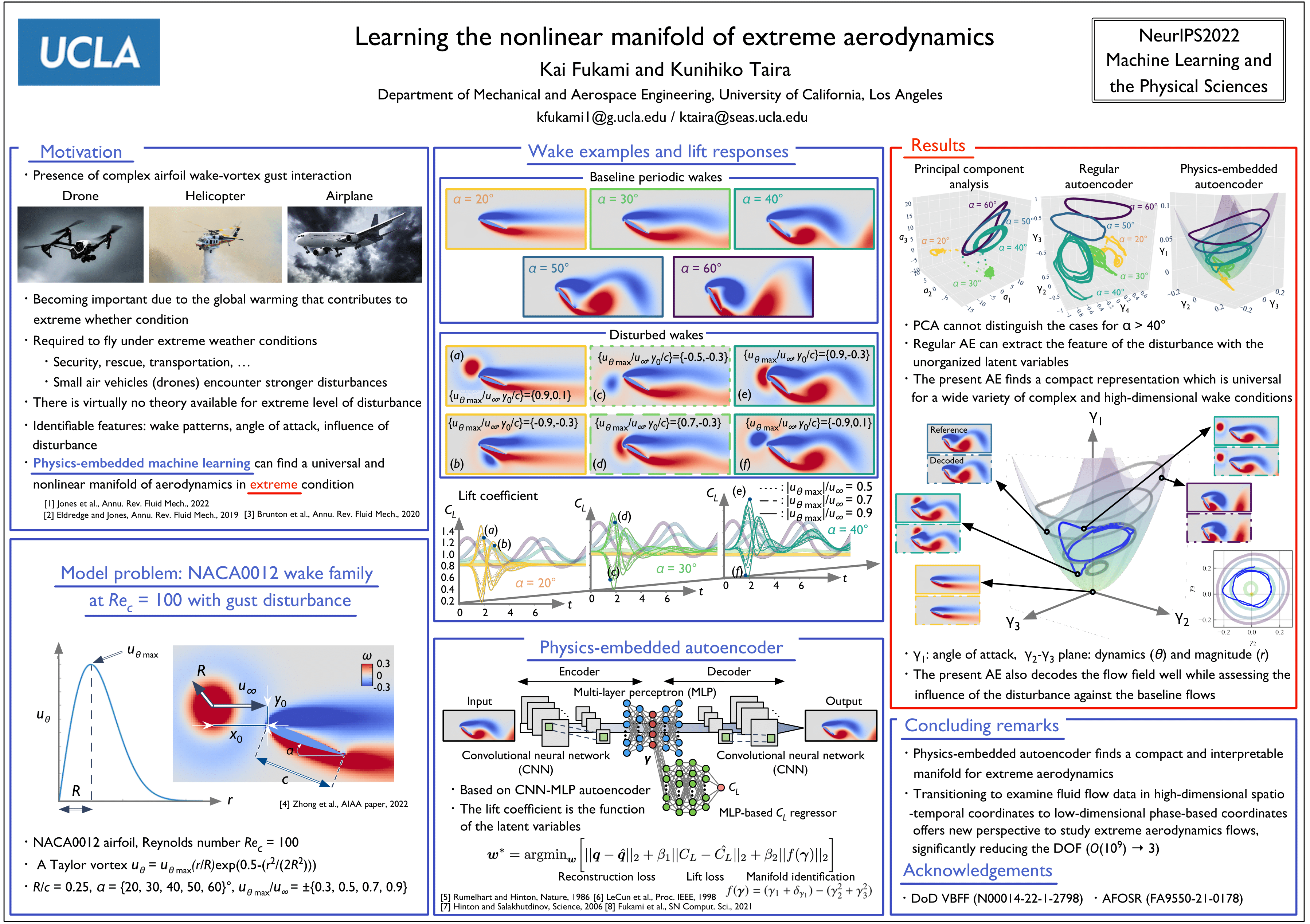
Learning the nonlinear manifold of extreme aerodynamics [paper] [poster]
[event]
Fukami,
Kai*; Taira, Kunihiko |
| 106 |
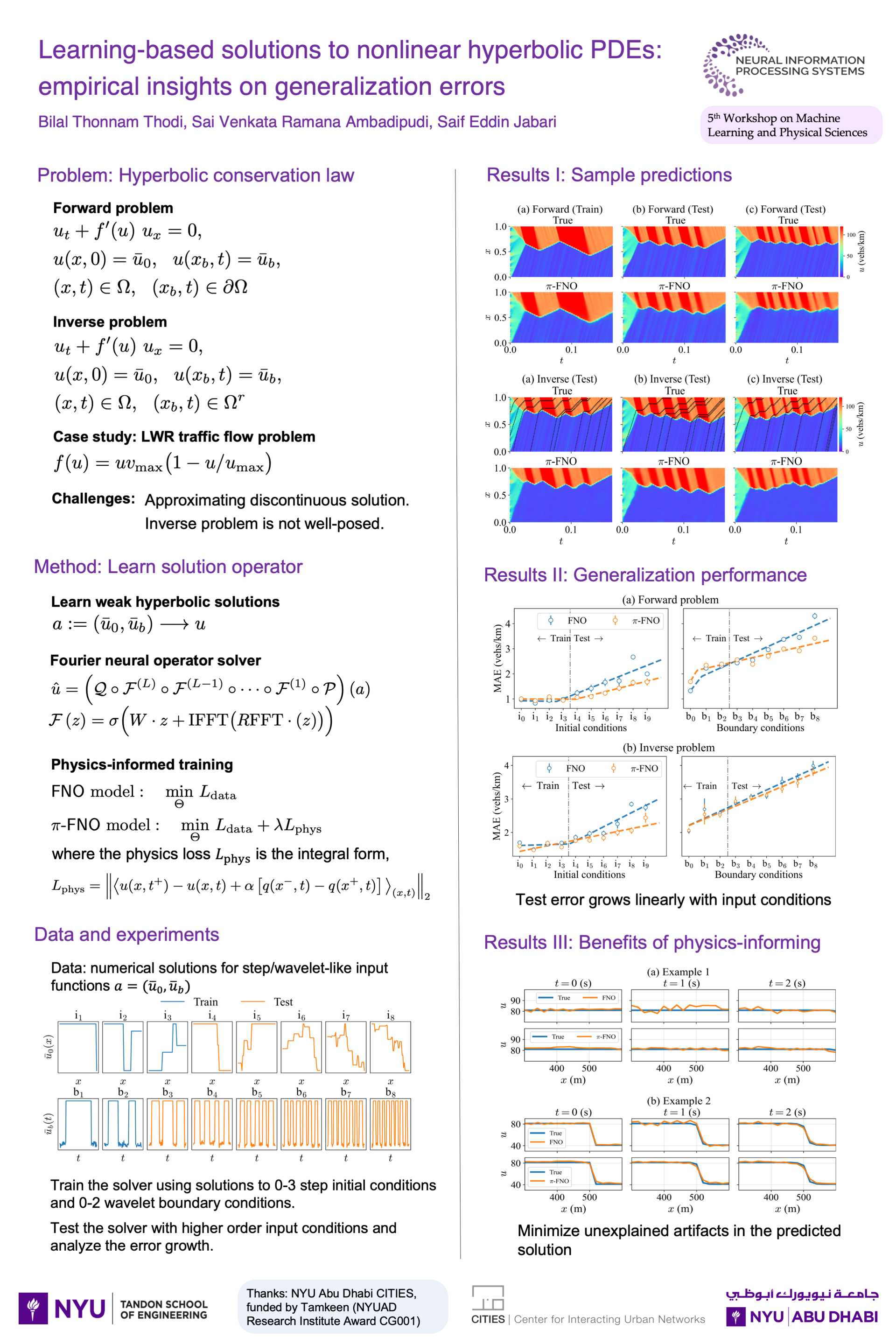
Learning-based solutions to nonlinear hyperbolic PDEs: Empirical insights on
generalization errors [paper] [poster]
[event]
Thonnam
Thodi, Bilal*; Ambadipudi, Sai Venkata Ramana; Jabari, Saif Eddin |
| 107 |
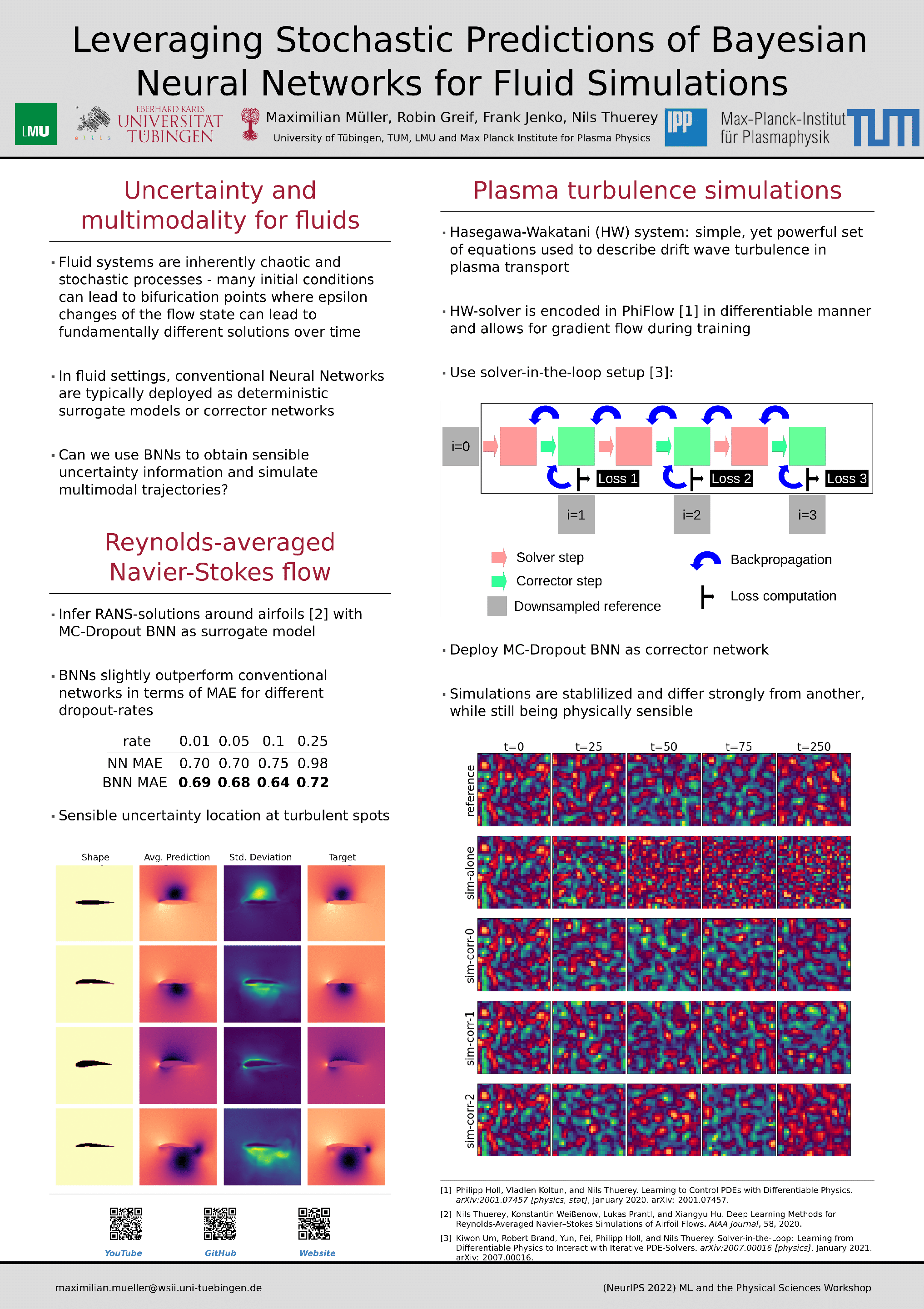
Leveraging the Stochastic Predictions of Bayesian Neural Networks for Fluid
Simulations [paper] [poster]
[event]
Mueller,
Maximilian*; Greif, Robin; Jenko, Frank; Thuerey, Nils |
| 108 |
Likelihood-Free Frequentist Inference for Calorimetric Muon Energy
Measurement in High-Energy Physics [paper] [poster]
[event]
Masserano,
Luca*; Lee, Ann; Izbicki, Rafael; Kuusela, Mikael; Dorigo, Tommaso |
| 109 |
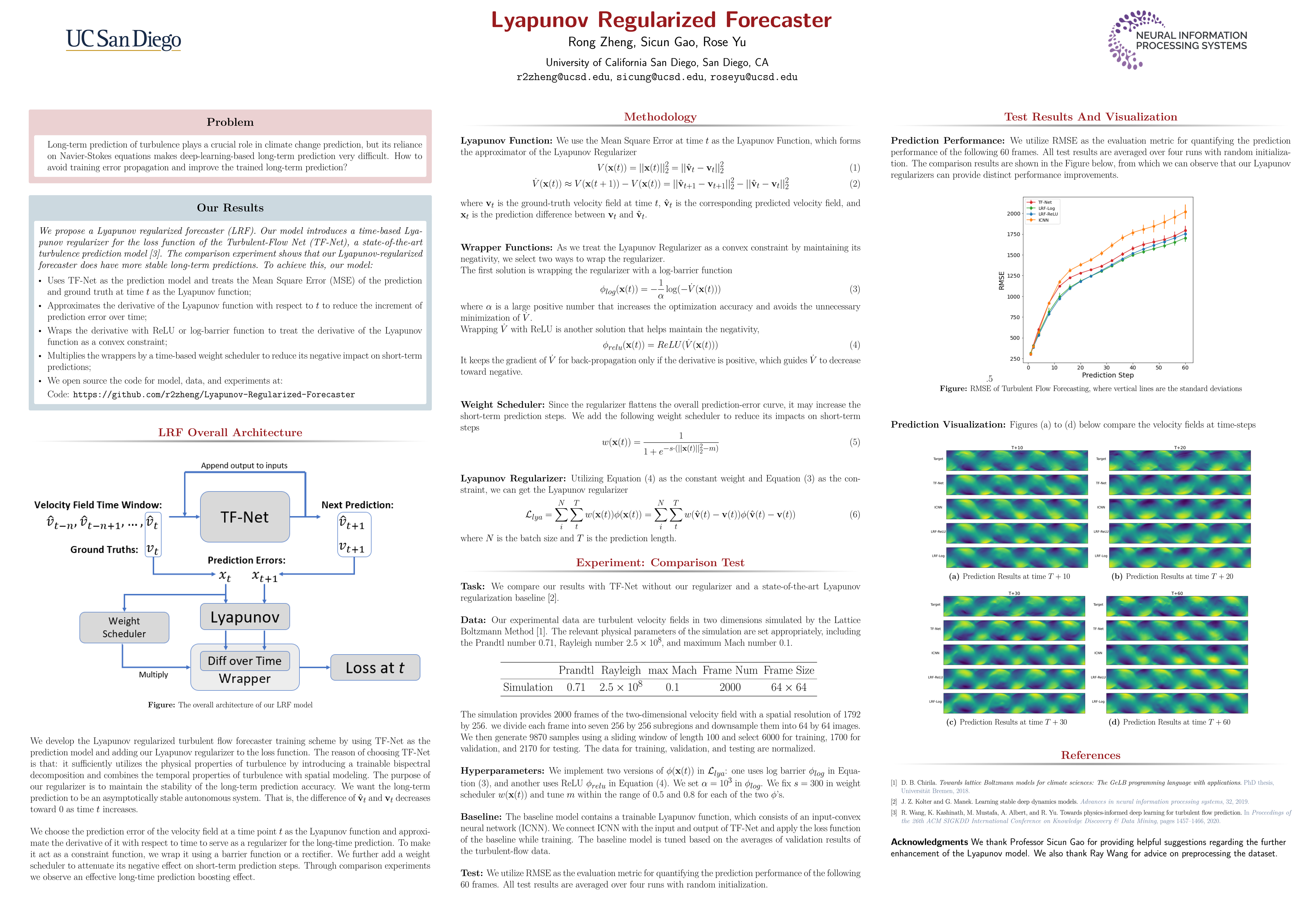
Lyapunov Regularized Forecaster [paper] [poster]
[event]
Zheng,
Rong*; Yu, Rose |
| 110 |
ML4LM: Machine Learning for Safely Landing on Mars [paper] [poster]
[event]
Wu, David
D*; Chung, Wai Tong; Ihme, Matthias |
| 111 |
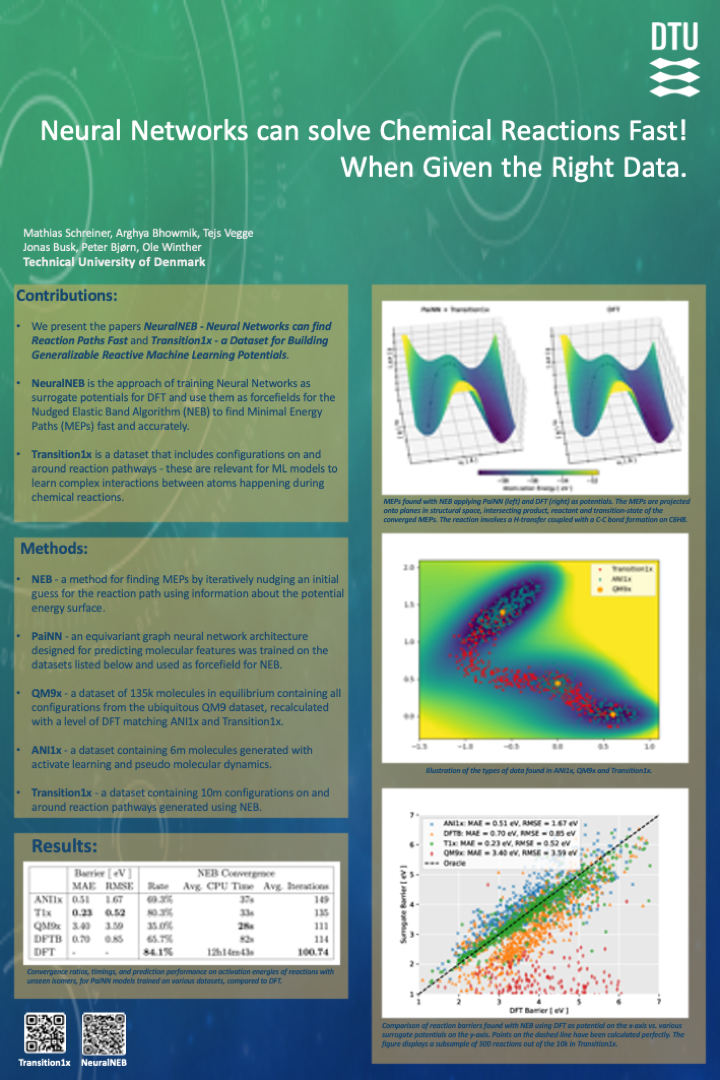
Machine Learning for Chemical Reactions \\A Dance of Datasets and Models
[paper] [poster]
[event]
Schreiner,
Mathias*; Bhowmik, Arghya; Vegge, Tejs; Busk, Jonas; Jørgensen, Peter B;
Winther, Ole |
| 112 |
Machine learning for complete intersection Calabi-Yau manifolds [paper] [poster]
[event]
Erbin,
Harold*; Tamaazousti, Mohamed; Finotello, Riccardo |
| 113 |
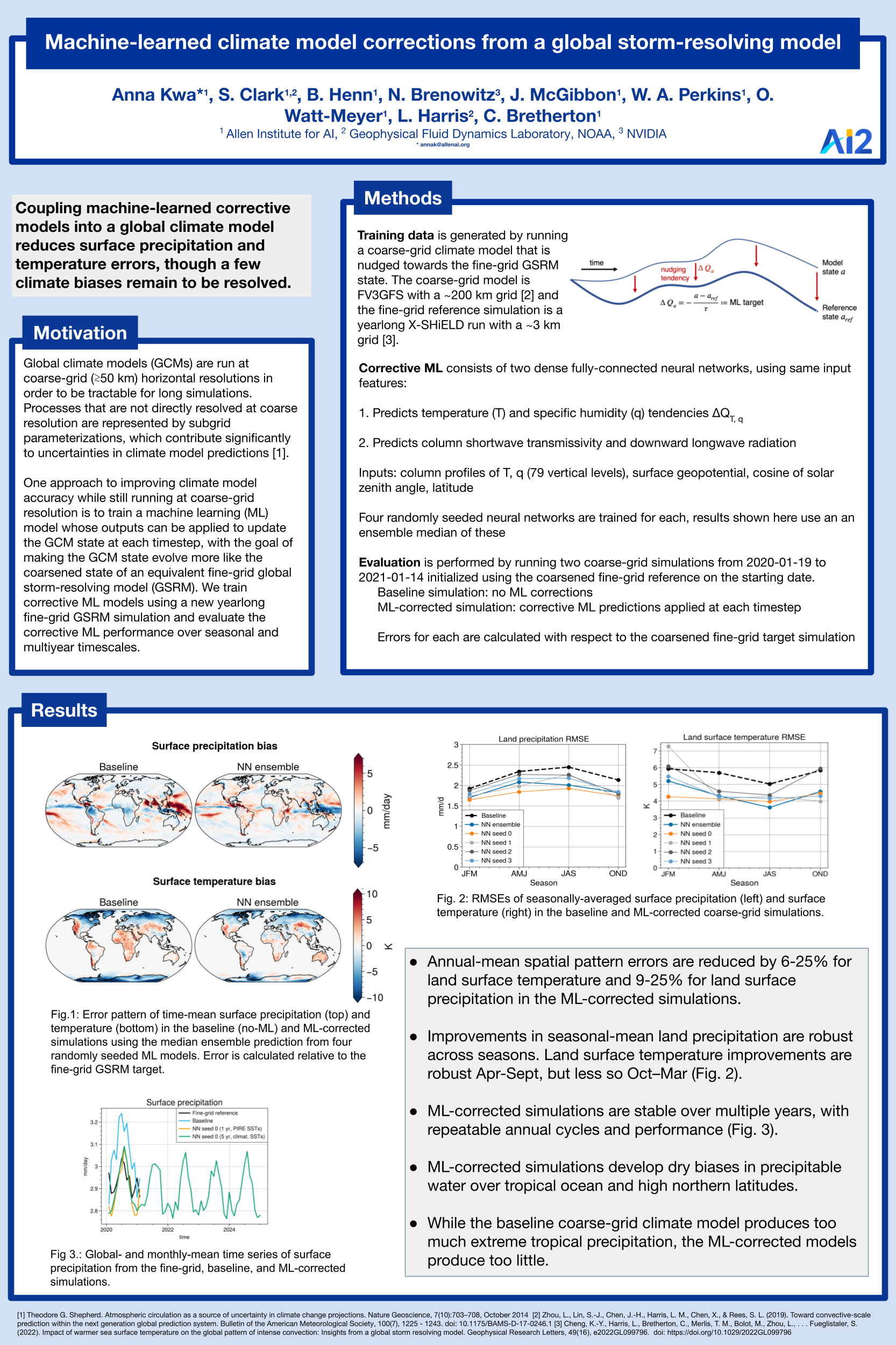
Machine-learned climate model corrections from a global storm-resolving
model [paper] [poster]
[event]
Kwa, Anna*
|
| 114 |
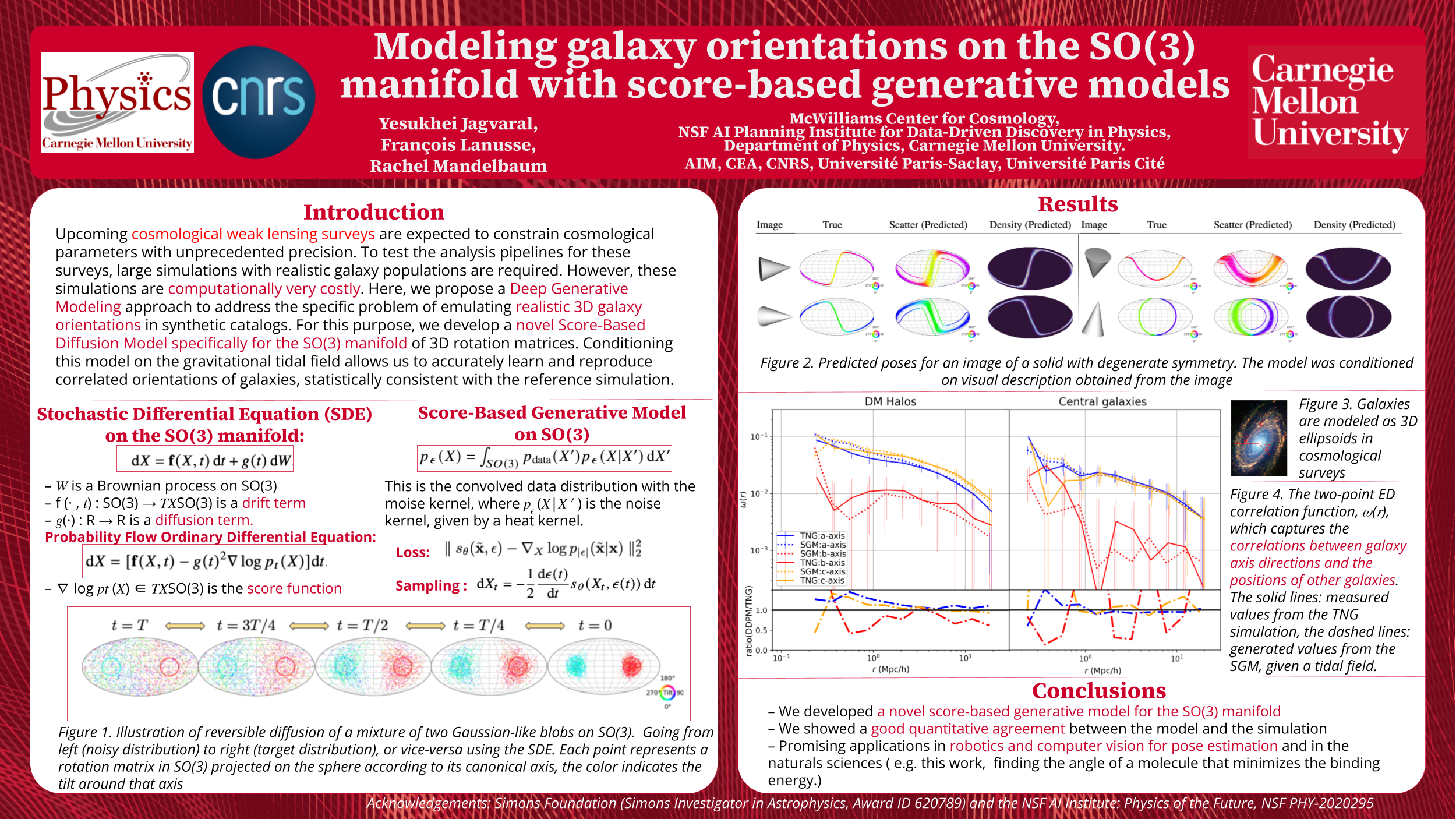
Modeling halo and central galaxy orientations on the SO(3) manifold with
score-based generative models [paper] [poster]
[event]
Jagvaral,
Yesukhei*; Lanusse, Francois; Mandelbaum, Rachel |
| 115 |
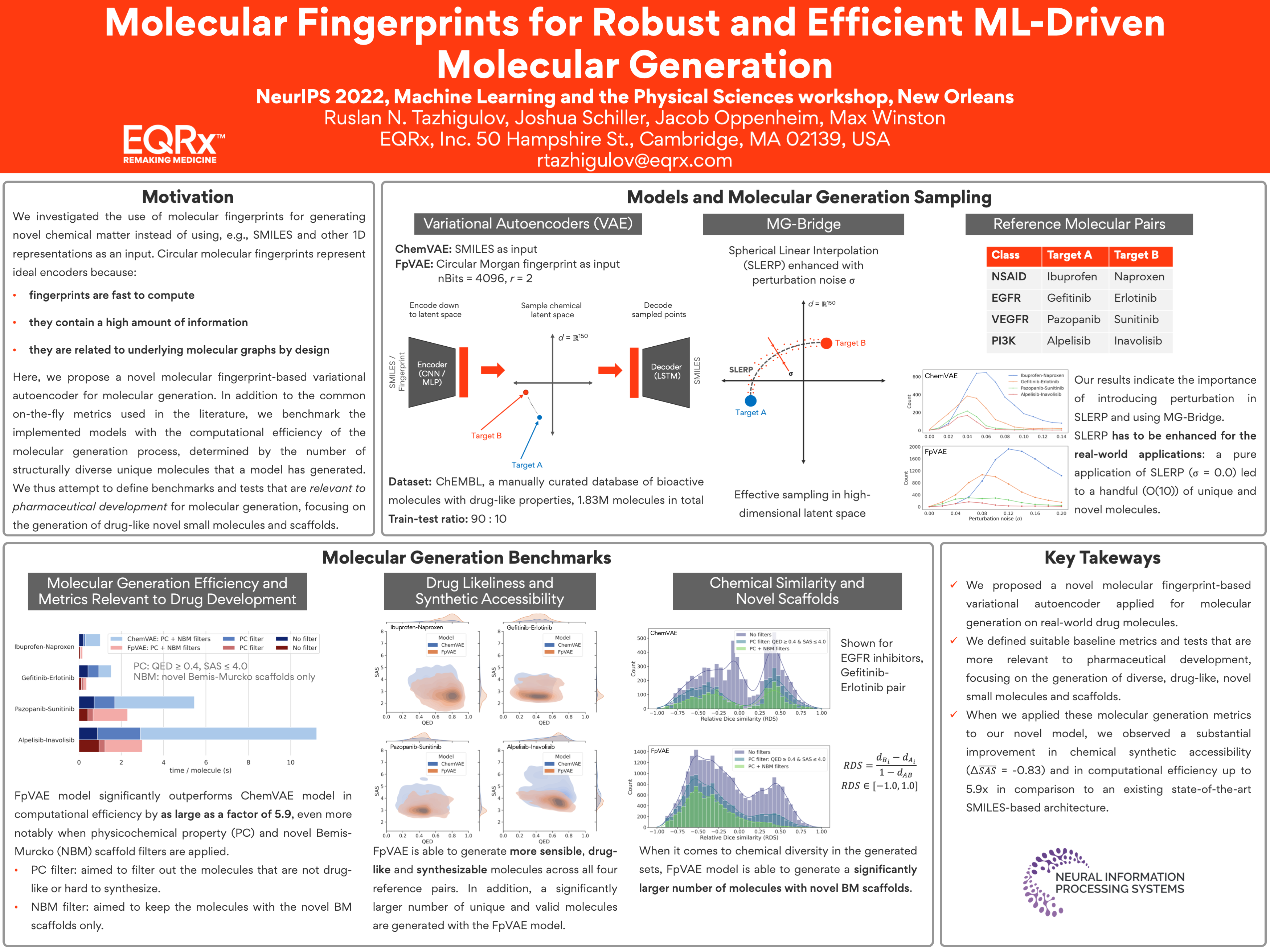
Molecular Fingerprints for Robust and Efficient ML-Driven Molecular
Generation [paper] [poster]
[event]
Tazhigulov,
Ruslan N.*; Schiller, Joshua; Oppenheim, Jacob; Winston, Max |
| 116 |
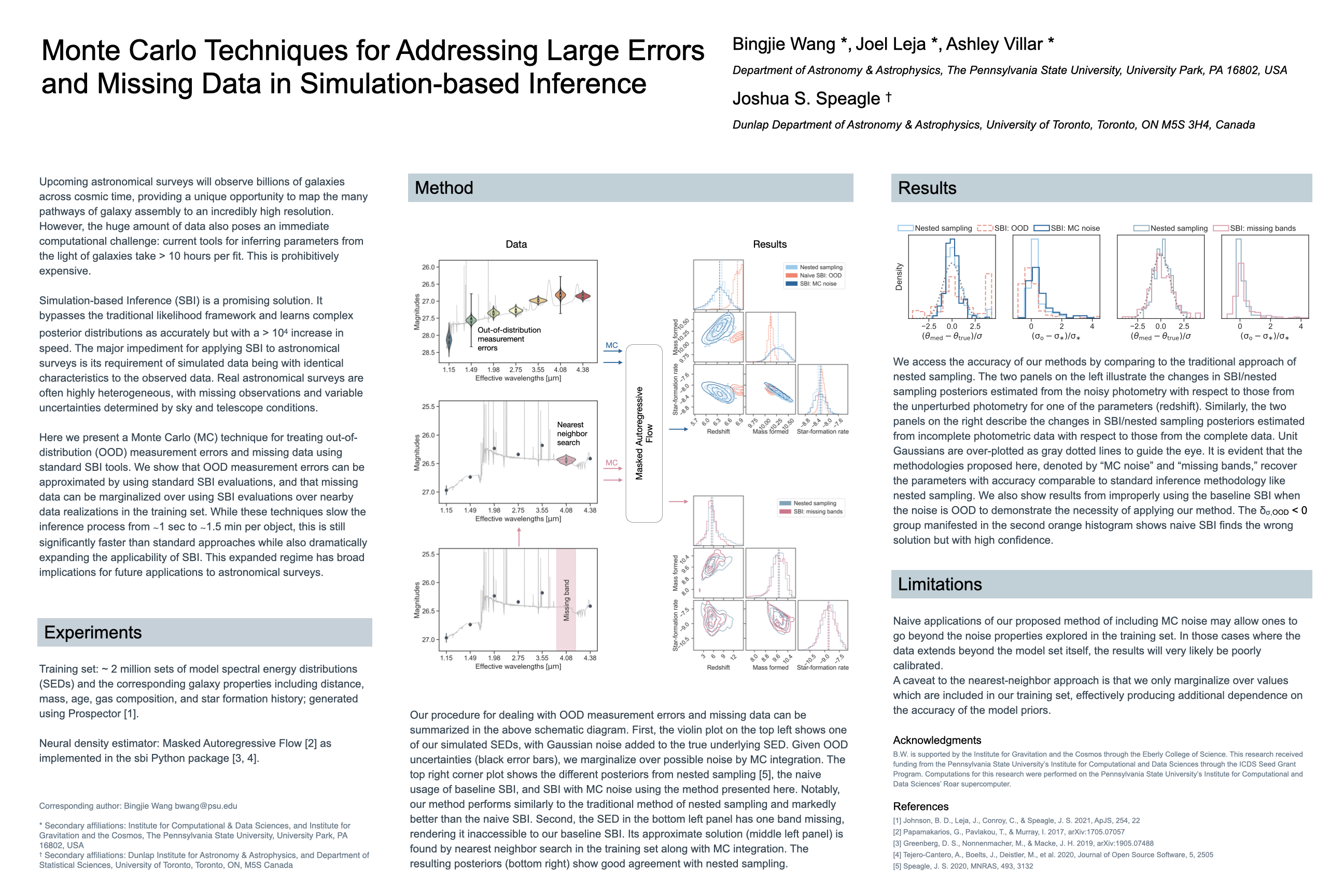
Monte Carlo Techniques for Addressing Large Errors and Missing Data in
Simulation-based Inference [paper] [poster]
[event]
Wang,
Bingjie*; Leja, Joel; Villar, Victoria A; Speagle, Joshua |
| 117 |
Multi-Fidelity Transfer Learning for accurate database PDE approximation
[paper] [poster]
[event]
Liu,
Wenzhuo*; Yagoubi, Mouadh; Schoenauer, Marc; Danan, David |
| 118 |
Multi-scale Digital Twin: Developing a fast and physics-infused surrogate
model for groundwater contamination with uncertain climate models [paper] [poster]
[event]
Wang,
Lijing*; Kurihana, Takuya; Meray, Aurelien; Mastilovic, Ilijana; Praveen,
Satyarth; Xu, Zexuan; Memarzadeh, Milad; Lavin, Alexander; Wainwright, Haruko
|
| 119 |
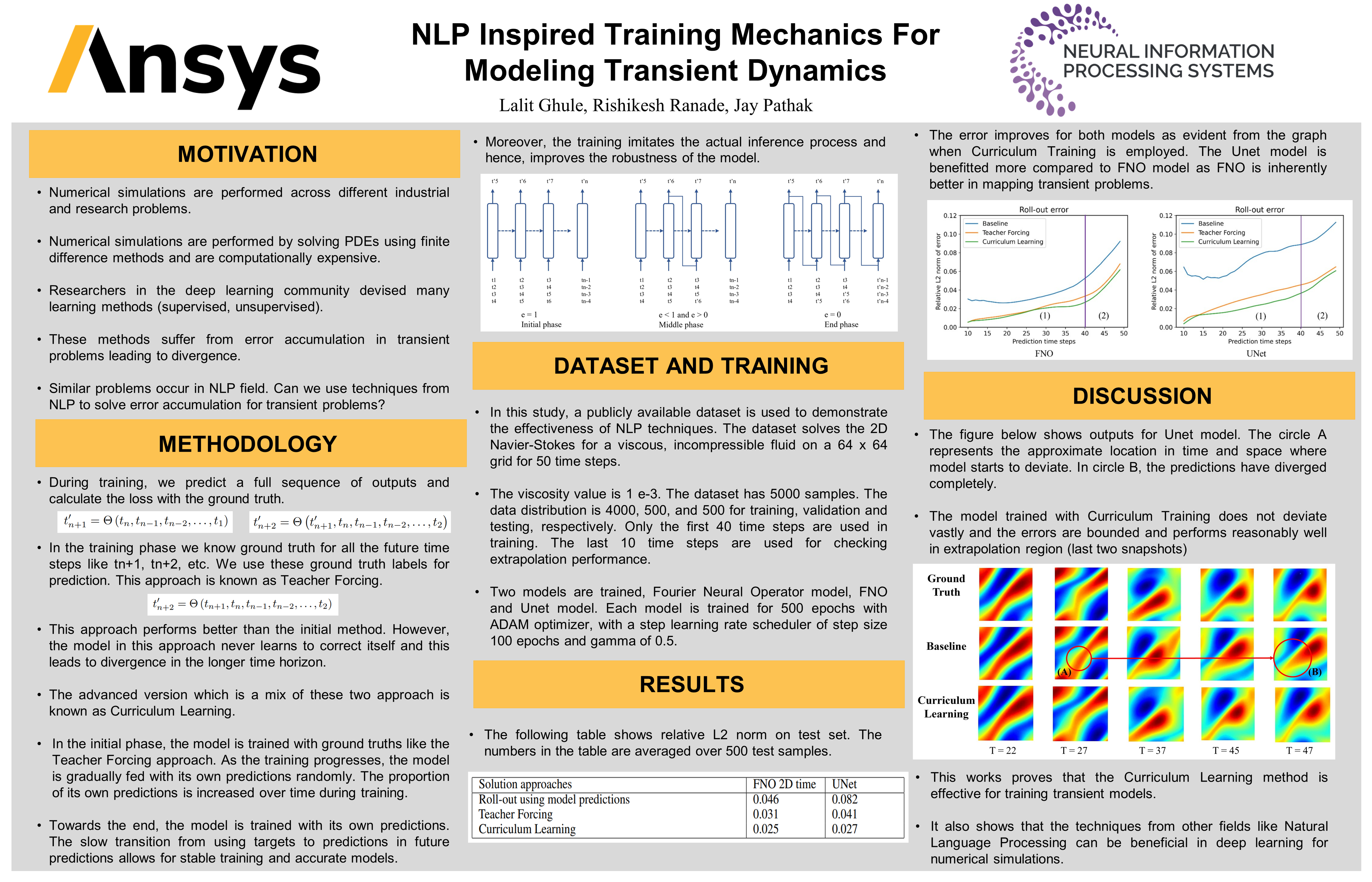
NLP Inspired Training Mechanics For Modeling Transient Dynamics [paper] [poster]
[video] [event]
Ghule,
Lalit J*; Ranade, Rishikesh; Pathak, Jay |
| 120 |
Neural Fields for Fast and Scalable Interpolation of Geophysical Ocean
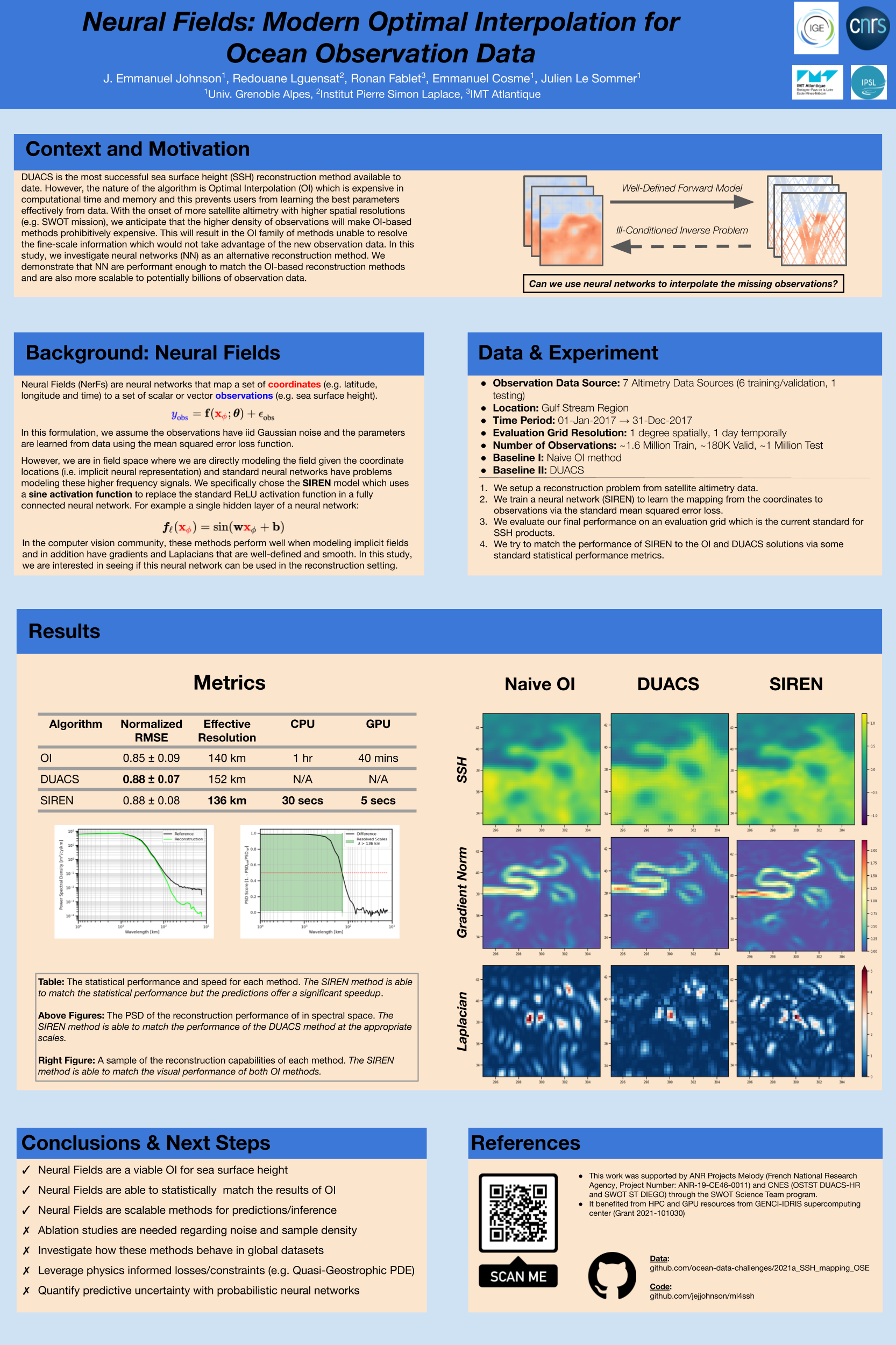
Variables [paper] [poster]
[event]
Johnson,
Juan Emmanuel*; Lguensat, Redouane; fablet, ronan; Cosme, Emmanuel; Le Sommer,
Julien |
| 121 |
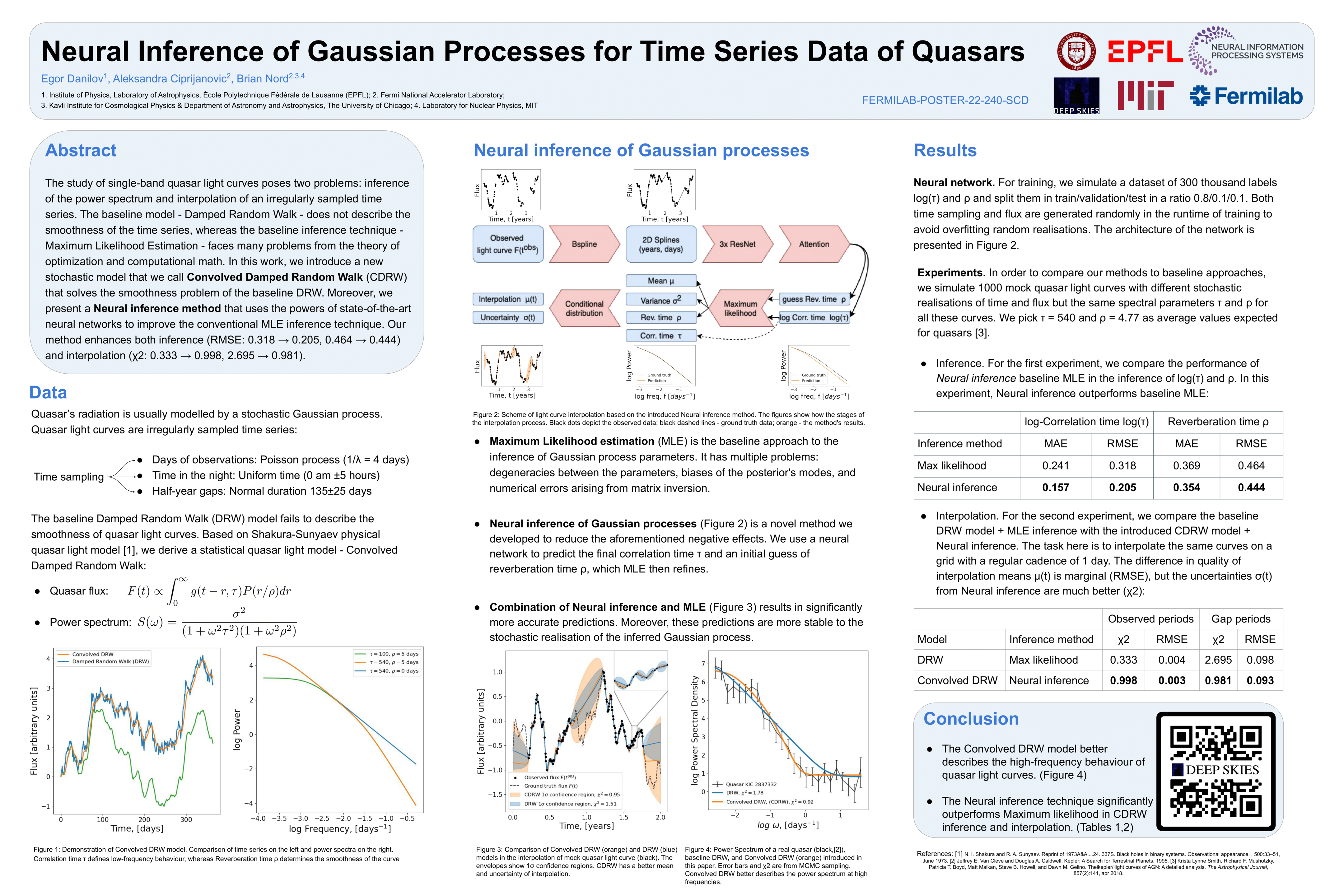
Neural Inference of Gaussian Processes for Time Series Data of Quasars
[paper] [poster]
[event]
Danilov,
Egor*; Ciprijanovic, Aleksandra; Nord, Brian |
| 122 |
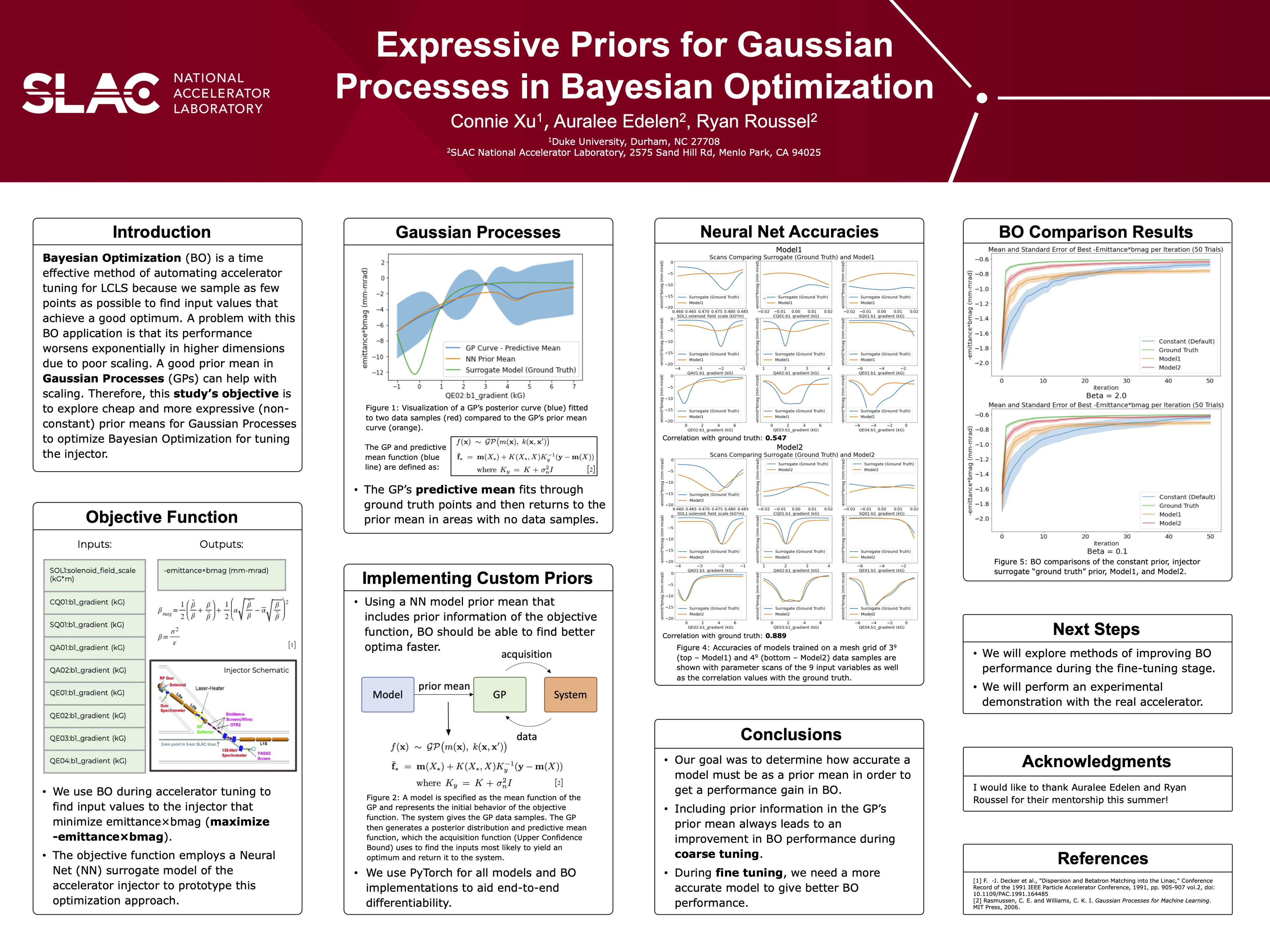
Neural Network Prior Mean for Particle Accelerator Injector Tuning [paper] [poster]
[event]
Xu, Connie
*; Roussel, Ryan; Edelen, Auralee |
| 123 |
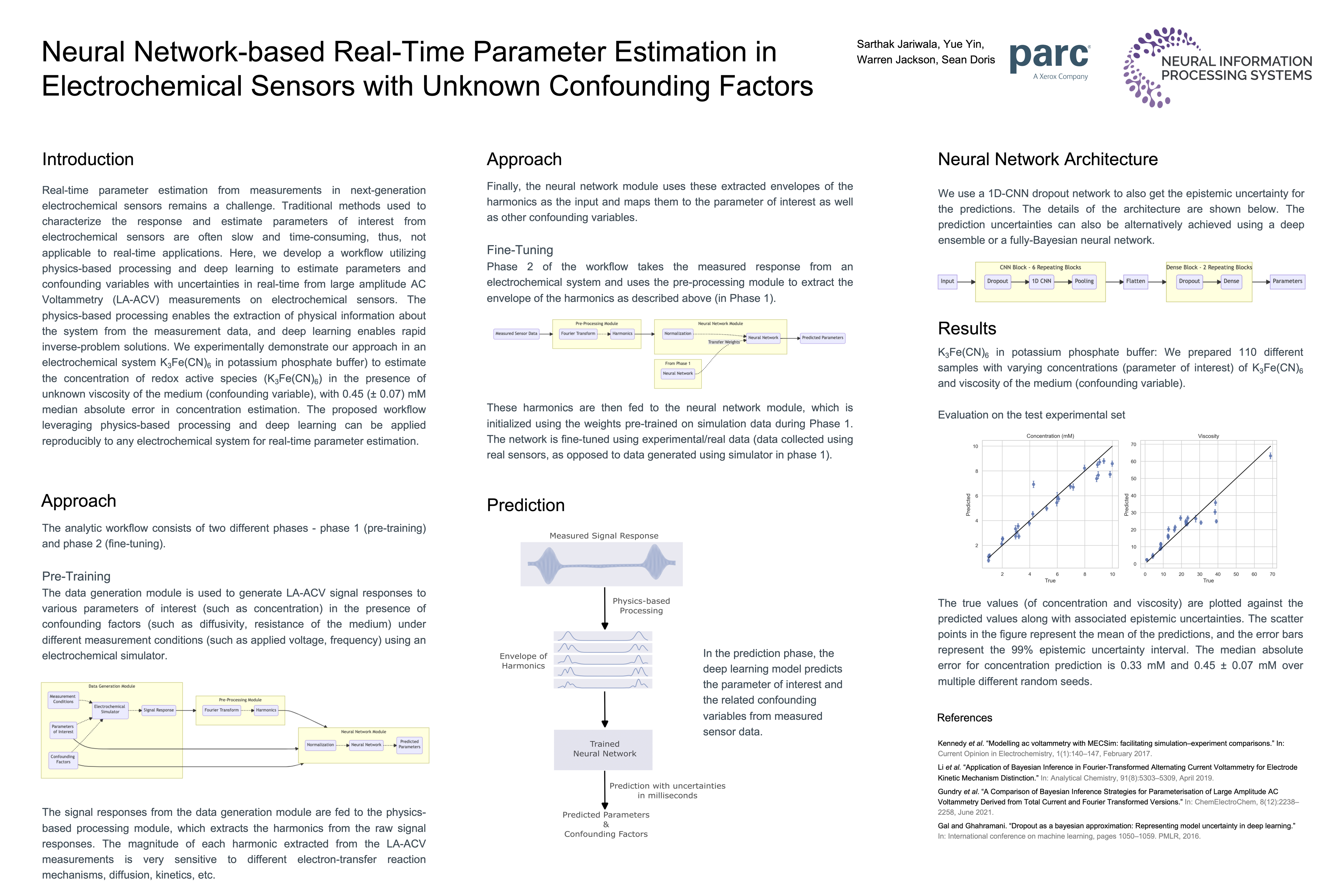
Neural Network-based Real-Time Parameter Estimation in Electrochemical
Sensors with Unknown Confounding Factors [paper] [poster]
[event]
Jariwala,
Sarthak*, Yin, Yue; Jackson, Warren; Doris, Sean |
| 124 |
Neuro-Symbolic Partial Differential Equation Solver [paper] [poster]
[event]
Akbari
Mistani, Pouria*; Pakravan, Samira; Ilango, Rajesh; Choudhry, Sanjay; Gibou,
Frederic |
| 125 |
Normalizing Flows for Fragmentation and Hadronization [paper] [poster]
[event]
Youssef,
Ahmed*; Ilten, Phil; Menzo, Tony; Zupan, Jure; Szewc, Manuel; Mrenna, Stephen;
Wilkinson, Michael K. |
| 126 |
Normalizing Flows for Hierarchical Bayesian Analysis: A Gravitational Wave
Population Study [paper]
[poster]
[event]
Ruhe,
David*; Wong, Kaze; Cranmer, Miles; Forré, Patrick |
| 127 |
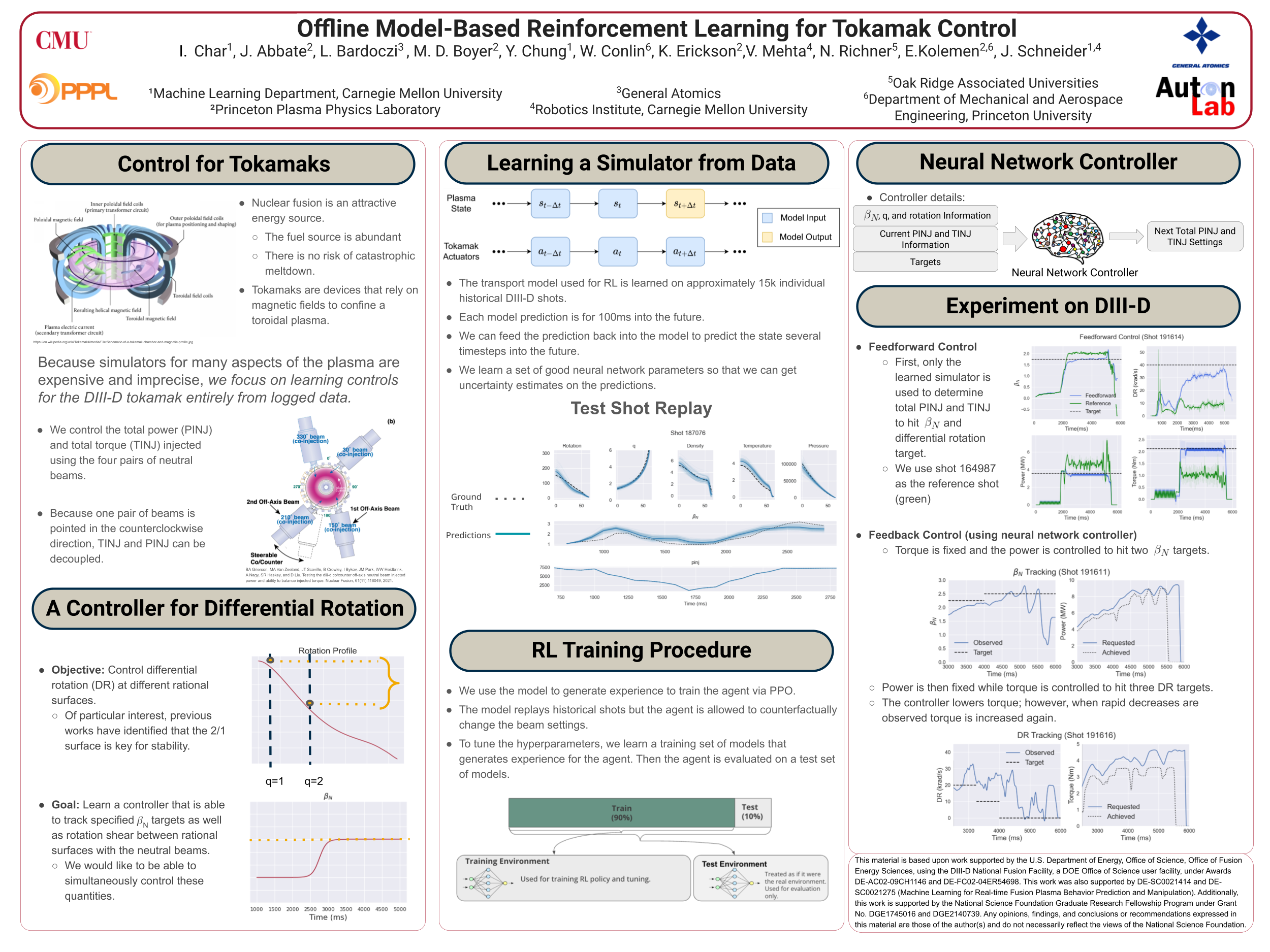
Offline Model-Based Reinforcement Learning for Tokamak Control [paper] [poster]
[event]
Char, Ian*;
Abbate, Joseph; Bardoczi, Laszlo; Boyer, Mark; Chung, Youngseog; Conlin, Rory;
Erickson, Keith; Mehta, Viraj; Richner, Nathan; Kolemen, Egemen; Schneider, Jeff
|
| 128 |
On Using Deep Learning Proxies as Forward Models in Optimization Problems
[paper] [poster]
[event]
Albreiki,
Fatima A*; Belayouni, Nidhal; Gupta, Deepak K |
| 129 |
One Network to Approximate Them All: Amortized Variational Inference of Ising
Ground States [paper] [poster]
[event]
Sanokowski,
Sebastian*; Berghammer, Wilhelm; Kofler, Johannes; Hochreiter, Sepp; Lehner,
Sebastian |
| 130 |
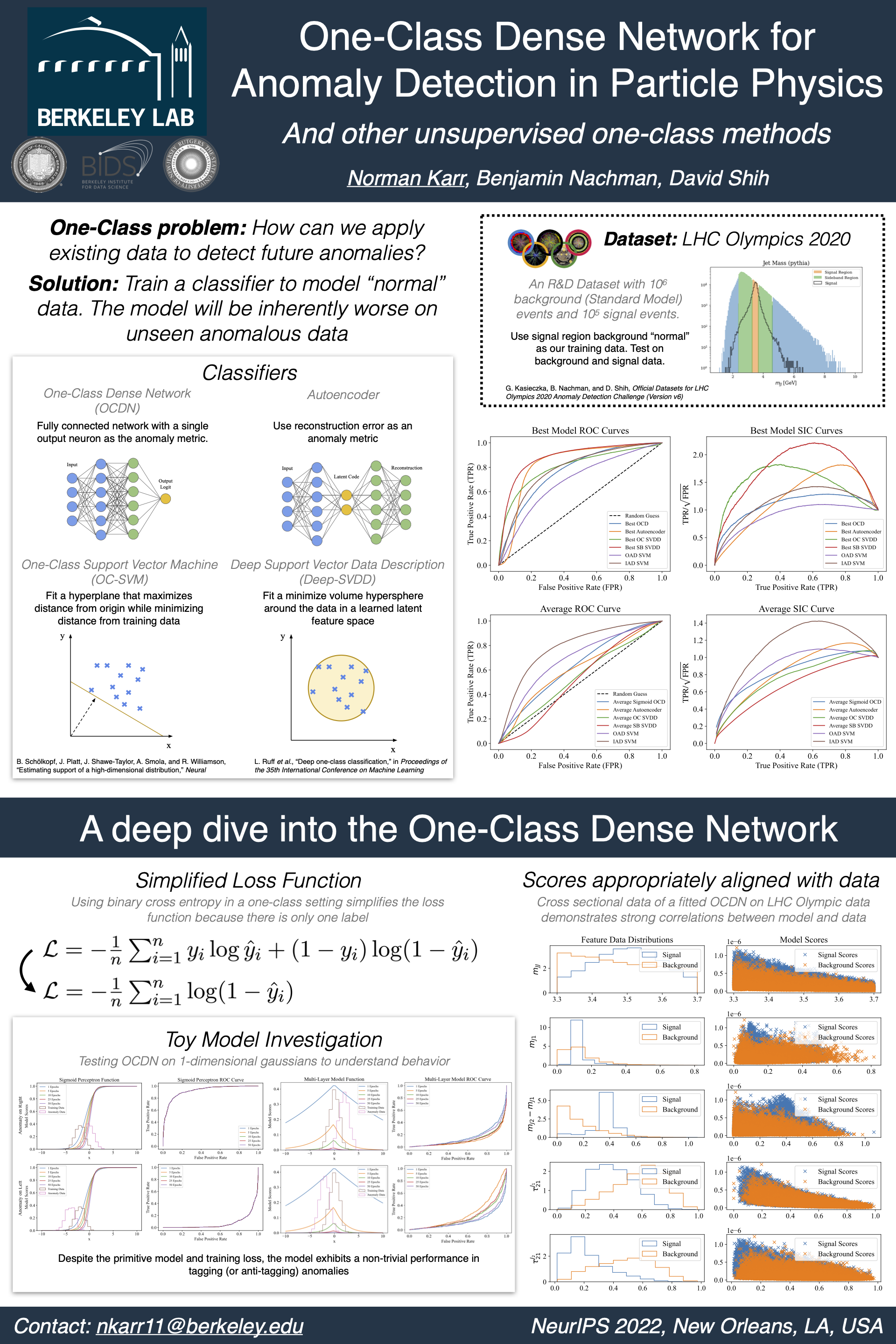
One-Class Dense Networks for Anomaly Detection [paper] [poster]
[event]
Karr,
Norman*; Nachman, Benjamin; Shih, David |
| 131 |
One-shot learning for solution operators of partial differential
equations [paper] [poster]
[event]
Lu, Lu*;
Jiao, Anran; Pathak, Jay; Ranade, Rishikesh; He, Haiyang |
| 132 |
PELICAN: Permutation Equivariant and Lorentz Invariant or Covariant
Aggregator Network for Particle Physics [paper] [poster]
[event]
Offermann,
Jan*; Bogatskiy, Alexander; Hoffman, Timothy; Miller, David |
| 133 |
PIPS: Path Integral Stochastic Optimal Control for Path Sampling in Molecular
Dynamics [event]
Holdijk,
Lars*; Du, Yuanqi; Hooft, Ferry; Jaini, Priyank; Ensing, Bernd; Welling, Max
|
| 134 |
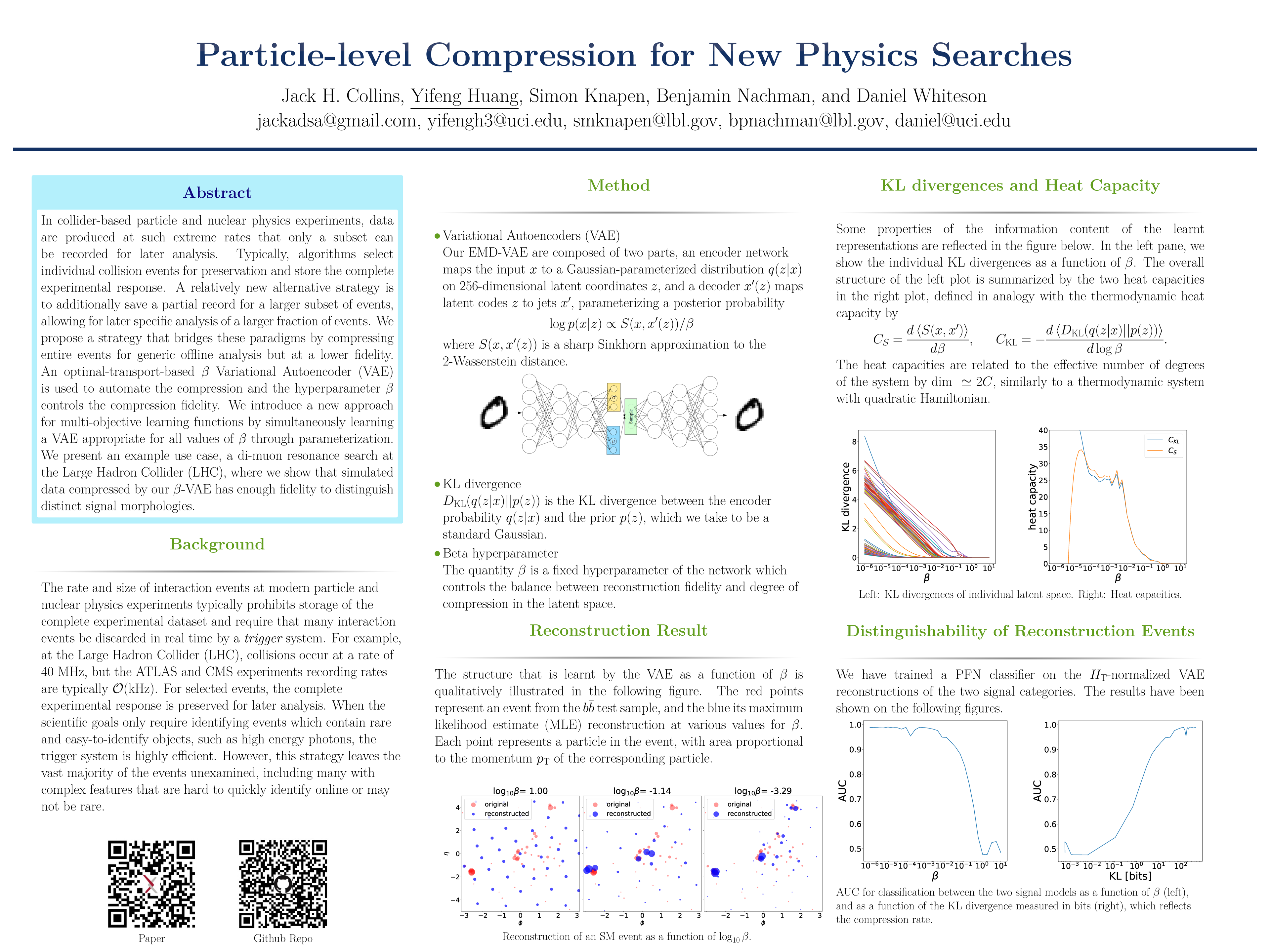
Particle-level Compression for New Physics Searches [paper] [poster]
[event]
Huang,
Yifeng*; Collins, Jack; Nachman, Benjamin; Knapen, Simon; Whiteson, Daniel |
| 135 |
Phase transitions and structure formation in learning local rules [paper] [poster]
[event]
Zunkovic,
Bojan*; Ilievski, Enej |
| 136 |
Physical Data Models in Machine Learning Imaging Pipelines [paper] [poster]
[event]
Aversa,
Marco*; Oala, Luis; Clausen, Christoph; Murray-Smith, Roderick; Sanguinetti,
Bruno |
| 137 |
Physics solutions for privacy leaks in machine learning [paper] [poster]
[video] [event]
Pozas-Kerstjens,
Alejandro*; Hernandez-Santana, Senaida; Pareja Monturiol, Jose Ramon; Castrillon
Lopez, Marco; Scarpa, Giannicola; Gonzalez-Guillen, Carlos E.; Perez-Garcia,
David |
| 138 |
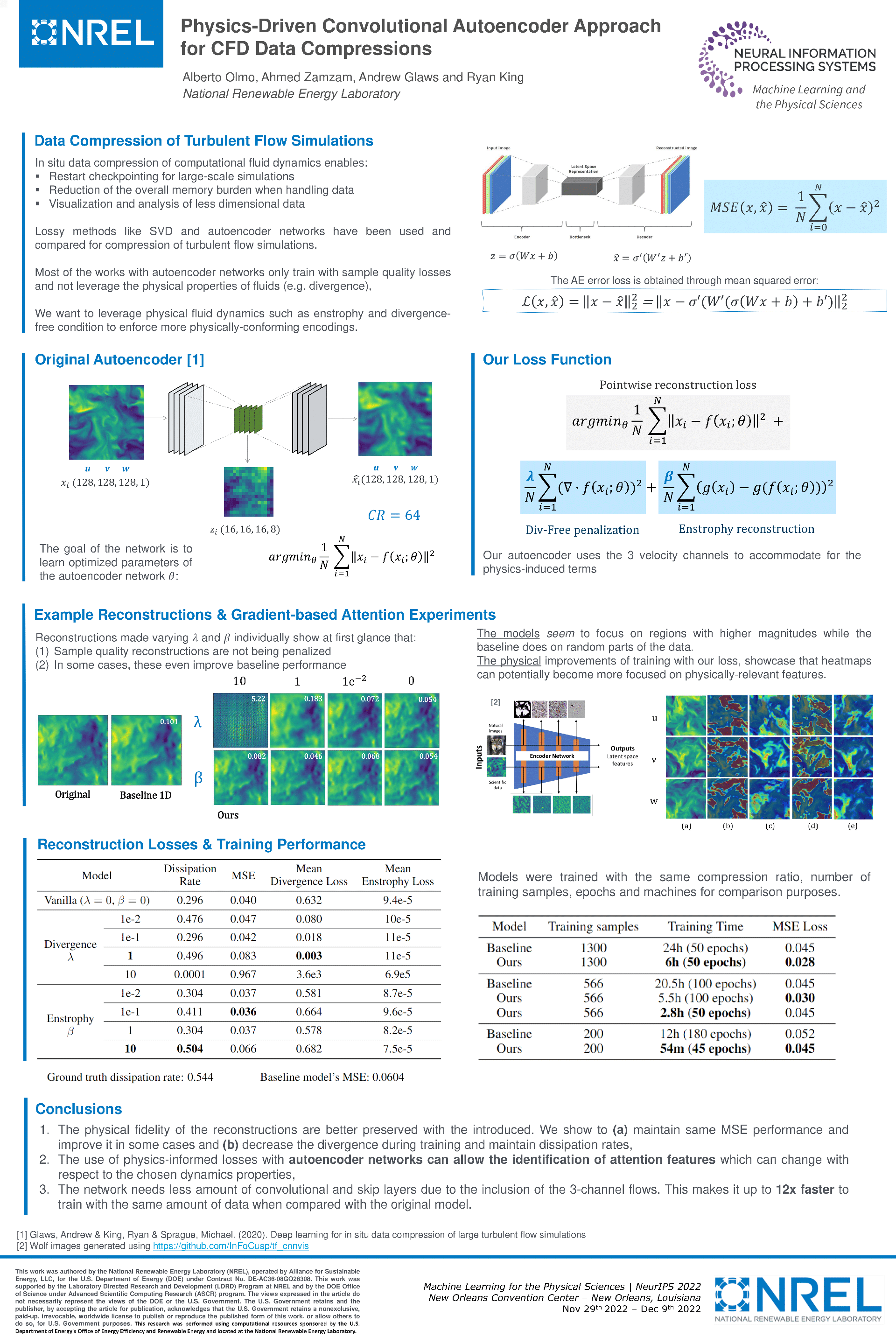
Physics-Driven Convolutional Autoencoder Approach for CFD Data
Compressions [paper] [poster]
[event]
Olmo,
Alberto*; Zamzam, Ahmed S; Glaws, Andrew; King, Ryan |
| 139 |
Physics-Informed CNNs for Super-Resolution of Sparse Observations on
Dynamical Systems [paper]
[poster]
[event]
Kelshaw,
Daniel J*; Rigas, Georgios; Magri, Luca |
| 140 |
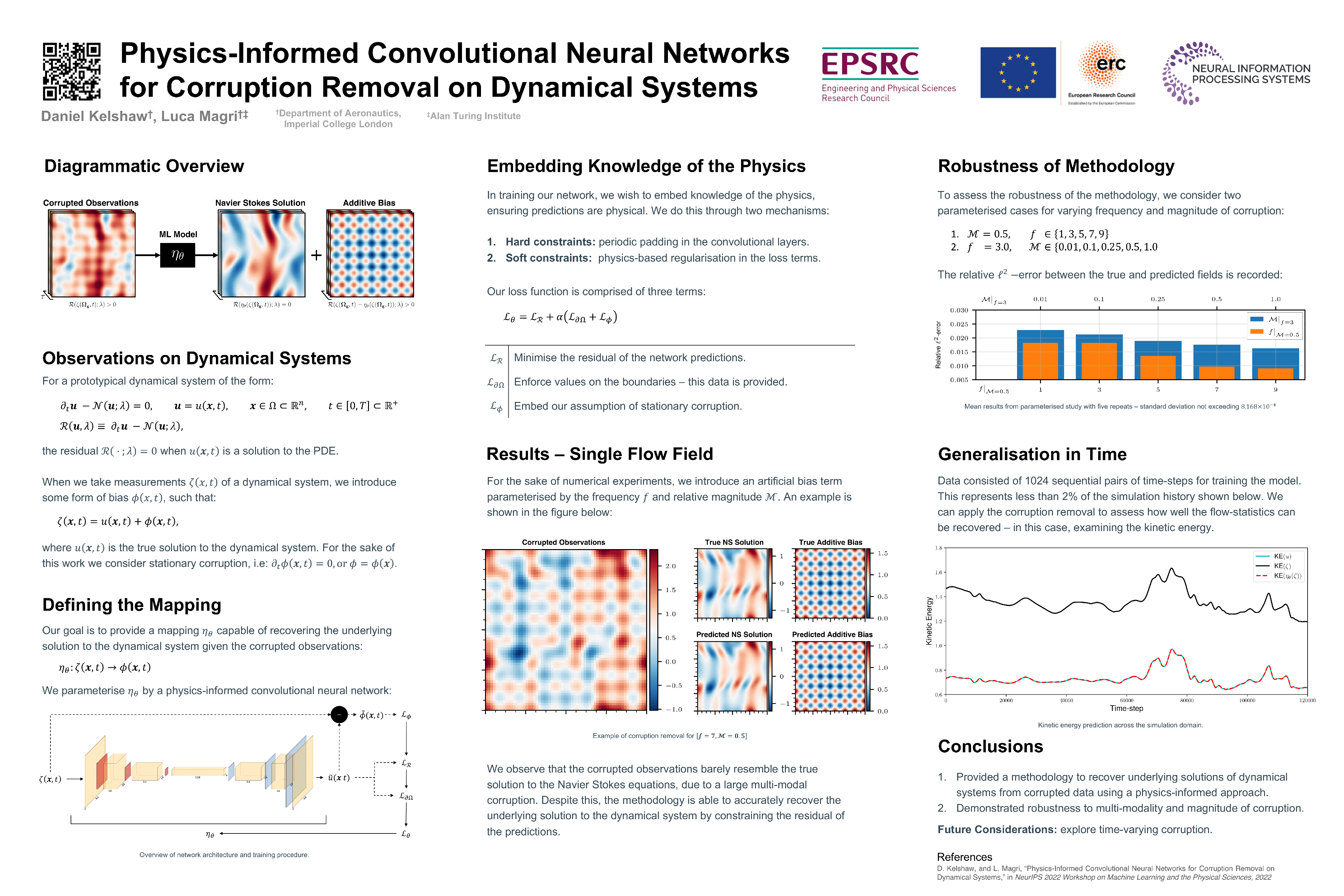
Physics-Informed Convolutional Neural Networks for Corruption Removal on
Dynamical Systems [paper]
[poster]
[event]
Kelshaw,
Daniel J*; Magri, Luca |
| 141 |
Physics-Informed Machine Learning of Dynamical Systems for Efficient Bayesian
Inference [paper] [poster]
[event]
Dhulipala,
Som*; Che, Yifeng; Shields, Michael |
| 142 |
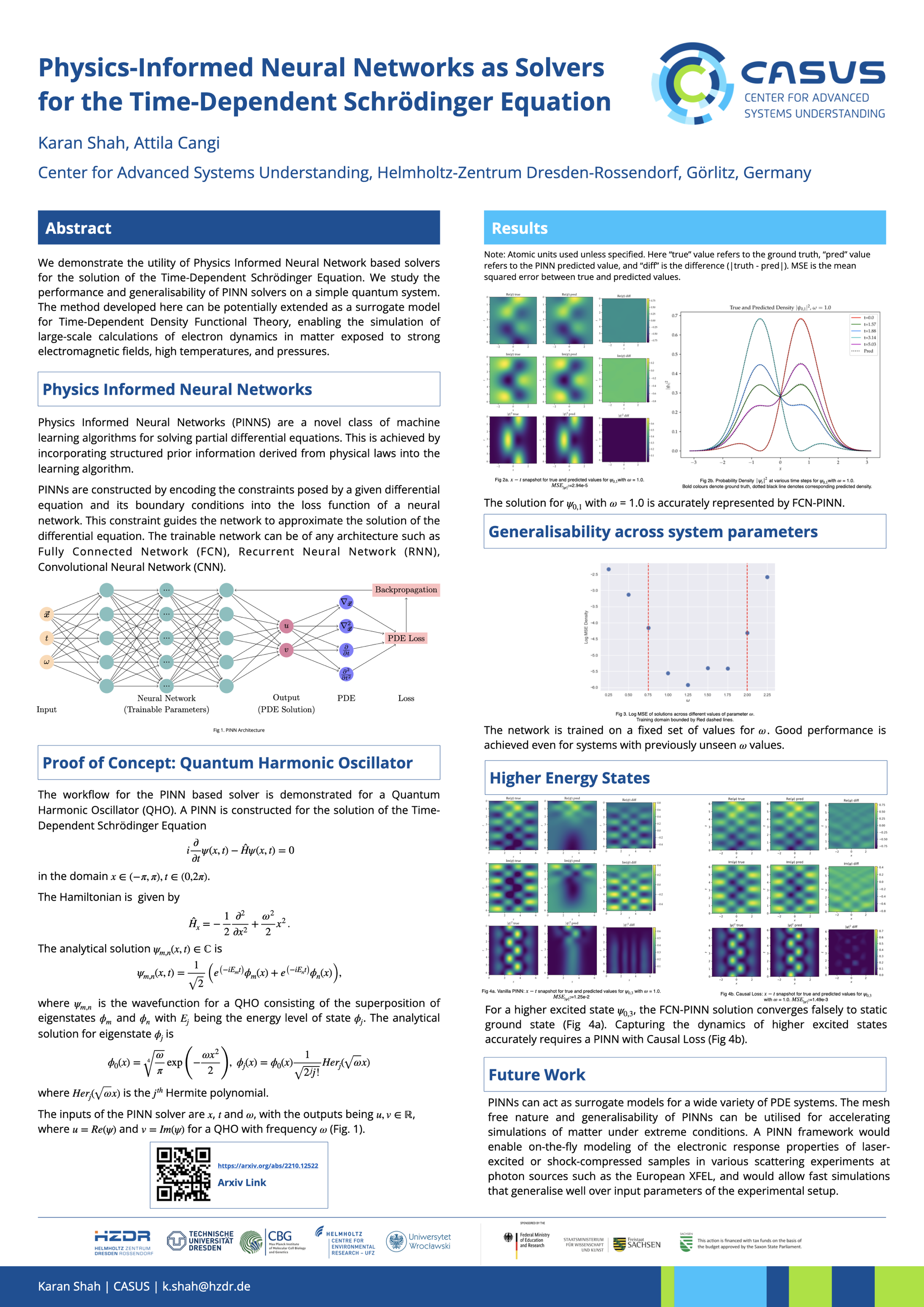
Physics-Informed Neural Networks as Solvers for the Time-Dependent
Schrödinger Equation [paper] [poster]
[event]
Shah,
Karan*; Stiller, Patrick; Hoffmann, Nico; Cangi, Attila |
| 143 |
Physics-informed Bayesian Optimization of an Electron Microscope [event]
Ma,
Desheng* |
| 144 |
Physics-informed neural networks for modeling rate- and temperature-dependent
plasticity [paper] [event]
Arora,
Rajat; Kakkar, Pratik; Amit, Chakraborty; Dey, Biswadip* |
| 145 |
Plausible Adversarial Attacks on Direct Parameter Inference Models in
Astrophysics [paper] [poster]
[event]
Horowitz,
Benjamin A*; Melchior, Peter M |
| 146 |
Point Cloud Generation using Transformer Encoders and Normalising Flows
[paper] [poster]
[event]
Käch,
Benno*; Krücker, Dirk; Melzer, Isabell |
| 147 |
Posterior samples of source galaxies in strong gravitational lenses with
score-based priors [paper] [event]
Adam,
Alexandre*; Coogan, Adam; Malkin, Nikolay; Legin, Ronan; Perreault-Levasseur,
Laurence; Hezaveh, Yashar; Bengio, Yoshua |
| 148 |
Probabilistic Mixture Modeling For End-Member Extraction in Hyperspectral
Data [paper] [event]
Hoidn,
Oliver*; Mishra, Aashwin; Mehta, Apurva |
| 149 |
Qubit seriation: Undoing data shuffling using spectral ordering [paper] [poster]
[event]
Acharya,
Atithi*; Rudolph, Manuel; Chen, Jing; Miller, Jacob; Perdemo-Ortiz, Alejandro
|
| 150 |
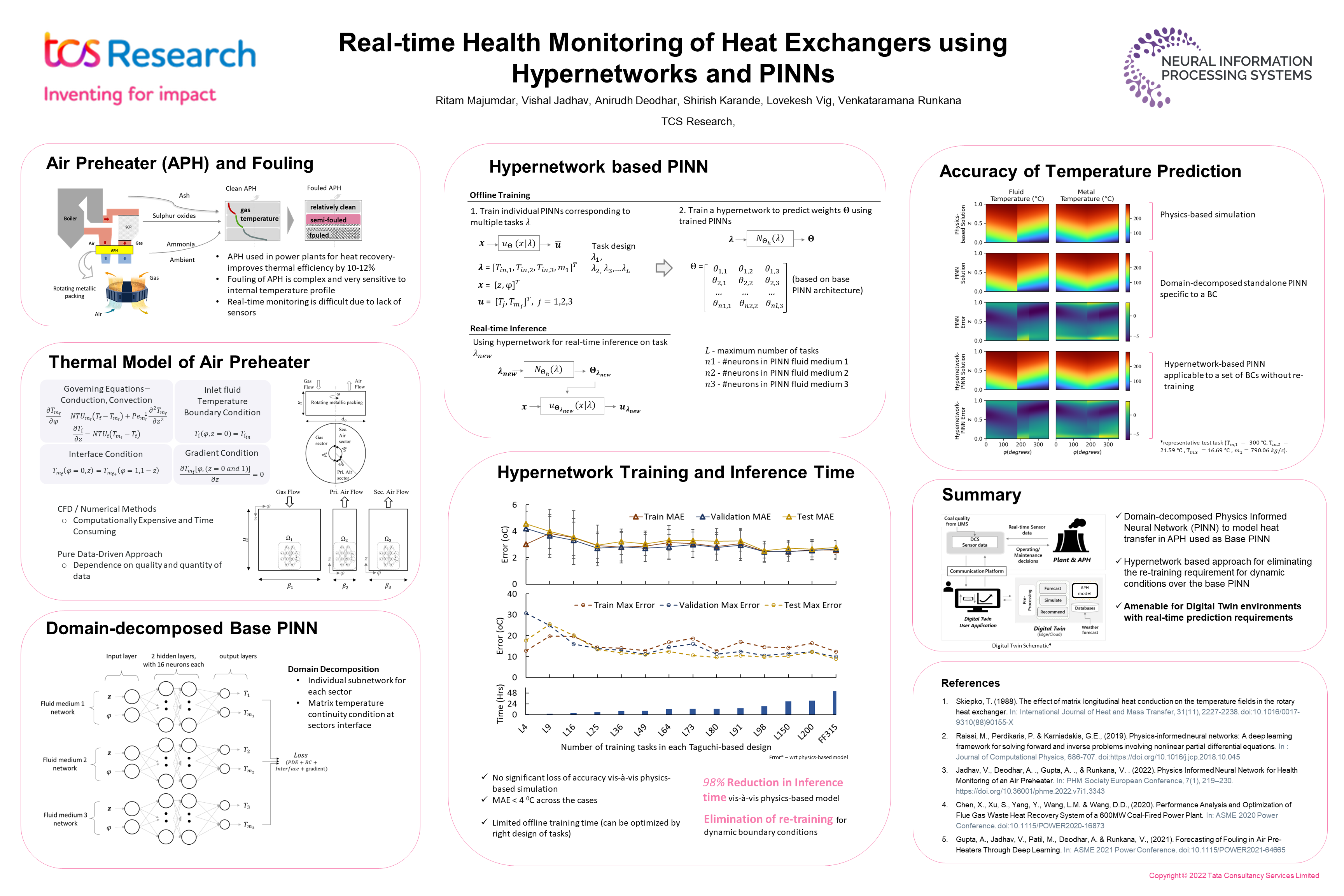
Real-time Health Monitoring of Heat Exchangers using Hypernetworks and
PINNs [paper] [poster]
[event]
Majumdar,
Ritam; Jadhav, Vishal; Deodhar, Anirudh; Karande, Shirish; Vig, Lovekesh;
Runkana, Venkataramana* |
| 151 |
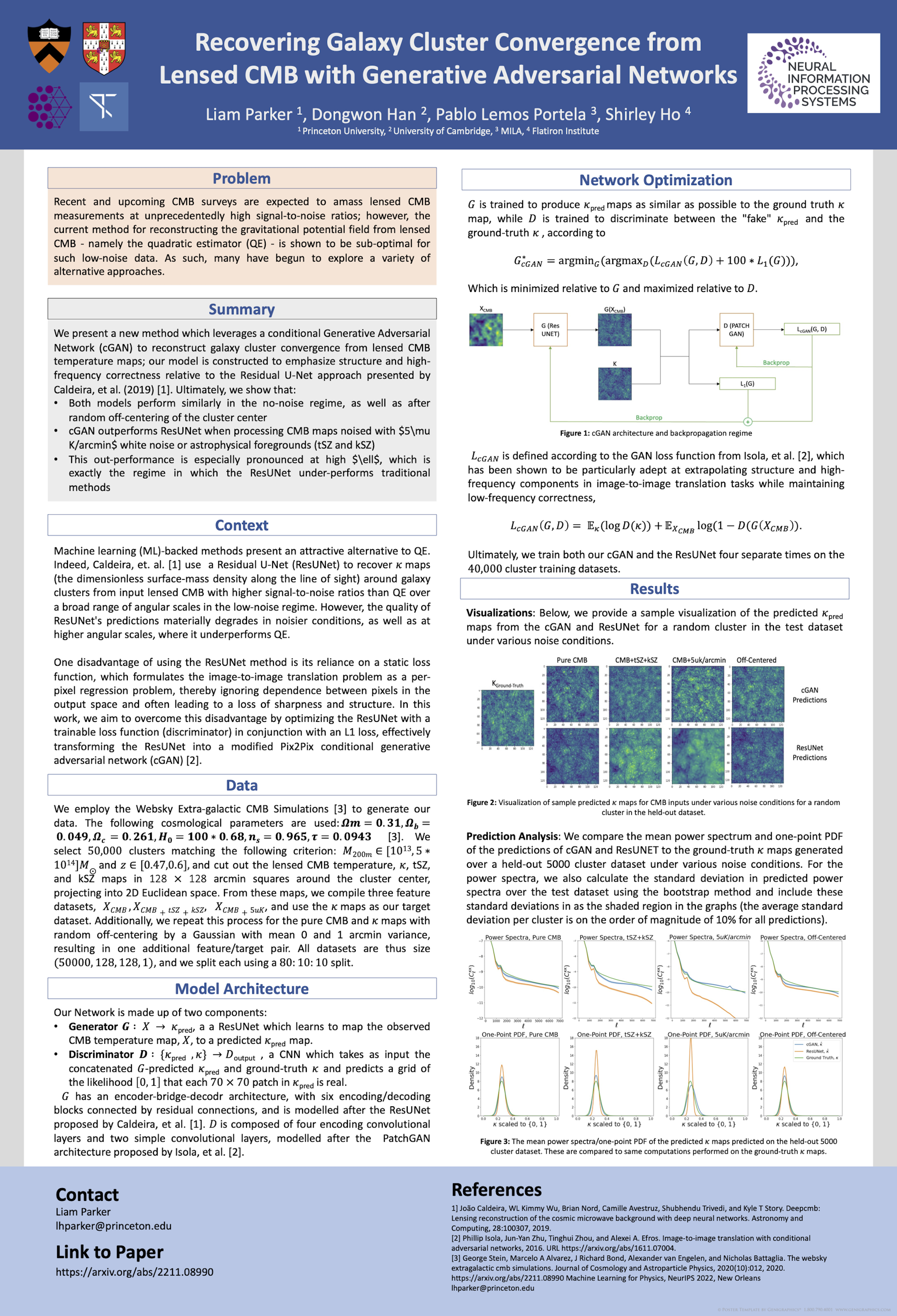
Recovering Galaxy Cluster Convergence from Lensed CMB with Generative
Adversarial Networks [paper] [poster]
[event]
Parker,
Liam H*; Han, Dongwon; Ho, Shirley; Lemos, Pablo |
| 152 |
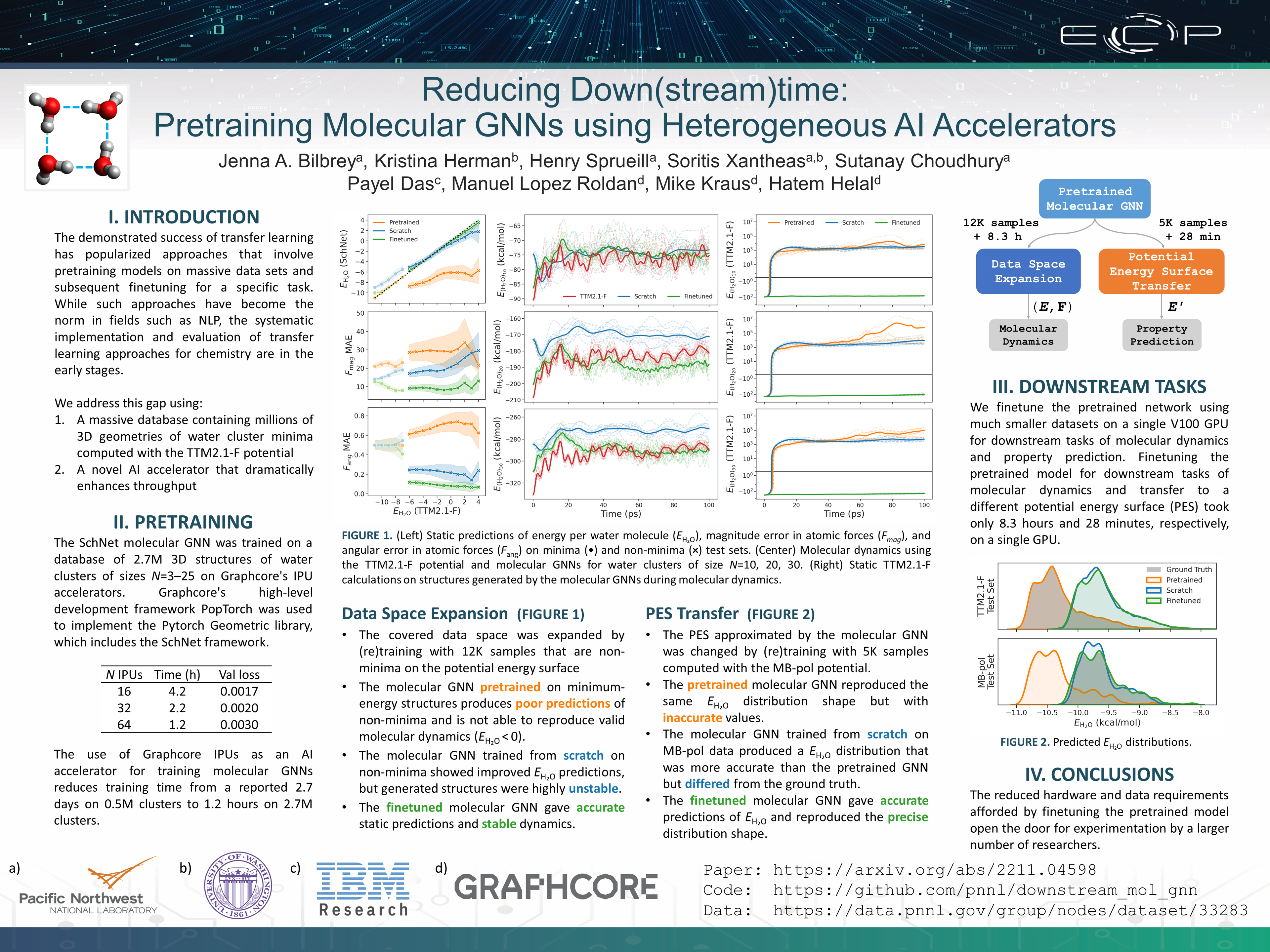
Reducing Down(stream)time: Pretraining Molecular GNNs using Heterogeneous AI
Accelerators [paper] [poster]
[event]
Bilbrey,
Jenna A*; Herman, Kristina; Sprueill, Henry; Xantheas, Sotiris; Das, Payel;
Lopez Roldan, Manuel; Kraus, Mike; Helal, Hatem; Choudhury, Sutanay |
| 153 |
Renormalization in the neural network-quantum field theory correspondence
[paper] [poster]
[event]
Erbin,
Harold*; Lahoche, Vincent; Ousmane Samary, Dine |
| 154 |
SE(3)-equivariant self-attention via invariant features [paper] [poster]
[event]
Chen, Nan*;
Villar, Soledad |
| 155 |
Scalable Bayesian Inference for Finding Strong Gravitational Lenses [paper] [poster]
[event]
Patel, Yash
P*; Regier, Jeffrey |
| 156 |
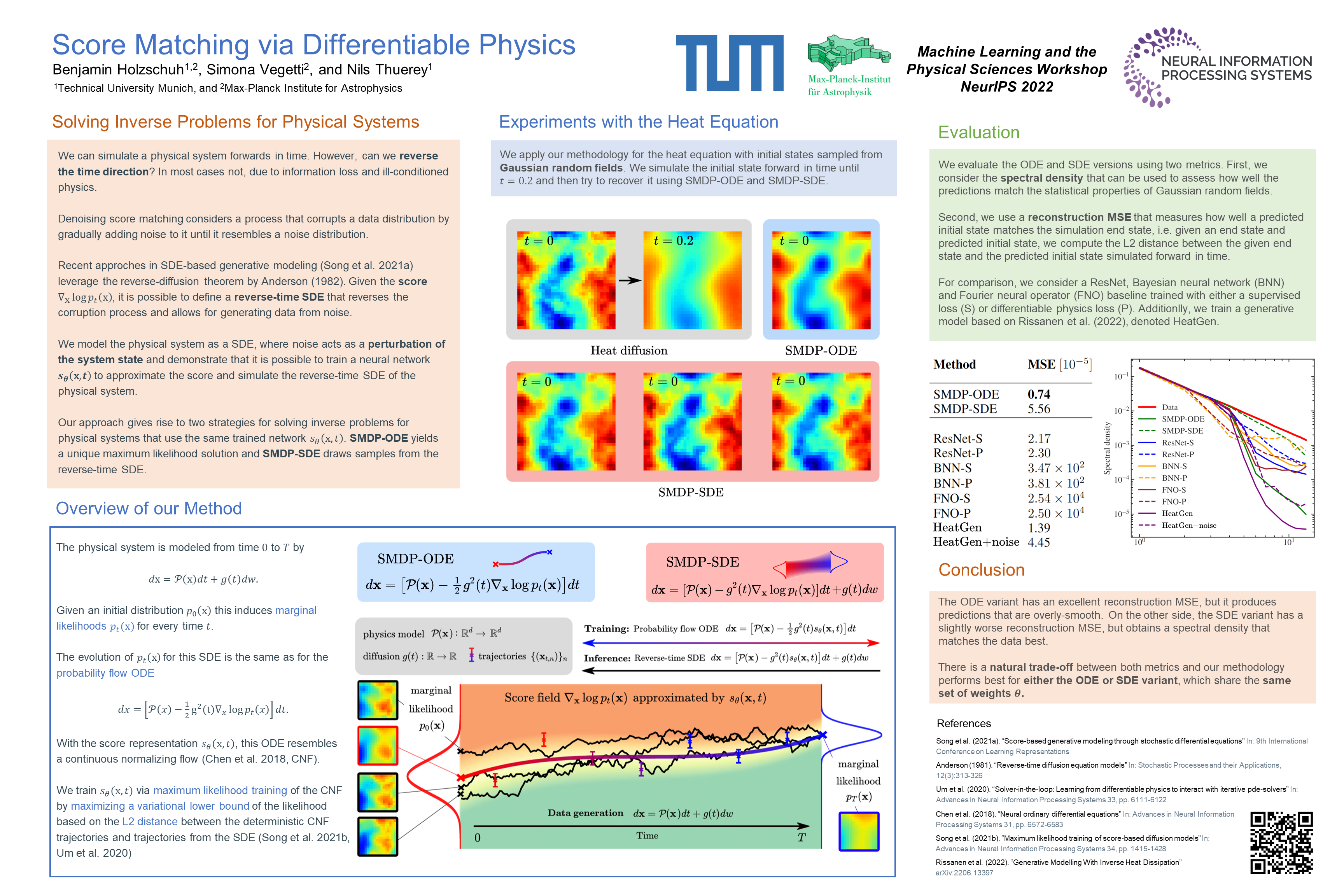
Score Matching via Differentiable Physics [paper] [poster]
[event]
Holzschuh,
Benjamin J*; Vegetti, Simona ; Thuerey, Nils |
| 157 |
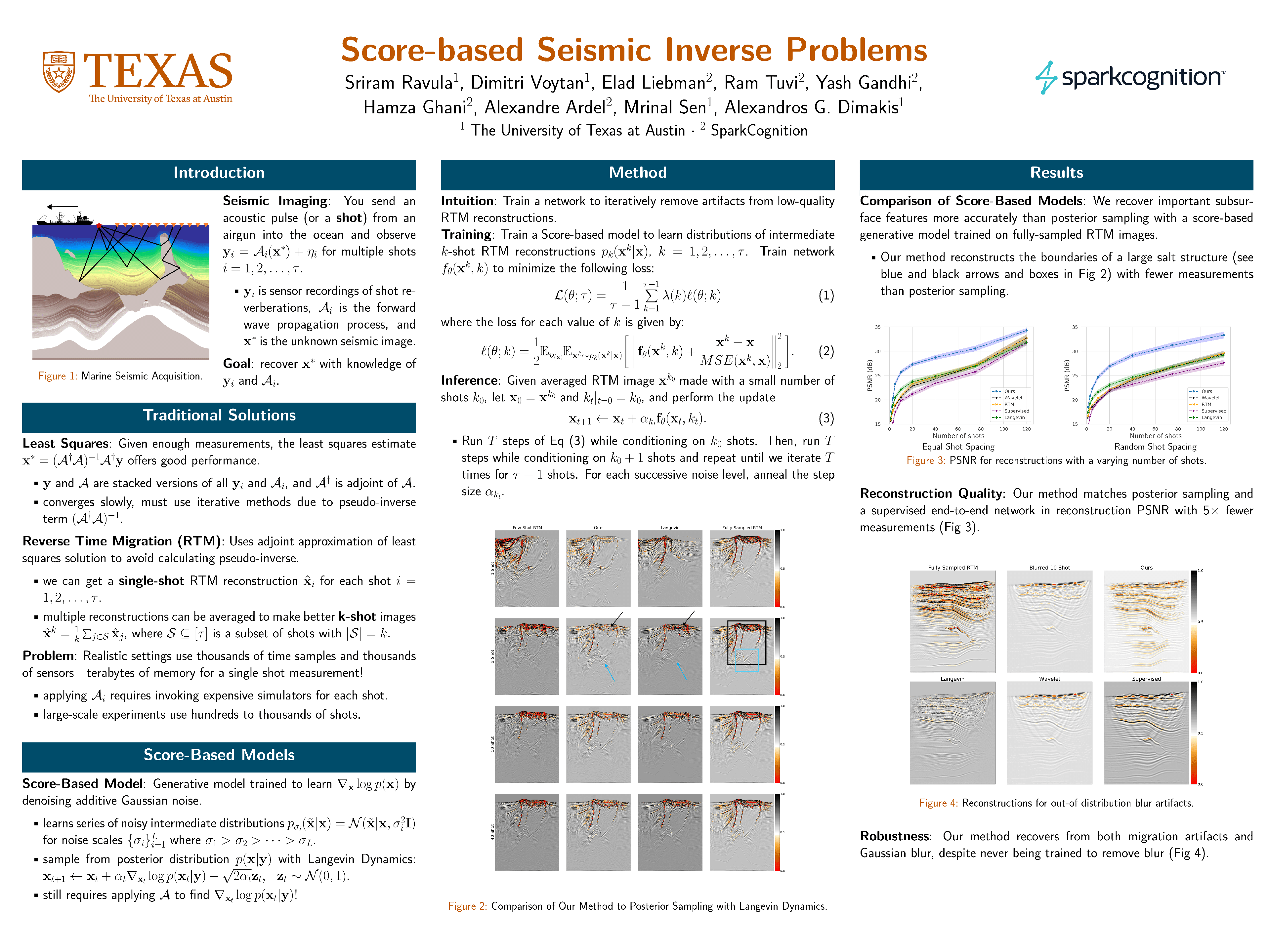
Score-based Seismic Inverse Problems [paper] [poster]
[event]
Ravula,
Sriram*; Voytan, Dimitri P; Liebman, Elad; Tuvi, Ram; Gandhi, Yash; Ghani, Hamza
H ; Ardel, Alexandre; Sen, Mrinal; Dimakis, Alex |
| 158 |
Self-supervised detection of atmospheric phenomena from remotely sensed
synthetic aperture radar imagery [paper] [poster]
[event]
Glaser,
Yannik*; Sadowski, Peter; Stopa, Justin |
| 159 |
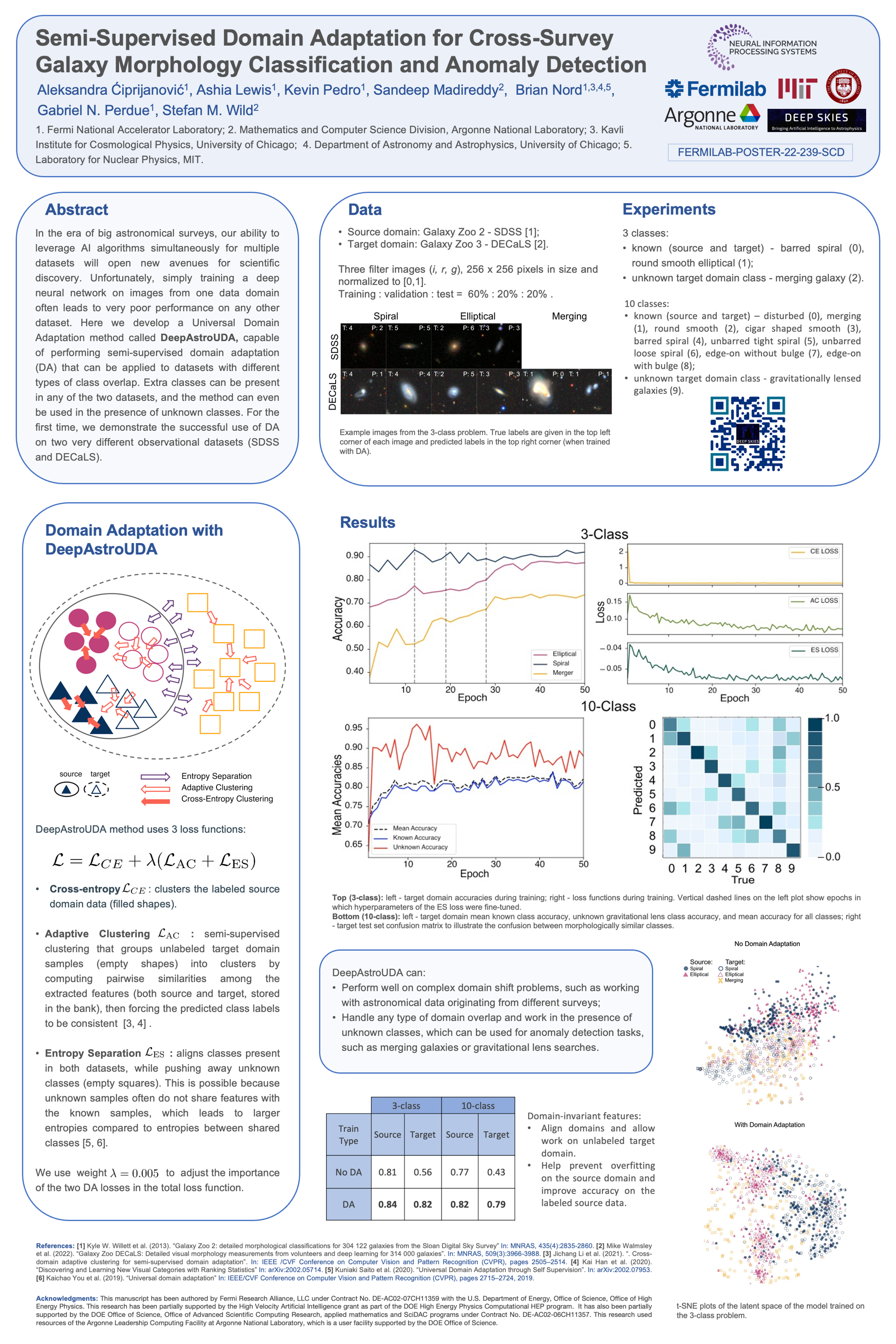
Semi-Supervised Domain Adaptation for Cross-Survey Galaxy Morphology
Classification and Anomaly Detection [paper] [poster]
[event]
Ciprijanovic,
Aleksandra*; Lewis, Ashia; Pedro, Kevin; Madireddy, Sandeep; Nord, Brian;
Perdue, Gabriel Nathan; Wild, Stefan |
| 160 |
Set-Conditional Set Generation for Particle Physics [paper] [poster]
[event]
Ganguly,
Sanmay; Heinrich, Lukas*; Kakati, Nilotpal; Soybelman, Nathalie |
| 161 |
Shining light on data [paper] [poster]
[event]
Kumar,
Akshat*; Sarovar, Mohan |
| 162 |
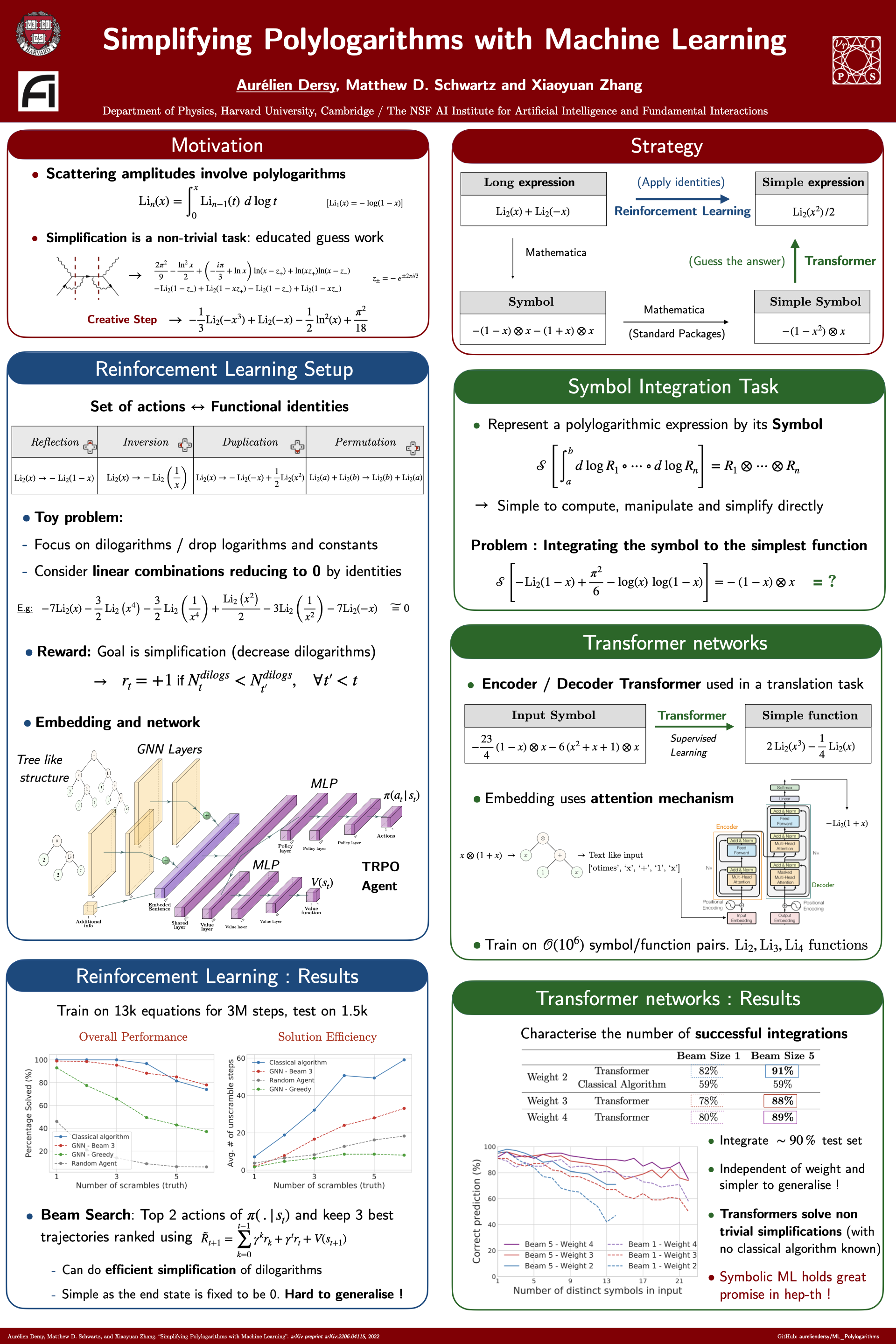
Simplifying Polylogarithms with Machine Learning [paper] [poster]
[event]
Dersy,
Aurelien*; Schwartz, Matthew; Zhang, Xiaoyuan |
| 163 |
Simulation-based inference of the 2D ex-situ stellar mass fraction
distribution of galaxies using variational autoencoders [paper] [poster]
[event]
Angeloudi,
Eirini*; Huertas-Company, Marc; Falcón-Barroso, Jesús; Sarmiento, Regina;
Walo-Martín, Daniel; Pillepich, Annalisa; Vega Ferrero, Jesús |
| 164 |
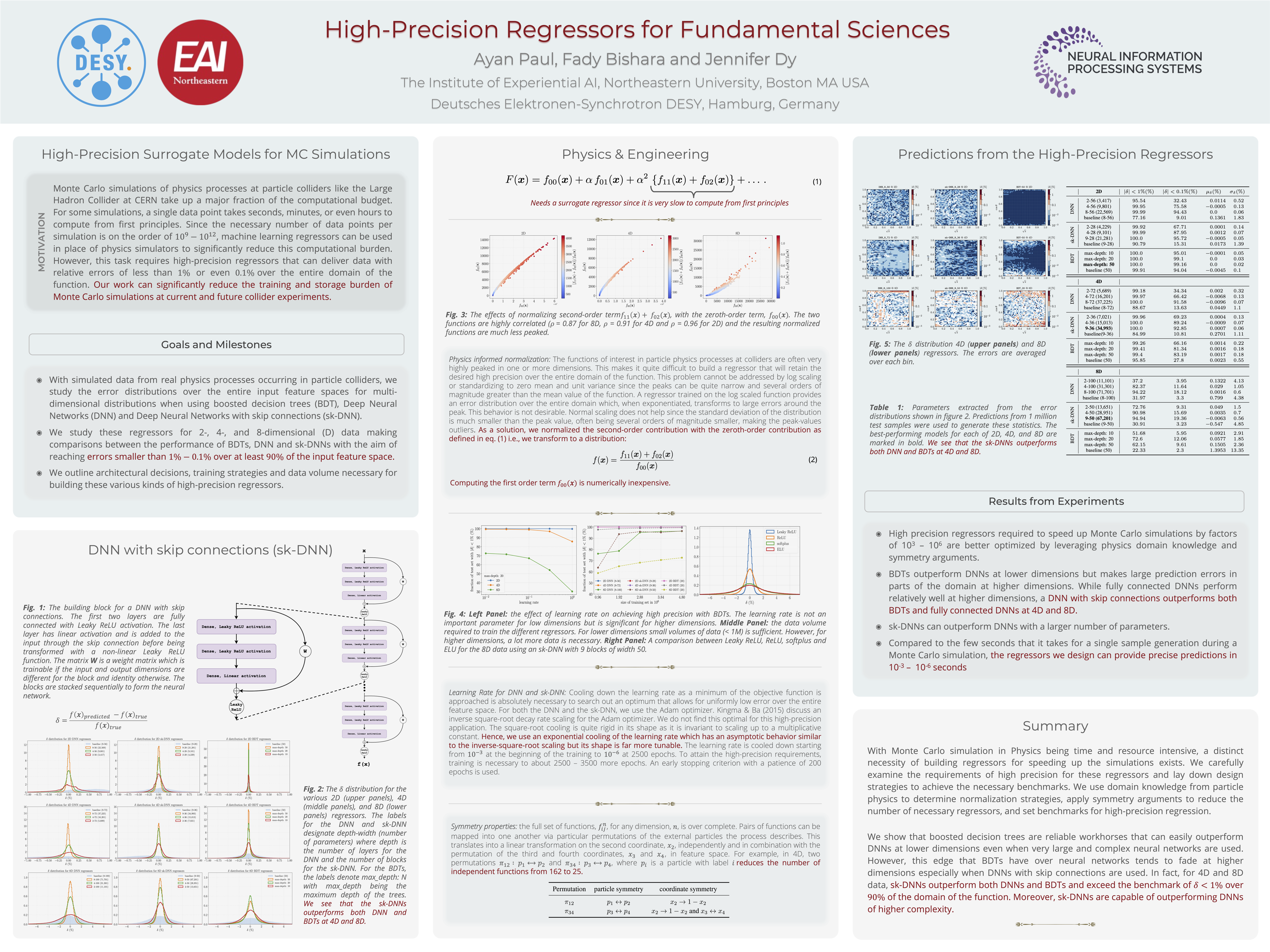
Skip Connections for High Precision Regressors [paper] [poster]
[event]
Paul,
Ayan*; Bishara, Fady; Dy, Jennifer |
| 165 |
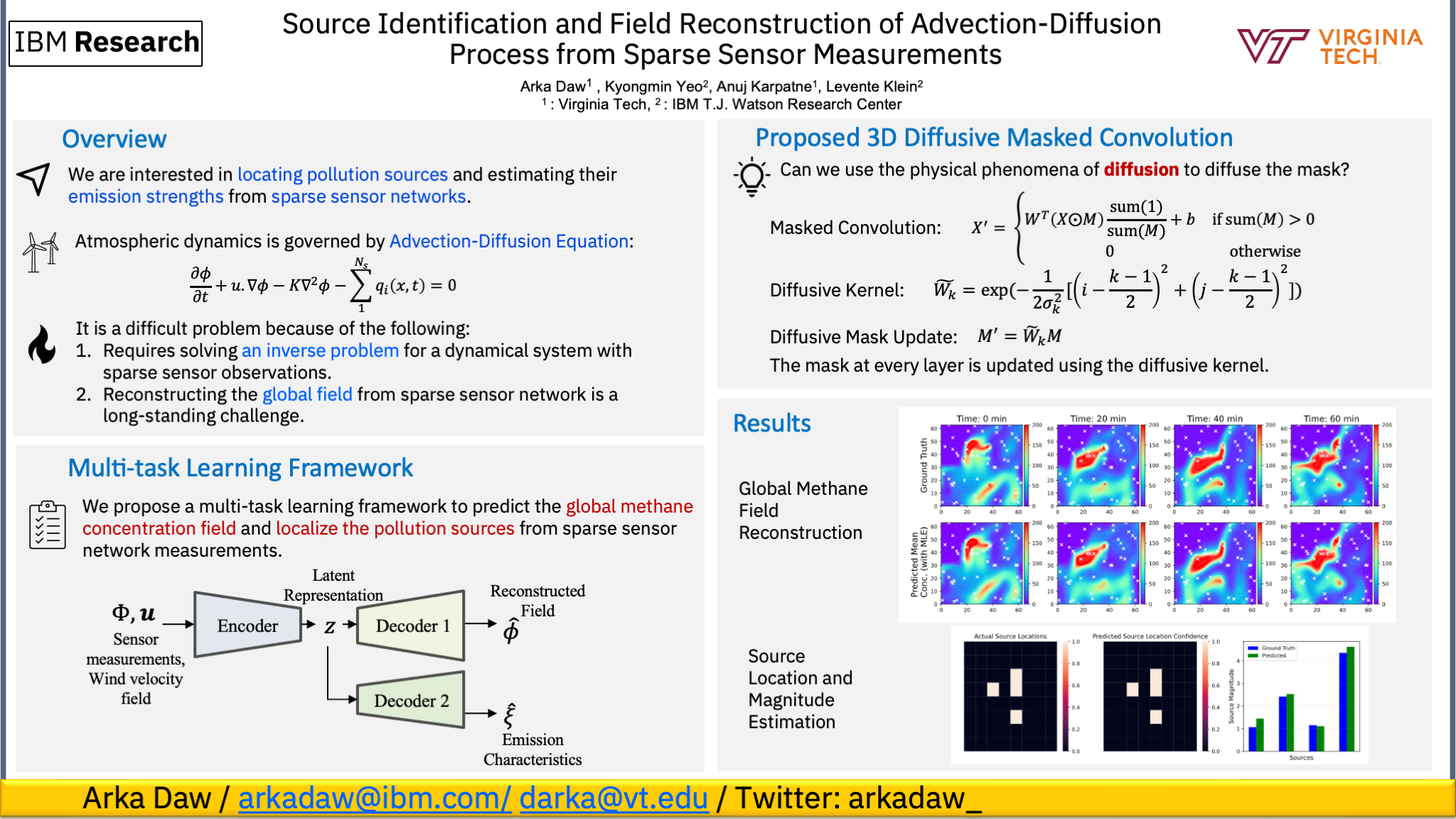
Source Identification and Field Reconstruction of Advection-Diffusion Process
from Sparse Sensor Measurements [paper] [poster]
[event]
Daw, Arka*;
Yeo, Kyongmin; Karpatne, Anuj; Klein, Levente |
| 166 |
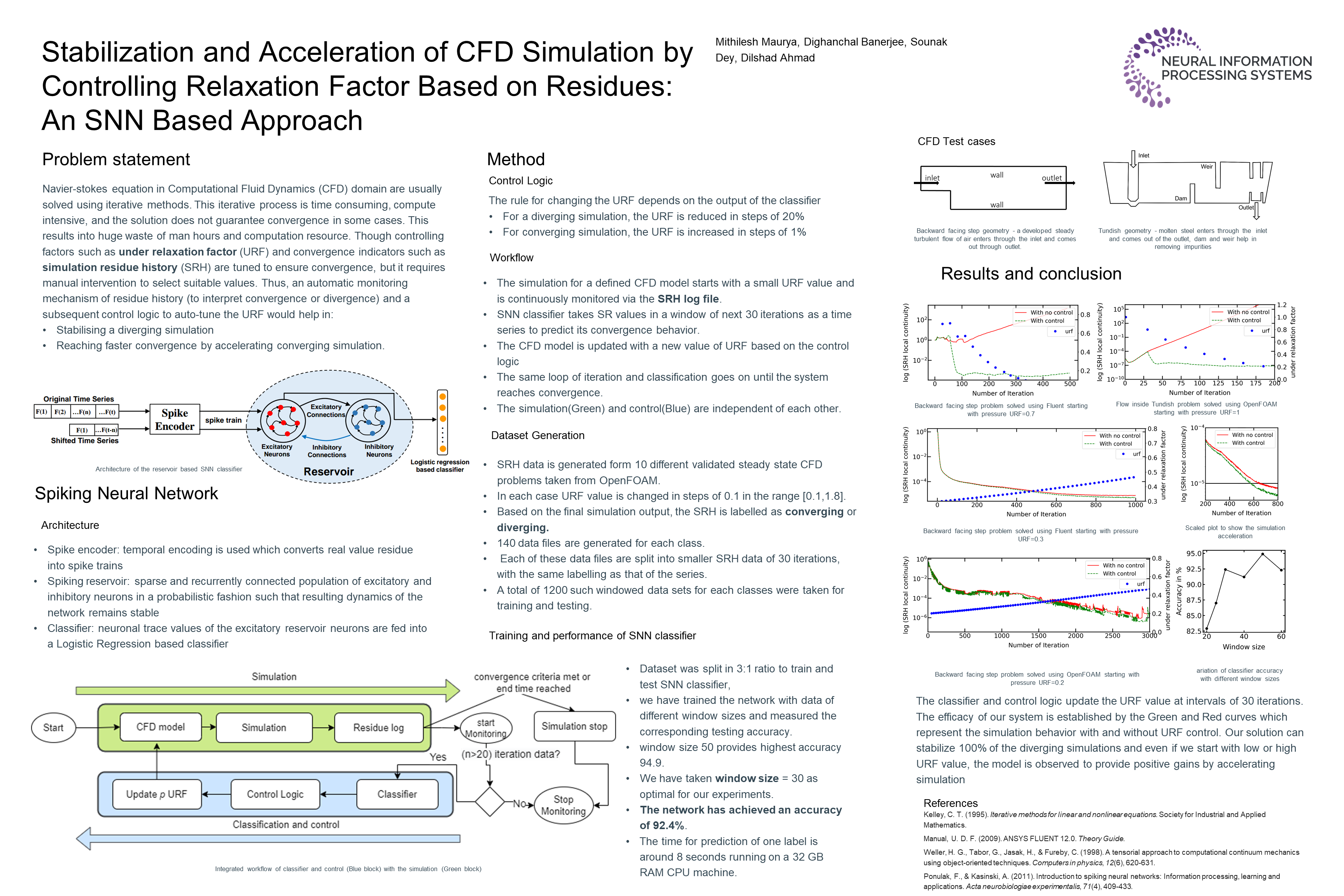
Stabilization and Acceleration of CFD Simulation by Controlling Relaxation
Factor Based on Residues: An SNN Based Approach [paper] [poster]
[event]
Dey,
Sounak*; Banerjee, Dighanchal; Maurya, Mithilesh; Ahmad, Dilshad |
| 167 |
Statistical Inference for Coadded Astronomical Images [paper] [poster]
[event]
Wang,
Mallory; Mendoza, Ismael*; Regier, Jeffrey; Avestruz, Camille; Wang, Cheng |
| 168 |
Strong Lensing Parameter Estimation on Ground-Based Imaging Data Using
Simulation-Based Inference [paper] [poster]
[event]
Poh,
Jason*; Samudre, Ashwin; Ciprijanovic, Aleksandra; Nord, Brian; Frieman, Joshua;
Khullar, Gourav |
| 169 |
Strong-Lensing Source Reconstruction with Denoising Diffusion Restoration
Models [paper] [poster]
[event]
Karchev,
Kosio*; Anau Montel, Noemi; Coogan, Adam; Weniger, Christoph |
| 170 |
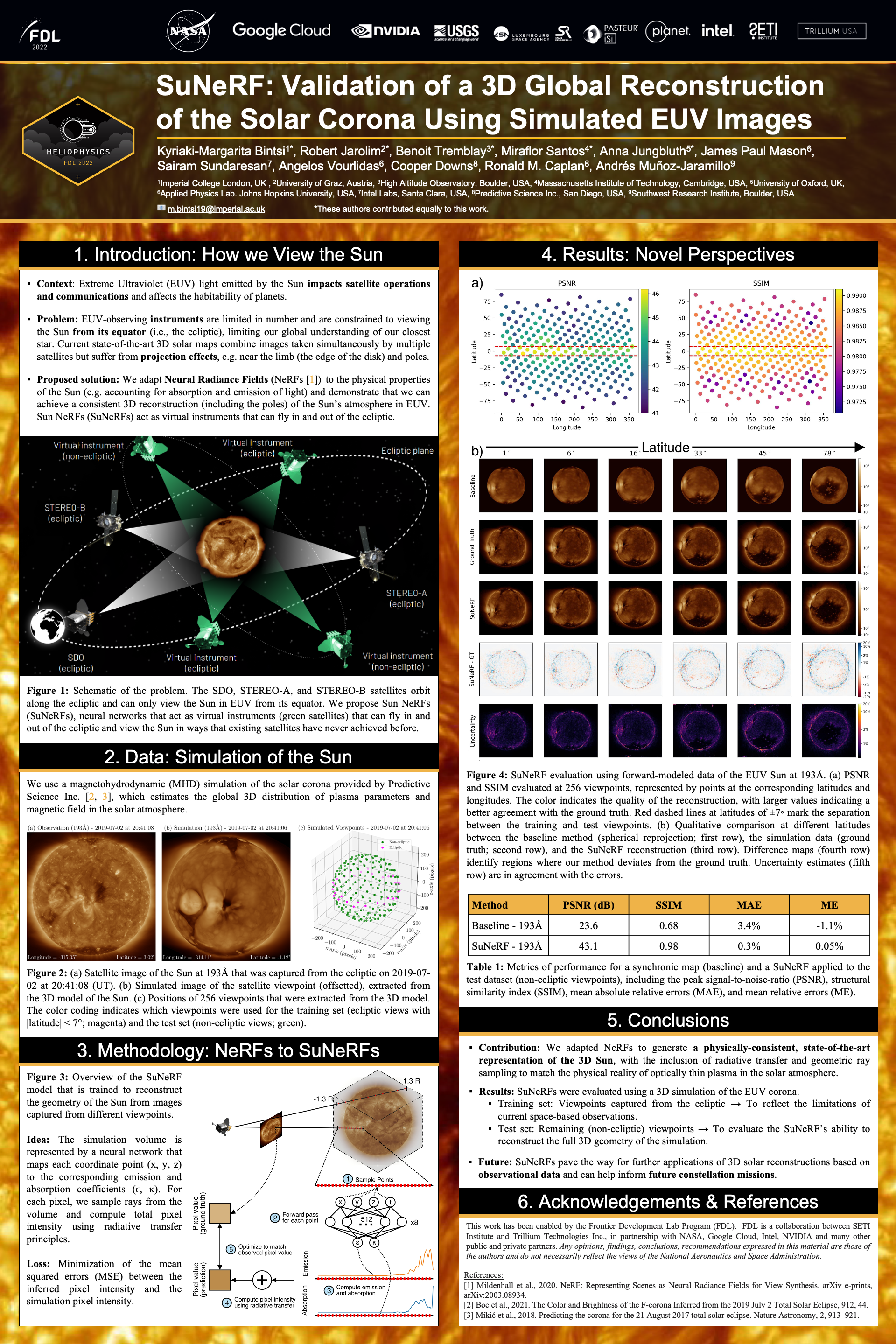
SuNeRF: Validation of a 3D Global Reconstruction of the Solar Corona Using
Simulated EUV Images [paper] [poster]
[event]
Bintsi,
Kyriaki-Margarita*; Jarolim, Robert; Tremblay, Benoit; Santos, Miraflor P;
Jungbluth, Anna; Mason, James; Sundaresan, Sairam; Vourlidas, Angelos; Downs,
Cooper; Caplan, Ronald; Muñoz-Jaramillo, Andrés |
| 171 |
Super-resolving Dark Matter Halos using Generative Deep Learning [paper] [poster]
[event]
Schaurecker,
David*; Li, Yin; Ho, Shirley; Tinker, Jeremy |
| 172 |
Tensor networks for active inference with discrete observation spaces [paper] [poster]
[event]
Wauthier,
Samuel T*; Vanhecke, Bram; Verbelen, Tim; Dhoedt, Bart |
| 173 |
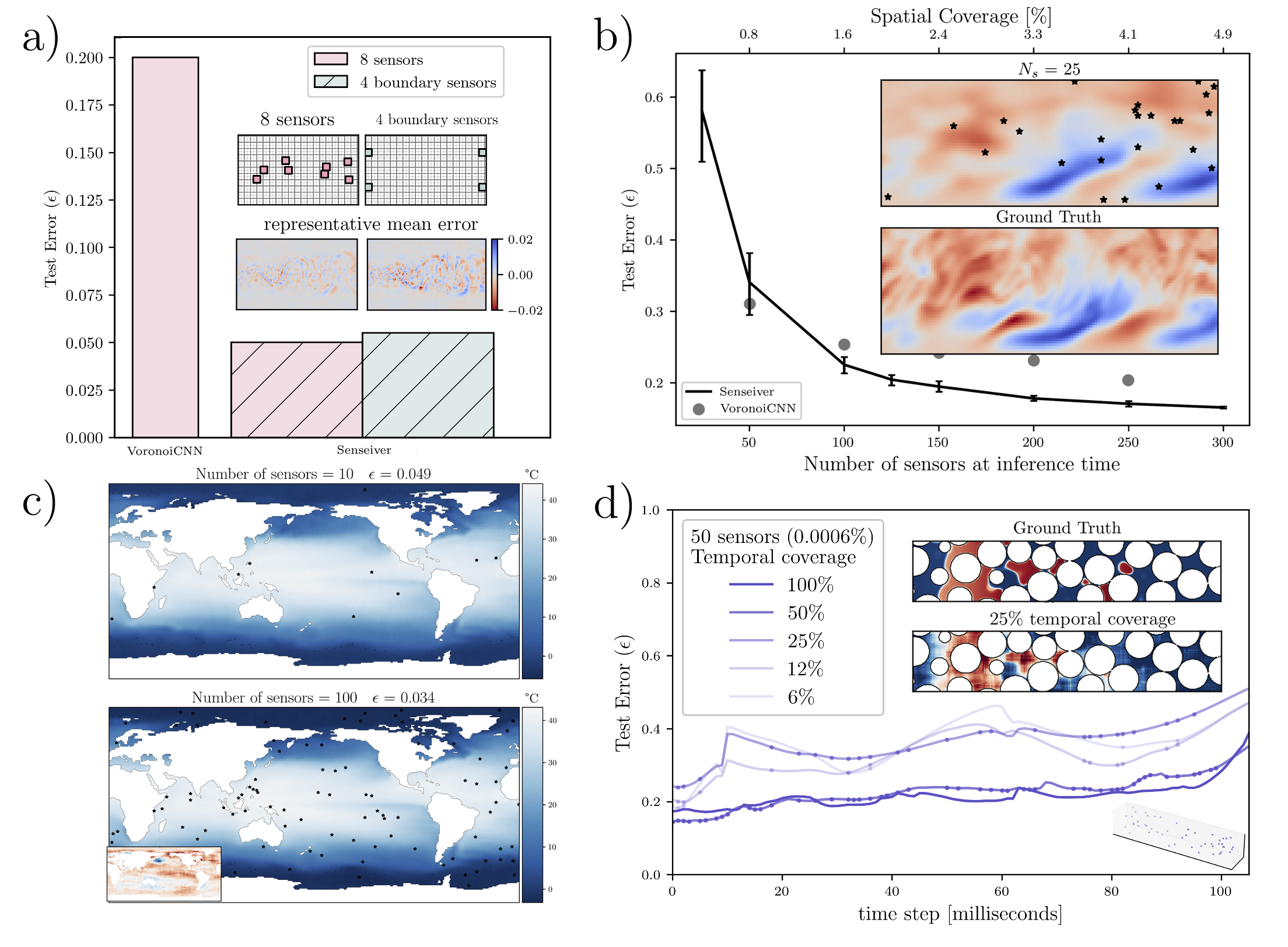
The Senseiver: attention-based global field reconstruction from sparse
observations [paper] [poster]
[event]
Santos,
Javier E*; Fox, Zachary; Mohan, Arvind T; Viswanathan, Hari S; Lubbers, NIcholas
|
| 174 |
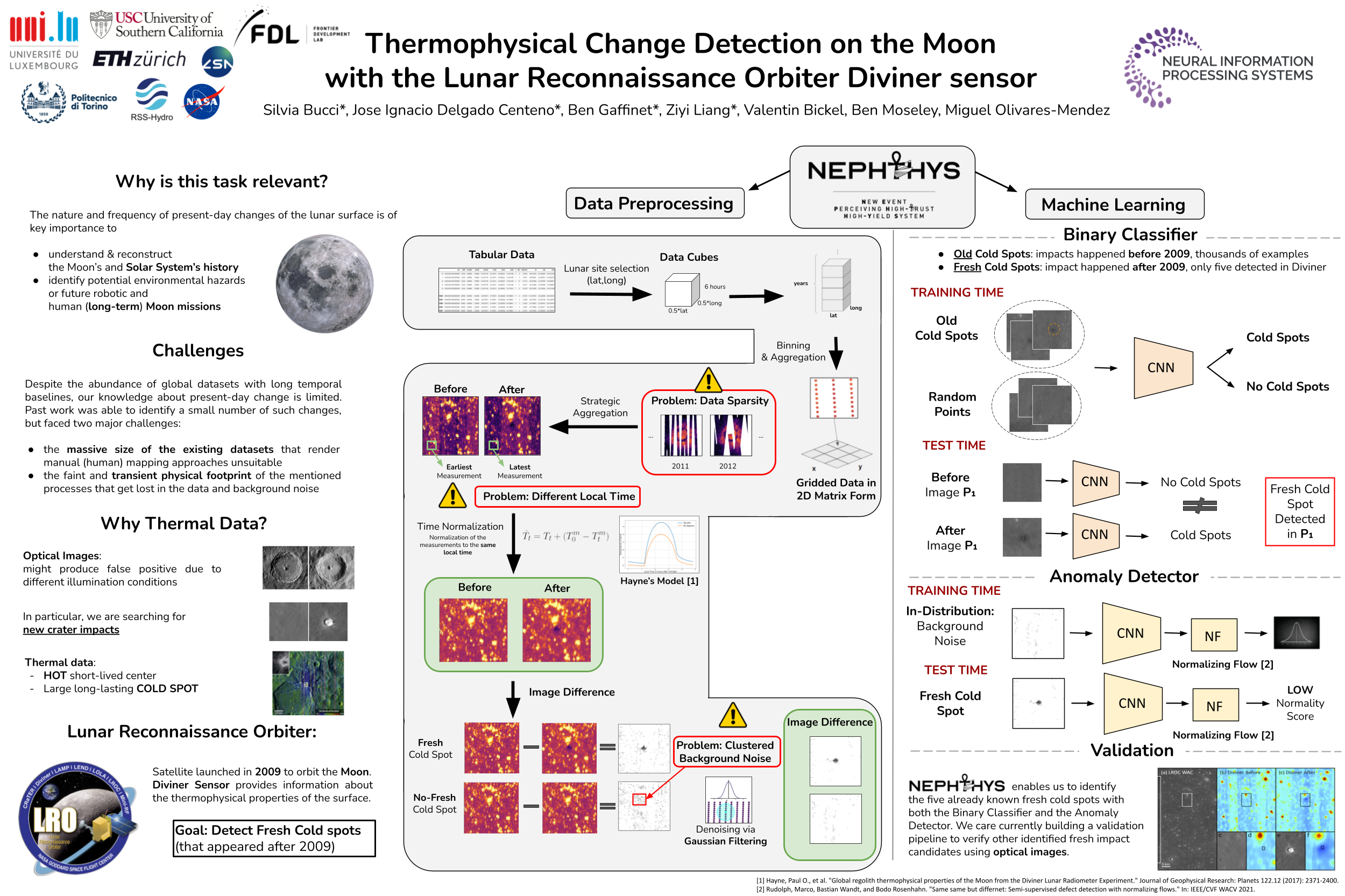
Thermophysical Change Detection on the Moon with the Lunar Reconnaissance
Orbiter Diviner sensor [paper] [poster]
[event]
Delgado-Centeno,
Jose Ignacio*; Bucci, Silvia; Liang, Ziyi; Gaffinet, Ben; Bickel, Valentin T;
Moseley, Ben; Olivares, Miguel |
| 175 |
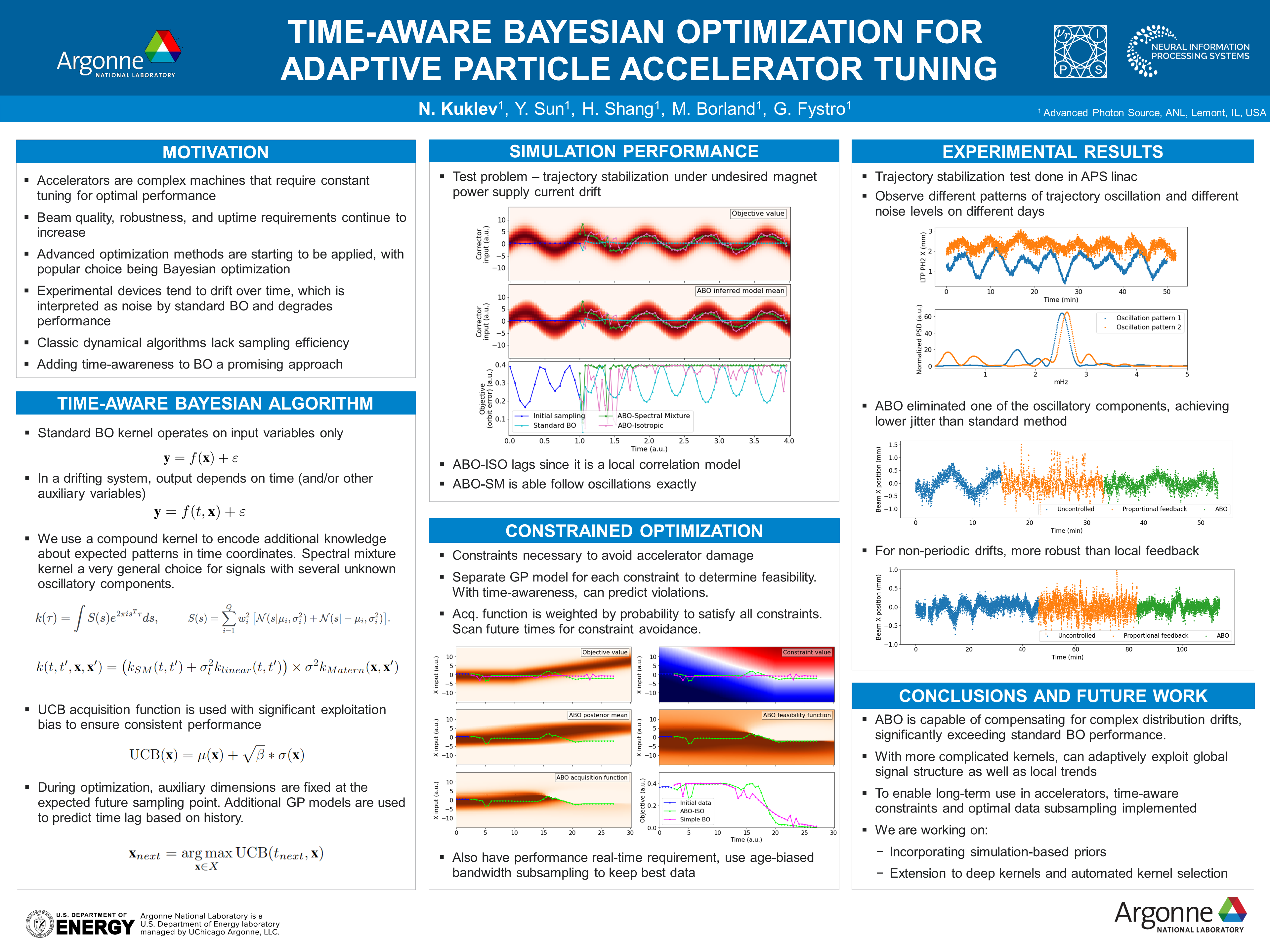
Time-aware Bayesian optimization for adaptive particle accelerator tuning
[paper] [poster]
[event]
Kuklev,
Nikita*; Sun, Yine; Shang, Hairong; Borland, Michael; Fystro, Gregory |
| 176 |
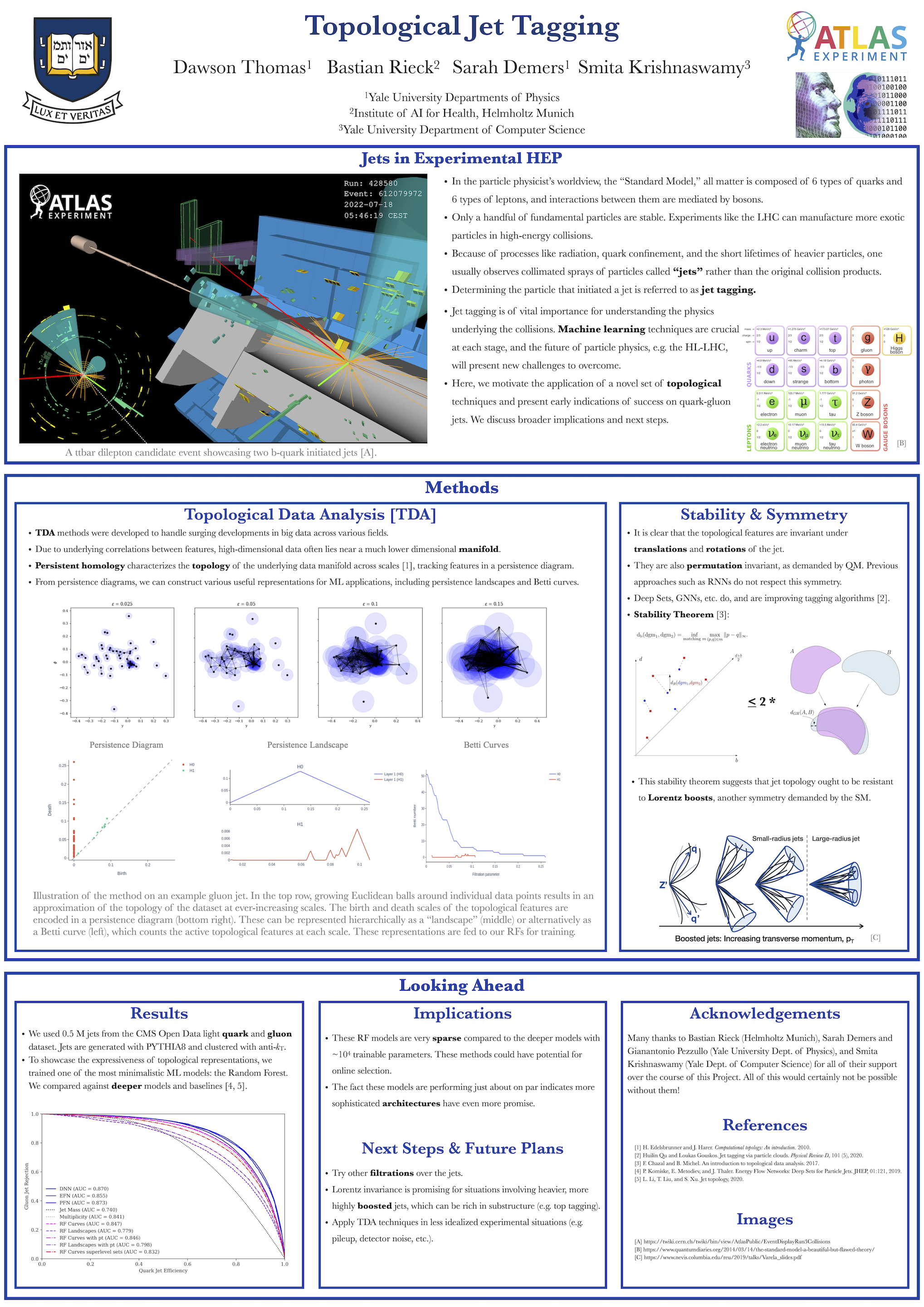
Topological Jet Tagging [paper] [poster]
[event]
Thomas,
Dawson S*; Demers, Sarah; Krishnaswamy, Smita; Rieck, Bastian A |
| 177 |
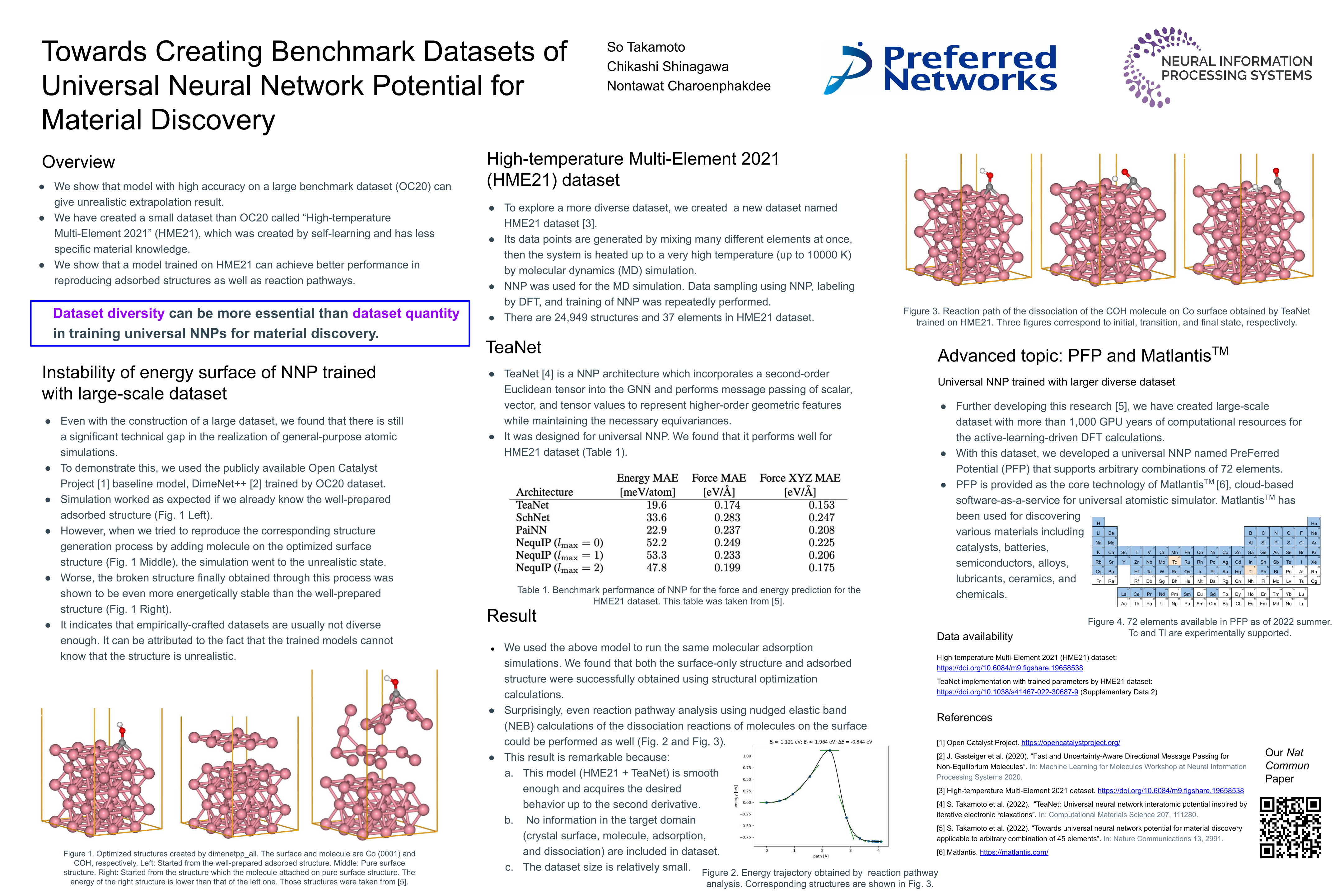
Towards Creating Benchmark Datasets of Universal Neural Network Potential for
Material Discovery [paper] [poster]
[event]
Takamoto,
So*; Shinagawa, Chikashi; Charoenphakdee, Nontawat |
| 178 |
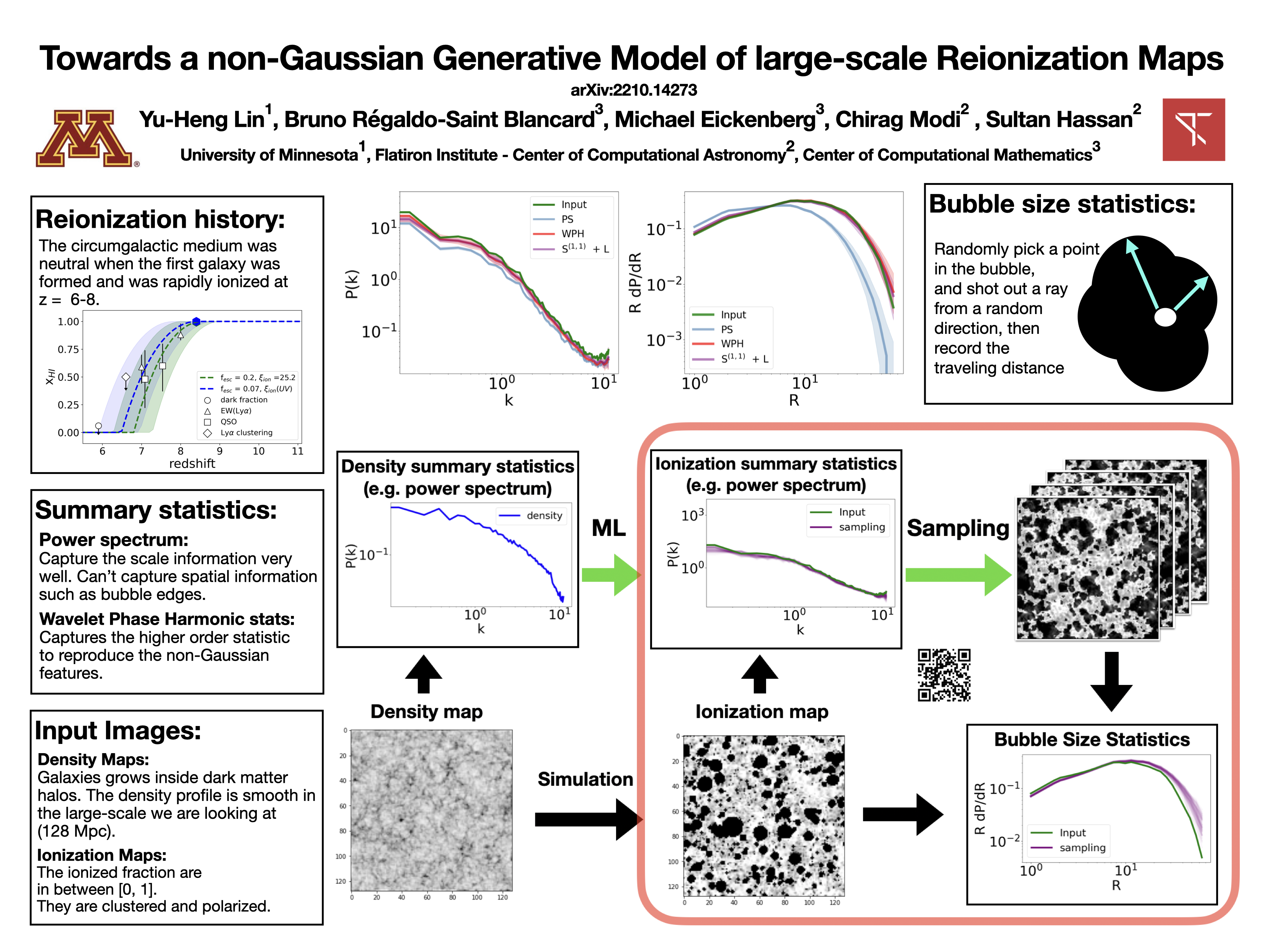
Towards a non-Gaussian Generative Model of large-scale Reionization Maps
[paper] [poster]
[event]
Lin,
Yu-Heng*; Hassan, Sultan SH; Régaldo-Saint Blancard, Bruno; Eickenberg, Michael;
Modi, Chirag |
| 179 |
Towards solving model bias in cosmic shear forward modeling [paper] [poster]
[event]
Remy,
Benjamin*; Lanusse, Francois; Starck, Jean-Luc |
| 180 |
Training physical networks like neural networks: deep physical neural
networks [paper] [poster]
[event]
Wright,
Logan*; Onodera, Tatsuhiro; Stein, Martin; Wang, Tianyu; Schachter, Darren; Hu,
Zoey; McMahon, Peter |
| 181 |
Transfer Learning with Physics-Informed Neural Networks for Efficient
Simulation of Branched Flows [paper] [poster]
[event]
Pellegrin,
Raphael PF*; Bullwinkel, Jeffrey B; Mattheakis, Marios; Protopapas, Pavlos |
| 182 |
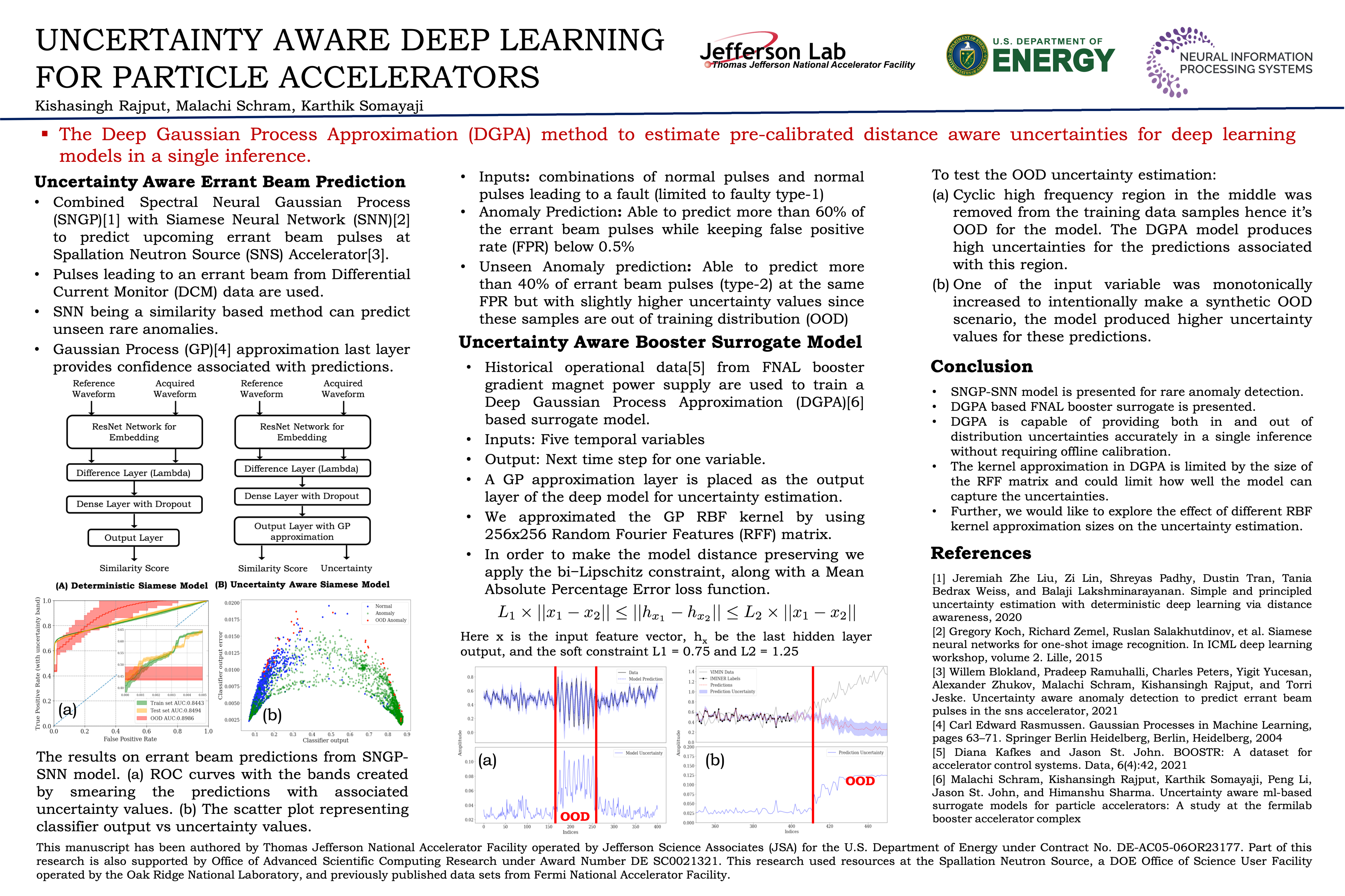
Uncertainty Aware Deep Learning for Particle Accelerators [paper] [poster]
[event]
Rajput,
Kishansingh*; Schram, Malachi; Somayaji, Karthik |
| 183 |
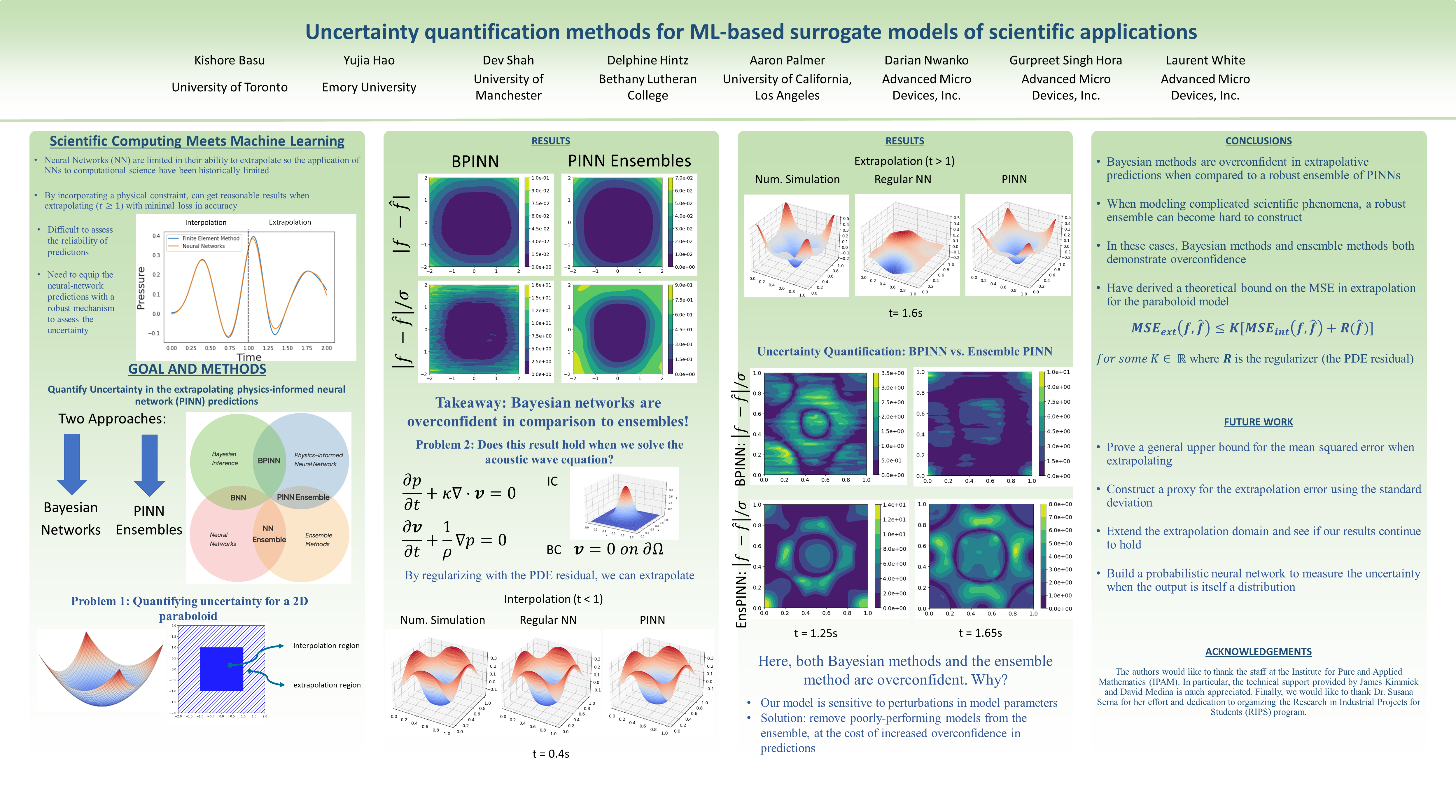
Uncertainty quantification methods for ML-based surrogate models of
scientific applications [paper] [poster]
[event]
Basu,
Kishore; Hao, Judy; Hintz, Delphine ; Shah, Dev; Palmer, Aaron; Hora, Gurpreet
Singh; Nwankwo, Darian; White, Laurent* |
| 184 |
Using Shadows to Learn Ground State Properties of Quantum Hamiltonians
[paper] [poster]
[event]
Tran, Viet
T.*; Lewis, Laura; Kofler, Johannes; Huang, Hsin-Yuan; Kueng, Richard;
Hochreiter, Sepp; Lehner, Sebastian |
| 185 |
Validation Diagnostics for SBI algorithms based on Normalizing Flows [paper] [poster]
[event]
Linhart,
Julia*; Gramfort, Alexandre ; Rodrigues, Pedro |
| 186 |
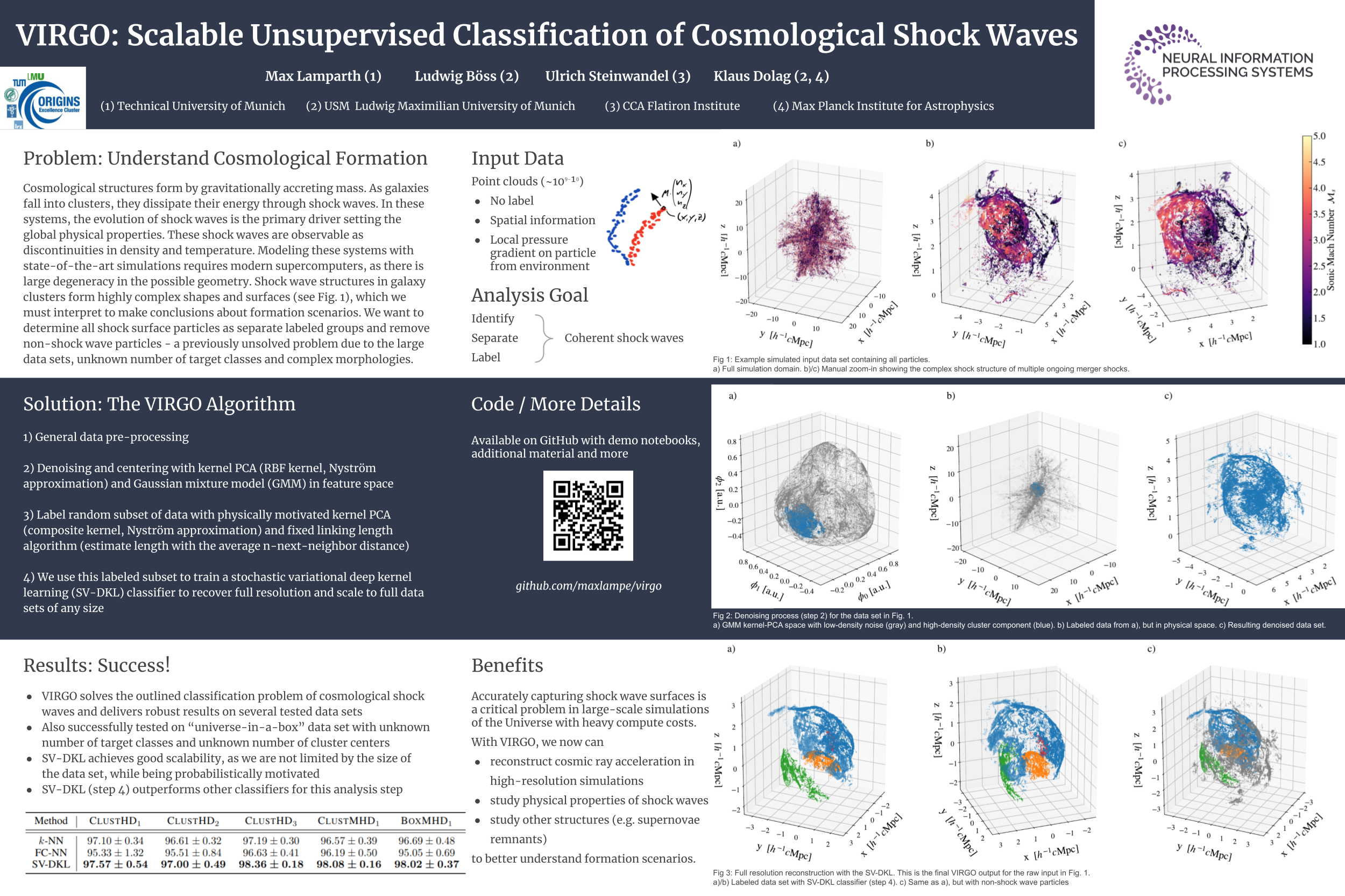
Virgo: Scalable Unsupervised Classification of Cosmological Shock Waves
[paper] [poster]
[event]
Lamparth,
Max*; Böss, Ludwig; Steinwandel, Ulrich; Dolag, Klaus |
| 187 |
Wavelets Beat Monkeys at Adversarial Robustness [paper] [poster]
[event]
Su,
Jingtong*; Kempe, Julia |
| 188 |
Why are deep learning-based models of geophysical turbulence long-term
unstable? [event]
Chattopadhyay,
Ashesh K*; Hassanzadeh, Pedram |
























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}